



实验步骤:
-
卷积神经网络(Convolutional Neural Networks):一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。
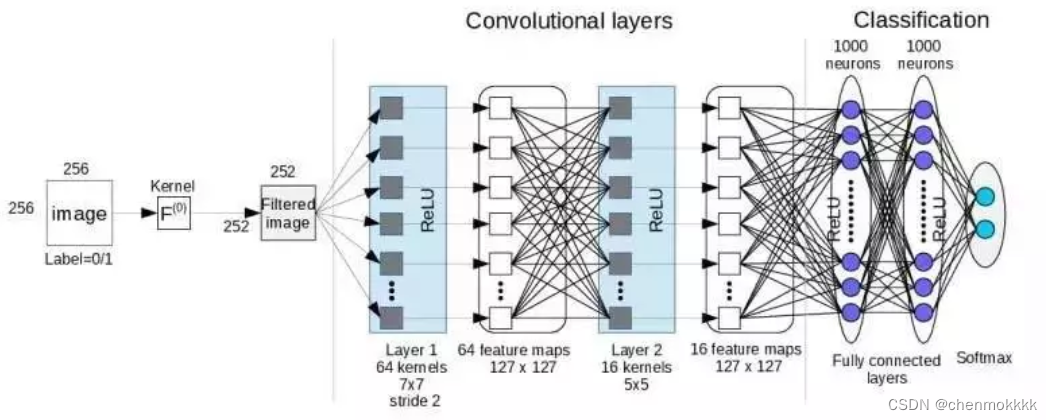
如上图所示,卷积神经网络架构与常规人工神经网络架构非常相似,特别是在网络的最后一层,即全连接。此外,还注意到卷积神经网络能够接受多个特征图作为输入,而不是向量。
2. 理论学习:
一个卷积神经网络主要由以下5层组成:
数据输入层/ Input layer:该层要做的处理主要是对原始图像数据进行预处理
卷积计算层/ CONV layer:这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
ReLU激励层 / ReLU layer:把卷积层输出结果做非线性映射
池化层 / Pooling layer:池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
全连接层 / FC layer:两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。
3. 数据收集:
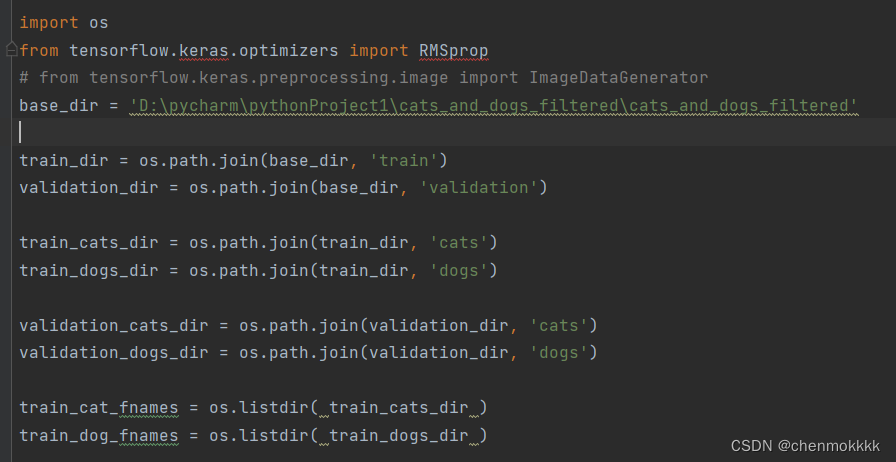
通过tensorflow框架的keras.preprocessing.image获取1000张猫和1000张狗的图片作为训练集,再获取500张狗和500张猫的图片作为验证集。关键代码如下图所示:
4. 数据预处理:
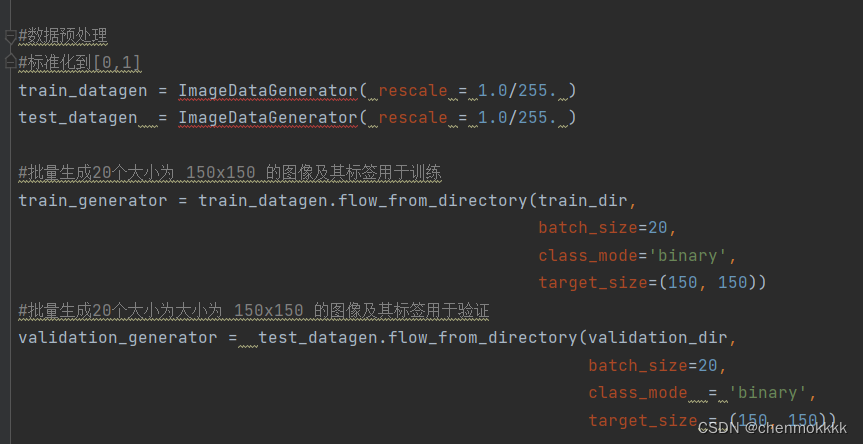
设置数据生成器,它将读取源文件夹中的图片,将它们转换为张量,并将它们以及它们的标签提供给神经网络。所有会得到一个用于训练图像的生成器和一个用于验证图像的生成器。这个生成器将批量生成 20 张大小为 150*150 的图像及其标签。
进入神经网络的数据通常应该以某种方式标准化,以使其更易于被神经网络处理。在我的代码中,通过将像素值归一化为 [0,1] 范围内来预处理我们的图像。关键代码如下图:
5. 算法实现步骤:
- 导入库:
- 导入了TensorFlow库,用于构建和训练深度学习模型。
- 导入了操作系统库(os),用于处理文件路径等操作。
- 导入了RMSprop优化器,用于模型的编译。
- 定义文件路径:
- 定义了训练集和验证集的文件路径,以及猫和狗图片的子目录路径。
- 加载数据:
- 使用os.listdir函数加载了训练集中猫和狗的文件名,并打印了部分文件名和图片数量。
- 构建卷积神经网络模型:
- 使用Sequential模型,顺序地堆叠各层。
- 添加了3个卷积层(Conv2D),每个卷积层后跟一个ReLU激活函数。
- 在每个卷积层后添加了最大池化层(MaxPooling2D)。
- 将图像展平为一维向量(Flatten)。
- 添加了两个全连接层(Dense),分别用于特征提取和分类,最后一层使用Sigmoid激活函数输出分类概率。
- 模型编译:
- 使用RMSprop优化器进行模型编译。
- 损失函数选择了二元交叉熵(binary_crossentropy)。
- 评估指标为准确率(acc)。
- 数据预处理:
