




哈工大操作系统实验7 地址映射与共享
该篇文章是哈工大操作系统实验7——地址映射与共享的完成笔记,其中包含了详细的步骤和相关代码,并有截图说明。实验内容都成功通过了,但是因为内容较多,记录中难免会有疏忽,如有发现错误,欢迎大家留言和我联系。
不知不觉又肝了两周多,对Linux0.11内存管理的细节有了更多的理解,欢迎大家一键三连:点赞、关注加收藏,感谢大家的支持。
理论知识
实验内容推荐大家学习对应的视频课程:
- L20 内存使用与分段
- L21 内存分区与分页
- L22 段页结合的实际内存管理
- L23 请求调页内存换入
- L24 内存换出
以及《注释》第5.3.1~5.3.4节Linux内核对内存的管理和使用:介绍了逻辑地址、线性地址和物理地址这些地址的概念,也详细说明了地址翻译的过程。
另外我推荐阅读:
- 《注释》第13章内存管理:更加详细介绍了Linux中内存管理。此外还有linux/mm/memory.c、linux/mm/page.s代码的详细注释。
- 《注释》第12.16节exec.c程序:这章介绍了shell程序是如何执行ls、pwd等命令的,其中change_ldt方法中演示了如何把物理内存映射到进程线性地址的。
- 《UNIX环境高级编程中文第三版》第15.9共享存储:主要介绍了使用内存进行共享的相关函数shmget、shmat、shmdt、shmctl。当然网上也有很多相关教程可供参考,只是如果能系统阅读肯定是更好的。
实验内容:

以下根据实验内容逐步实现。
Bochs调试工具跟踪地址映射
实验内容从6.1~6.7节有说明了这个步骤,照着一步步做下来就可以了。
做完之后才发现其实最本质的目的就是要找出逻辑地址、线性地址和物理地址,关于这个几个地址在《注释》书籍5.3.2章节有介绍,5.3.3有一个图更加生动形象的描述了这个过程:

