







(1)Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪则相反,总是尝试匹配尽可能少的字符。
(2)在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
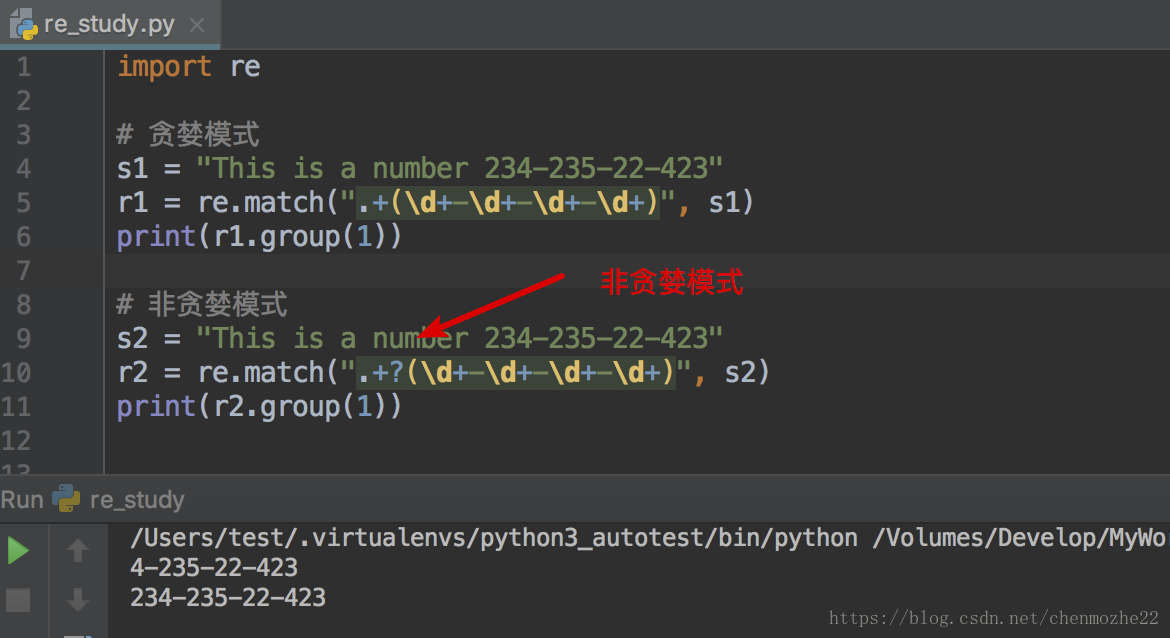
解释:
(1)正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串。
(2)如上案例中,“.+”会从字符串的启始处抓取满足模式的最长字符(This is a number 23)其中包括我们想得到的第一个整型字段的中的大部分.
(3)“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”。
(4)而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











