



 文章介绍了使用OCR技术和Document-Layout解析方法来处理复杂文档结构,通过Layot-Parser工具识别段落、列表、表格和图像。关键点包括TextEmbedding、VisualEmbedding和LayoutEmbedding,尤其是利用DeBERTa模型处理相对位置信息。此外,提到了数据标注需求,包括图像、宽度、高度和特定内容标签。
文章介绍了使用OCR技术和Document-Layout解析方法来处理复杂文档结构,通过Layot-Parser工具识别段落、列表、表格和图像。关键点包括TextEmbedding、VisualEmbedding和LayoutEmbedding,尤其是利用DeBERTa模型处理相对位置信息。此外,提到了数据标注需求,包括图像、宽度、高度和特定内容标签。
1: 识别文档中文字以及准确的对这些文字排序是必须的一步骤
采用 OCR技术识别文字以及对应的图像坐标信息,光栅扫描以生成输入序列按照从左到右,从上到下的顺序;但是以上方法针对复杂的结构就会出现问题;因此文章使用了Document-Parase方法来解析文档使用的是Layot-Parser工具箱:
···https://github.com/Layout-Parser/layout-parser
基于OCR识别的文字以及对应的坐标,first 识别文档的元素(paragraphs,lists,tables,fugures)然后使用特殊的算法识别所在不同文档元素的字符之间的逻辑关系,从而获得准确的阅读顺序;
Text Embedding.:与正常的bert输入一致不再叙述
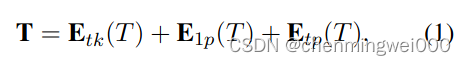
Visual Embedding:
不仔细深究,其实也比较简单,就是把图像resize到224 通过Faseter-Rcnn转化为一个feature-map特征=[W,H,256],实际代码可以使用resnet模型替代,实际代码W==H=7,最终通过flatten以及映射层转化为与text相同维度,然后增加一维positon以及token type embedding
![]()
position embedding就是模型最终输出的feature-map(7*7)对应的位置信息,源代码细看
Layout Embedding.
这是本篇的核心之一,对于每一个字符 增加其对应得坐标信息,转化为对应的embedding加入到字符特征中去,坐标全部转到【0,1000】中去;这个容易理解,但目前有疑问不懂得是visual对应的bbox信息获取,令人费解,谁懂可以在评论告诉我,谢谢;
具体实现如下步骤:
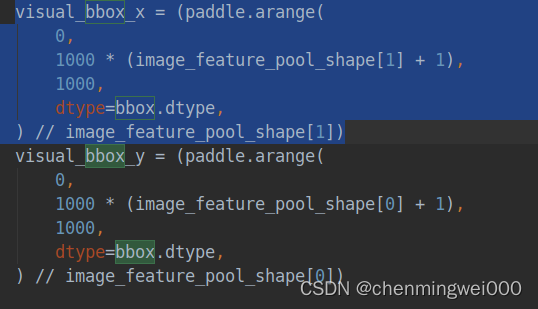
首先以1000为间隔,获取image_feature_pool_shape[1]=7个数列表,
tmp= [0 , 1000, 2000, 3000, 4000, 5000, 6000, 7000]然偶整除获得7的倍数获得结果为:
[0 , 142 , 285 , 428 , 571 , 714 , 857 , 1000]从结果来看,7个x坐标恰巧落在0--1000范围内,所以猜测这样缩放feature-map 7*7 坐标到0-1000范围内,与字符坐标对应。同理visual_bbox_y的取值范围为[0 , 142 , 285 , 428 , 571 , 714 , 857 , 1000],最终通过各种变换把7*7的feature-map坐标映射到0-1000范围内visual_bbox.shape=[2, 49, 4],而 4个数值分别表示每一个feature-map的左上角坐标以及右下角的坐标,为了通俗易懂,举例:first 的feature-map 坐标为 [0 , 0 , 142, 142] ,第二个feature-map坐标为[142, 0 , 285, 142],我们画图来表示这两个位置,大家就理解了