于是本文就从这个思路出发,分成三步进行实现。和实验内容基本相差无异,只是换了个维度。
- 查找变量i的逻辑地址;
- 查找变量i的线性地址;
- 查找变量i的物理地址。
test.c的代码:
#include <stdio.h>
int i = 0x12345678;
int main(void)
{
printf("The logical/virtual address of i is 0x%08x", &i);
fflush(stdout);
while (i)
;
return 0;
}
查找变量i的逻辑地址
使用Bochs汇编调试功能查找对应的汇编代码,这样就能找到变量i的逻辑地址了。
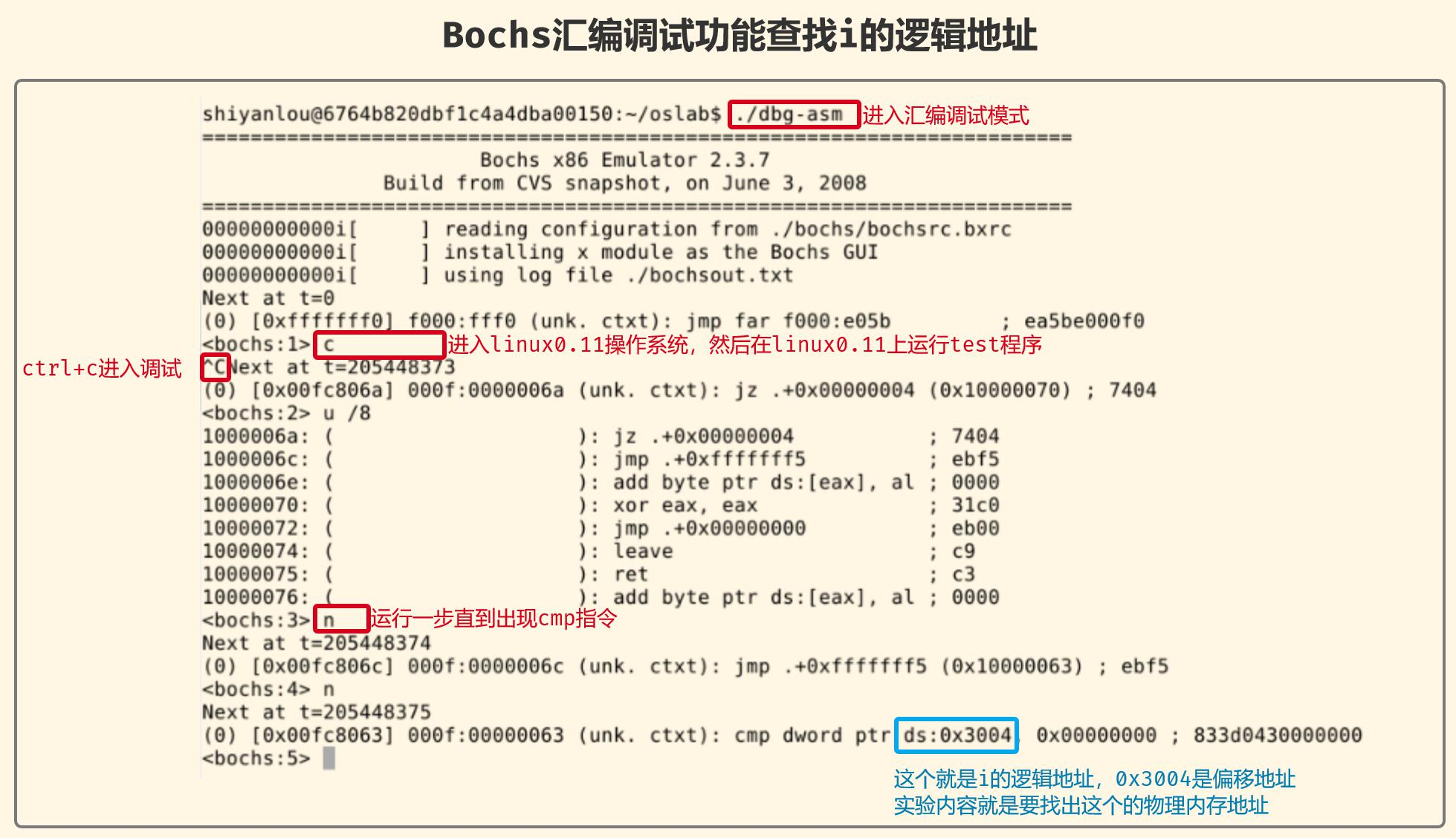
cmp这行汇编代码的意思将 ds:0x3004 存储的值和0进行比较,其实就是 while(i) 这行代码的含义,ds:0x3004 存储的就是i值。
实验中有提到 0x00003004 这个值在任何人的机器上都是一样的,那么为什么呢?
因为 0x00003004 表示了变量i在代码段中的偏移位置,不管在哪个机器上,只要编译器没有变化,编译出来的代码就是一样的,偏移位置自然不会变化。只要在 int i = 0x12345678; 这行代码前加一个变量声明,再试试看能明白了。
#include <stdio.h>
int a = 0; // 新增一个变量声明
int i = 0x12345678;
int main(void)
{
printf("The logical/virtual address of i is 0x%08x", &i);
fflush(stdout);
while (i)
;
return 0;
}
下一步就是要找出 ds:0x3004 这个逻辑地址对应的线性地址。
查找变量i的线性地址
实验内容说明了每一步的流程,具体原理我画了个图,更加容易理解。

在保护模式下,ds存储的是选择子,ds选择子的值为:0x0017=0000000000010111,对应的是LDT表中2号项,因此需要先找出LDT表,然后再定位到2号项。
查找LDT表:思路就是通过ldtr存储的选择子在GDT中找到对应项。

定位到2号项:

根据2号项的值就可以计算出其线性基地址为:0x10000000,加上偏移地址 0x3004 就是线性地址:0x10003004,使用calc进行验证。

下一步就是要找出 0x10003004 这个线性地址对应的物理地址。
查找变量i的物理地址
根据分页基址中线性地址的存储格式,可以算出线性地址中的页目录号、页表号和页内偏移,它们分别对应了 32 位线性地址的 10 位 + 10 位 + 12 位,所以 0x10003004 的页目录号是64,页号3,页内偏移是4。核心原理是这张图:

后面的思路就是查找出页目录项、页表项,最后再通过页内偏移即可得到最终物理地址。
查找出页目录项:

查找出页表项和计算最终物理地址:

最后通过直接修改这个物理内存存储的值进行验证:

Ubuntu上用共享内存做缓冲区
在Linux0.11上实现共享内存前,可以先在Ubuntu上写一个,这样对共享内存的使用就能有一个大概的认识,方便后面在Linux0.11实现共享内存的功能。在编写程序时如能了解内存共享相关的系统调用shmget、shmat、shmdt、shmctl函数,那么大有裨益。这块的知识可以参考《UNIX环境高级编程中文第三版》第15.9共享存储。
共享内存的原理可参考如下图解:

