




某天在排查某个C++软件异常问题时,遇到了一个很大的64位10进制数据18446744071950963590,为了方便排查问题,需要将该10进制数转成16进制的。最开始想到了使用大模型转一下,结果观察下来发现,deepseek、豆包、通义千问和讯飞星火这几个大模型转换都是错的,只有百度的文心一言的转换结果是对的,让人大跌眼镜!
deepseek的转换结果是错的,如下所示:
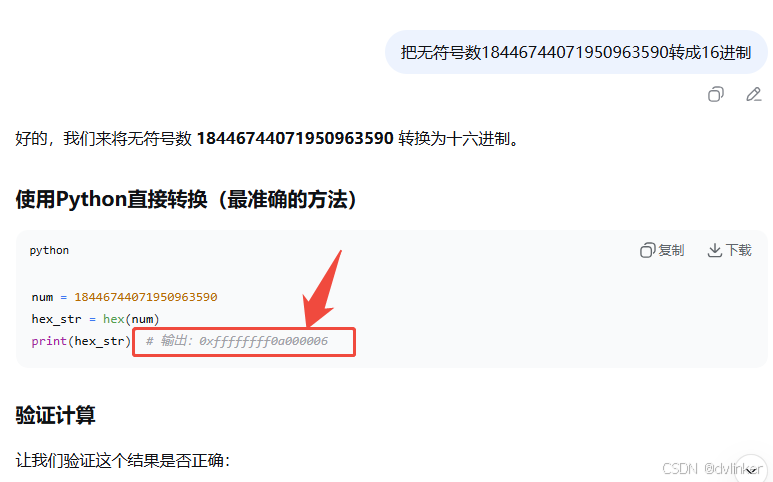
豆包的转换结果也是错的:
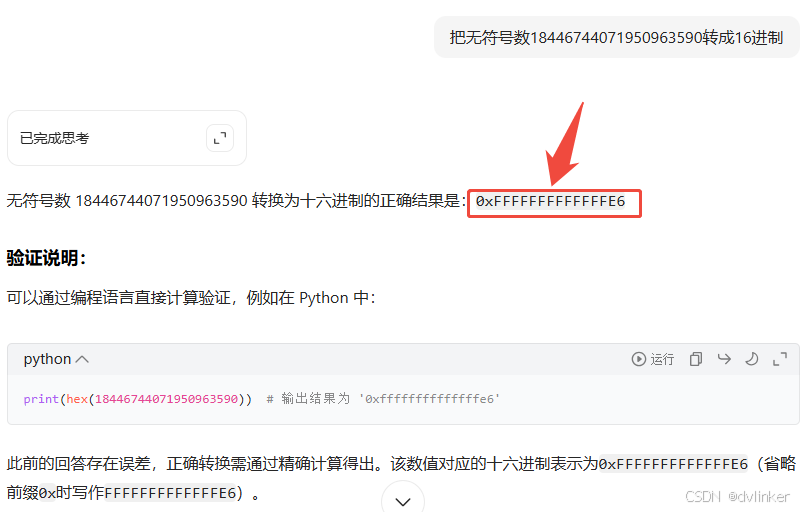
通义千问的错误转换结果:

只有百度的文心一言的转换结果是对的:
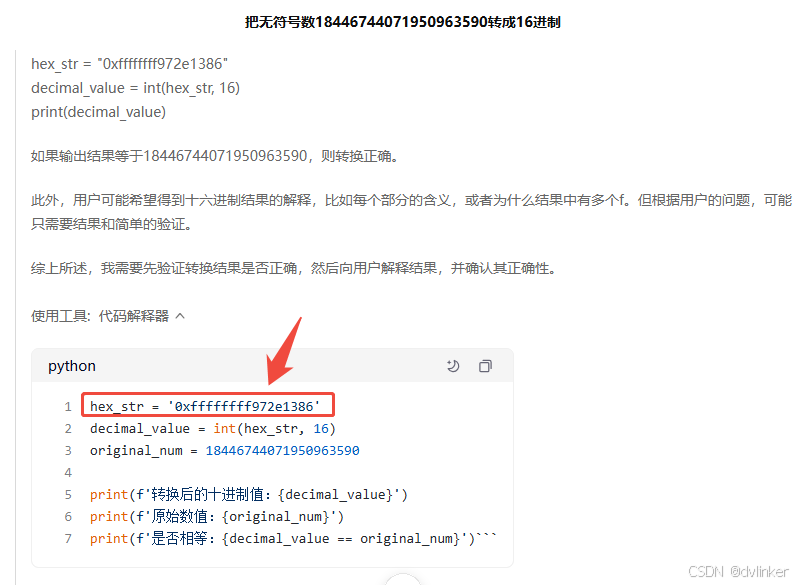
其实要将10进制18446744071950963590转换成16进制,其实很简单,直接将18446744071950963590赋值给一个64位变量,然后再监视窗口中查看其16进制值就可以了,如下:

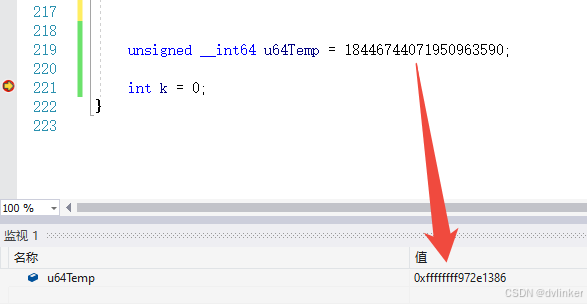
也是通过该方法验证几个大模型转换结果的准确性,结果只有文心一言的转换结果是对的,其他几个大模型居然都是错误!
当然,本文不是在否定大模型,大模型给我们日常工作带来了极大的便利,在我们开发代码遇到难题时大模型可以给我们快速的解答、指导和建议,大模型可以直达要点,比我们到搜索引擎中搜索要高效的多!当我们要实现某个难点功能或者之前没做过的功能时,大模型可以给出高质量的实现源码供我们参考。但有时大模型给出的结果,在准确性和逻辑严密性方面可能存在偏差或者错误,甚至我们在连续追问的场景下给出完全相反的答案,我们要加以辨别。


















 7536
7536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