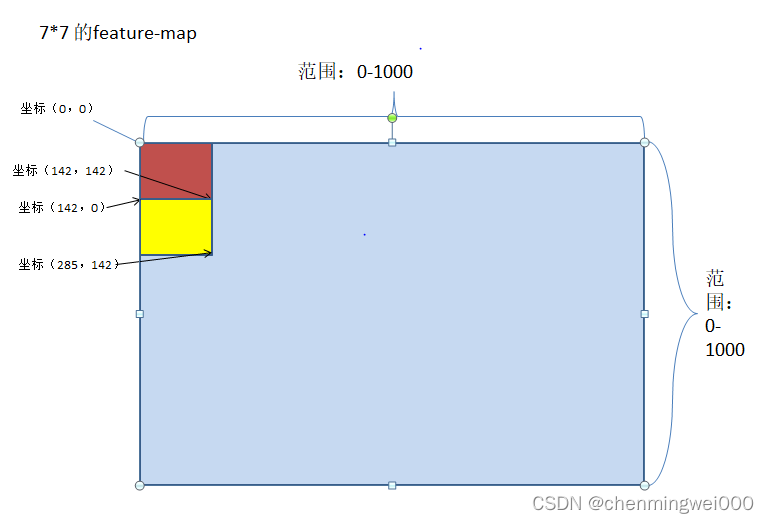
由于我对图像方面相对较弱所以讲解稍微详细写便于理解,正好与所生成的坐标一致,说明理解是正确的。
然后分别把对应的两个坐标信息以及对应的宽高转化为embedding,具体的作者是分别水平的和垂直的信息分别embedding然后相加的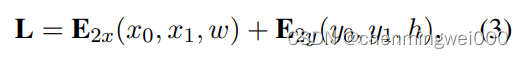
具体代码实现分别把所有整型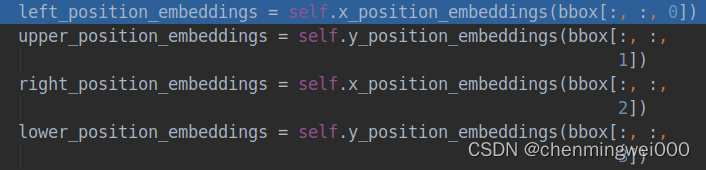 坐标信息映射为hidden-size的embedding
坐标信息映射为hidden-size的embedding
embeddings = visual_embeddings + position_embeddings + x1 + y1 + x2 + y2 + w + h
得到最终的embedding信息;然后把visual的embedding拼接到每一个token对应的embeddeding信息中
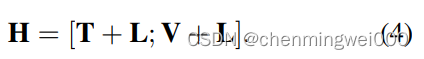
对应的代码为 final_emb = paddle.concat([text_layout_emb, visual_emb], axis=1)
Multi-modal Transformer、
本次模型使用了DeBERTa的相对距离算法,具体的一维为例:
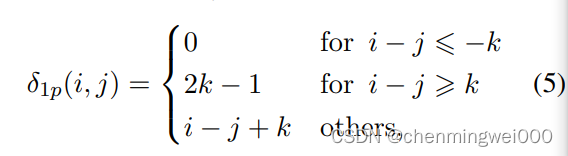
也就是在2k范围内有效,具体的在坐标表示为:
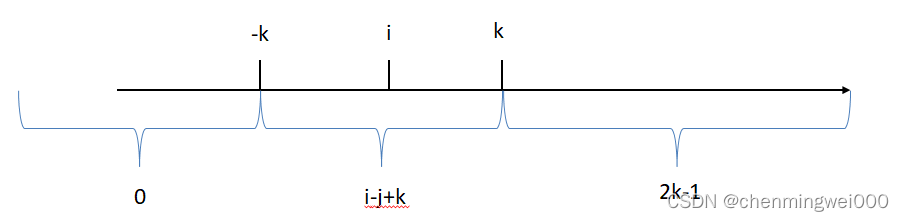
我们引入三个相对position 的embedding表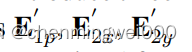 分别表示1Dposition和2D x轴y轴的position,然后映射为相对位置的voctor
分别表示1Dposition和2D x轴y轴的position,然后映射为相对位置的voctor![]()
![]() 在处理attention计算时,把原始的attention的权重分离为4个部分,包含了1D/2D和content特征:
在处理attention计算时,把原始的attention的权重分离为4个部分,包含了1D/2D和content特征:
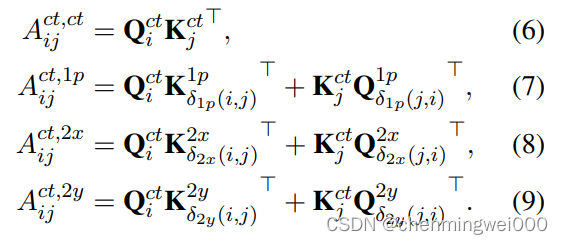
对应的权重scores获取表示为:
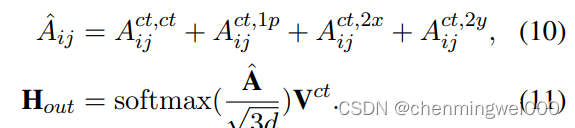
具体实现:
rel_pos_mat = position_ids.unsqueeze(-2) - position_ids.unsqueeze(-1)首先形成相对位置矩阵
relative_position_bucket函数实现起来相对复杂,但是最终实现的结果为公式5,所以可以直接使用函数实现,而不需要知道怎么实现。最终获取相对位置的权重信息,shape-=【batch_size,num_heads,seq_len,seq_len】,相对来说论文模型结构比较不错,很好的融合了文档图像信息。