1)实现producer.c
将上一章的程序拿来进行修改,将其中文件相关的部分换成内存即可,参考如下代码。另外还有一点不同就是因为生产者和消费者进行了分离,生产者就没有必要再fork进程了。其他参考代码中的注释。
#include <unistd.h> /* 提供对 POSIX 操作系统 API 的访问,例如 fork(), pipe(), read(), write(), close() 等 */
#include <sys/types.h> /* 提供数据类型,例如 pid_t */
#include <stdio.h> /* 提供输入输出函数,例如 printf() */
#include <stdlib.h> /* 提供通用工具函数,例如 exit(), malloc(), free() */
#include <fcntl.h> /* 提供对文件控制选项的访问,例如 open(), lseek() */
#include <sys/stat.h> /* 提供对文件状态标志和模式的访问(但此代码中未直接使用) */
#include <semaphore.h> /* 提供对 POSIX 信号量的访问,例如 sem_open(), sem_wait(), sem_post(), sem_unlink() */
#include <sys/wait.h> /* 提供等待进程结束的函数,例如 wait(), waitpid() */
#include <sys/ipc.h> /* 包含用于进程间通信(IPC)的接口定义 */
#include <sys/shm.h> /* 包含共享内存(shared memory)相关的接口定义 */
#define M 530 /* 打出数字总数 */
#define N 5 /* 消费者进程数 */
#define AVG M / N /* 每个消费者消费数字平均数 */
#define BUFSIZE 10 /* 缓冲区大小 */
#define SHM_KEY 0x1234 /* 共享内存的key,用来在生产者和消费者进程之间进行识别 */
#define SHM_SIZE 1024 /* 共享内存的大小,实际11就可以了,1024看起来更帅气一些 */
int main()
{
sem_t *empty, *full, *mutex; /* 3个信号量 */
int shm_id; /* 共享内存id */
int *shm_addr; /* 共享内存在当前进程虚拟地址空间的起始地址 */
int i; /* 循环变量和子进程计数器 */
int buf_in = 0; /* 记录上次写入缓冲区位置 */
/* 1. 创建信号量 */
empty = sem_open("empty", O_CREAT | O_EXCL, 0644, BUFSIZE); /* 剩余空间信号量,初始化为 BUFSIZE */
full = sem_open("full", O_CREAT | O_EXCL, 0644, 0); /* 已占用空间信号量,初始化为 0 */
mutex = sem_open("mutex", O_CREAT | O_EXCL, 0644, 1); /* 互斥信号量,初始化为 1 */
/* 2. 创建共享内存段,用于进程间通信 */
shm_id = shmget(SHM_KEY, SHM_SIZE, IPC_CREAT | 0666);
if (shm_id < 0)
{
perror("Fail to shmget!\n");
return -1;
}
shm_addr = (int *)shmat(shm_id, NULL, 0);
if (shm_addr < 0)
{
perror("Fail to shmat!\n");
return -1;
}
/* 3. 生产消息 */
printf("I'm producer. pid = %d\n", getpid());
/* 生产多少个产品就循环几次 */
for (i = 0; i < M; i++)
{
sem_wait(empty); /* empty--,等待有空闲缓冲区, empty>0才能生产 */
sem_wait(mutex); /* mutex--,进入临界区 */
/* 从上次位置继续向共享缓冲区写入一个字符 */
shm_addr[buf_in] = i;
printf("%d: buf_in=%d, shm_addr[buf_in]=%d,\n", getpid(), buf_in, shm_addr[buf_in]);
/* 更新写入缓冲区位置,保证在0-9之间,缓冲区最大为10 */
buf_in = (buf_in + 1) % BUFSIZE;
sem_post(mutex); /* mutex++, 离开临界区 */
sem_post(full); /* full++,增加已占用缓冲区计数 */
}
printf("Producer end.\n");
fflush(stdout); /*确保将输出立刻输出到标准输出。*/
/* 4. 回收 */
/* 回收子进程资源 */
wait(NULL); /* 等待子进程结束 */
/* 使用完毕后,分离共享内存段 */
if (shmdt(shm_addr) == -1)
{
perror("Fail to shmd!\n");
return -1;
}
sleep(1); /* 确保消费者消费完成 */
/* 清理资源(在实际应用中,这通常会在所有进程都完成共享内存的使用后进行) */
shmctl(shm_id, IPC_RMID, NULL);
/* 释放信号量 */
sem_unlink("full");
sem_unlink("empty");
sem_unlink("mutex");