- 使用ImageDataGenerator进行数据预处理,将像素值缩放到[0,1]之间。
- 生成数据批次:
- 使用flow_from_directory方法生成训练和验证数据的批次。
- 定义模型检查点:
- 设置保存模型权重的文件路径和目录。
- 创建一个ModelCheckpoint回调,用于在训练过程中保存模型的权重。
- 模型训练:
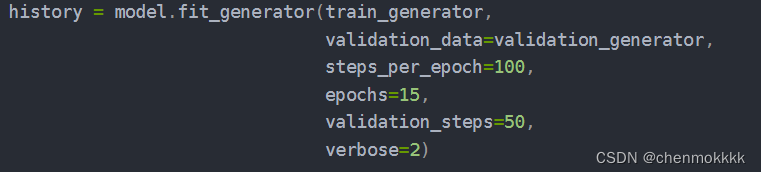
- 调用fit_generator方法进行模型训练。
- 设置训练参数,包括训练数据生成器、验证数据生成器、训练步数、迭代次数、验证步数等。
- 添加模型检查点回调,以便在训练过程中保存模型的权重。
6. **模型训练**:
我们让所有2000张可用图像训练15次,并在所有1000张测试图像上进行验证。
我们持续观察每次训练的值。在每个时期看到4个值——损失、准确度、验证损失和验证准确度。
Loss 和 Accuracy 是训练进度的一个很好的指标。它对训练数据的分类进行猜测,然后根据训练好的模型对其进行计算结果。 准确度是正确猜测的部分。 验证准确度是对未在训练中使用的数据进行的计算。关键代码如下图所示:
7. **模型评估**:
使用训练出来的模型,完成准确率,召回率,f1分数的指标,代码如下图所示: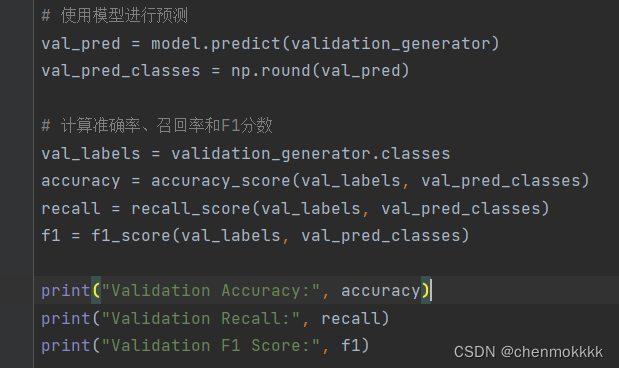
8. **结果分析**:
模型的优点:
- 卷积神经网络(CNN)结构: CNN 在处理图像数据上具有很强的表征学习能力,能够自动提取图像中的特征。
- 数据增强: 使用ImageDataGenerator进行数据增强可以有效地扩充训练数据集,增加模型的泛化能力。
- 模型保存与加载: 使用ModelCheckpoint回调函数可以保存模型的权重,以便在需要时重新加载模型,提高模型的可用性和稳定性。
模型的缺点:
- 过拟合: 当训练数据过少或模型复杂度过高时,容易发生过拟合,导致模型在验证集上的性能下降。
- 训练时间长: 如果数据集较大或者模型复杂度较高,训练时间可能会较长,影响模型的实际应用和迭代优化。
- 验证集性能不佳: 在验证集上的性能(验证准确率等)可能不如训练集,这可能是由于数据分布不均匀或者模型泛化能力不足导致的。
影响模型性能的因素:
- 数据质量和数量: 数据的质量和数量对模型性能有重要影响,高质量和充足的数据可以提高模型的泛化能力。
- 模型复杂度: 模型的复杂度(如网络层数、参数量)会影响模型的拟合能力和泛化能力,需要根据具体任务进行调整。
- 超参数调优: 优化超参数(如学习率、批量大小、优化器)对模型性能至关重要,需要通过实验和调优找到最佳组合。
- 数据增强: 通过数据增强技术可以扩充训练数据集,提高模型的泛化能力,但过度的数据增强也可能导致模型过拟合。
- 正则化: 使用正则化技术(如Dropout、L2正则化)可以减少过拟合,提高模型的泛化能力。
- 模型保存与加载: 保存模型的权重和架构可以帮助在需要时重新加载模型,提高模型的可用性和稳定性。
获取完成代码请加q:1604876016


















 4274
4274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