其中相对位置的矩阵获取函数
def relative_position_bucket(relative_position,
bidirectional=True,
num_buckets=32,
max_distance=128):具体实现说实话有点费解,但最终结果为:
Tensor(shape=[561, 561], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[[0 , 17, 18, ..., 29, 29, 29],
[1 , 0 , 17, ..., 28, 29, 29],
[2 , 1 , 0 , ..., 28, 28, 29],
...,
[13, 12, 12, ..., 0 , 17, 18],
[13, 13, 12, ..., 1 , 0 , 17],
[13, 13, 13, ..., 2 , 1 , 0 ]])从结果来看符合
的规则,因此不再研究具体实现了,反正就是得到相对位置的ids矩阵。由于该实现代码最大相对位置self.rel_pos_bias=32,下一步映射为相对位置的权重,设置了一个可学习的参数self.rel_pos_bias,同理获得字符图片坐标的相对位置权重对应论文中的,其中rel_2d_pos为对应 二位图像坐标的相对坐标位置的权重,与rel_pos的shape相同。这两个输出最终参与attention的操作,具体与论文的公式对应
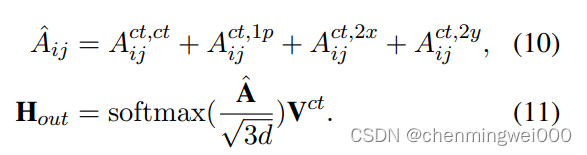
对应代码为:
if self.has_relative_attention_bias:
attention_scores += rel_pos
if self.has_spatial_attention_bias:
attention_scores += rel_2d_pos最终获取到每一个字符对应的类别预测,与正常的实体识别操作一致,不再赘述。
总结:
如果需要训练我们自己的数据,那么数据形式和需要哪些数据如下:
由于超参设定的overwrite_cache=False,所以每次运行需要把/root/.cache/huggingface/datasets/xfund_zh/xfund_zh/1.0.0/605be507733d039d6d0f638e56c7dd4e6ae1b8aad9a52a7ead77ab6cff743bf7路径下的cache文件删除。
image: 整个文档的图片,shape=[3, 224, 224],是图片整个缩放归一化的图片大小;
["width"]: 原始图像的宽
["height"]“: 原始图像的高
对应的question:
['QUESTION', 'ANSWER', 'HEADER'] 表示对应文档中内容的标签,例如那些字符是QUESTION,QUESTION的含义就是文档中key的位置,例如,身份证:410.....,question就是”身份证“,
其中每一个标签包含的内容为:
answer_end :文本内容在ocr识别内容的结束位置
answer_start
text :ocr识别内容
我们只需要标注以上内容即可,其实际需要人标注的就是
['QUESTION', 'ANSWER', 'HEADER']
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