return 0;
}
2)实现consumer.c
同生产者一样拿上章代码进行修改,代码参考如下。和上一章不一样的点:
- 不使用文件,使用共享内存;
- 信号量不再创建,而是直接打开生产者创建的信号量;
另外在进程最后不需要清理共享内存,由生产者进程进行清理即可。
#include <unistd.h> /* 提供对 POSIX 操作系统 API 的访问,例如 fork(), pipe(), read(), write(), close() 等 */
#include <sys/types.h> /* 提供数据类型,例如 pid_t */
#include <stdio.h> /* 提供输入输出函数,例如 printf() */
#include <stdlib.h> /* 提供通用工具函数,例如 exit(), malloc(), free() */
#include <fcntl.h> /* 提供对文件控制选项的访问,例如 open(), lseek() */
#include <sys/stat.h> /* 提供对文件状态标志和模式的访问(但此代码中未直接使用) */
#include <semaphore.h> /* 提供对 POSIX 信号量的访问,例如 sem_open(), sem_wait(), sem_post(), sem_unlink() */
#include <sys/wait.h> /* 提供等待进程结束的函数,例如 wait(), waitpid() */
#include <sys/ipc.h> /* 包含用于进程间通信(IPC)的接口定义 */
#include <sys/shm.h> /* 包含共享内存(shared memory)相关的接口定义 */
#define M 530 /* 打出数字总数 */
#define N 5 /* 消费者进程数 */
#define AVG M / N /* 每个消费者消费数字平均数 */
#define BUFSIZE 10 /* 缓冲区大小 */
#define SHM_KEY 0x1234 /* 共享内存的key,用来在生产者和消费者进程之间进行识别 */
#define SHM_SIZE 1024 /* 共享内存的大小,实际11就可以了,1024看起来更帅气一些 */
int main()
{
sem_t *empty, *full, *mutex; /* 3个信号量 */
int shm_id; /* 共享内存id */
int *shm_addr; /* 共享内存在当前进程虚拟地址空间的起始地址 */
int i, j, k, child; /* 循环变量和子进程计数器 */
int data; /* 读取的数据 */
pid_t pid; /* 进程id */
int buf_out = 0; /* 记录上次从缓冲区读取位置 */
/* 1. 打开已存在的信号量 */
empty = sem_open("empty", O_RDWR); /* 打开empty信号量 */
full = sem_open("full", O_RDWR); /* 打开full信号量 */
mutex = sem_open("mutex", O_RDWR); /* 打开mutex信号量 */
/* 2. 创建共享内存段,该内存段SHM_KEY和生产者进程一样,标识同一个内存段 */
shm_id = shmget(SHM_KEY, SHM_SIZE, IPC_CREAT | 0666);
if (shm_id < 0)
{
perror("Fail to shmget!\n");
return -1;
}
shm_addr = (int *)shmat(shm_id, NULL, 0);
if (shm_addr < 0)
{
perror("Fail to shmat!\n");
return -1;
}
/* 3. 消费者进程,一共创建N个消费者进程 */
for (j = 0; j < N; j++)
{
pid = fork();
if (pid < 0) /* 创建进程失败 */
{
perror("Fail to fork!\n");
return -1;
}
else if (pid == 0)
{
/* 每个进程平均读取数字,即每个进程读取 M/N 个数字 */
for (k = 0; k < AVG; k++)
{
/* full大于0,才能消费 */
sem_wait(full); /* full--, 等待有数据可读 */
sem_wait(mutex); /* mutex--,进入临界区 */
/* 从文件第11个位置获得上次读取位置 */
buf_out = shm_addr[BUFSIZE];
/* 从上次读取位置继续读取数据 */
data = shm_addr[buf_out];
/* 在文件第11个位置写入下次应读取位置 */
buf_out = (buf_out + 1) % BUFSIZE;
shm_addr[BUFSIZE] = buf_out;
printf("%d: %d\n", getpid(), data); /* 打印消费者进程 ID和消费的数据 */
fflush(stdout); /* 确保数据送到终端 */
sem_post(mutex); /* mutex++,离开临界区 */
sem_post(empty); /* empty++,增加空闲缓冲区计数 */
}
printf("Child-%d: pid = %d end.\n", j, getpid());
return 0;
}
}
/* 4. 回收 */
/* 回收子进程资源 */
child = N; /* 包括生产者在内的子进程总数 */
while (child--) /* 等待所有子进程结束 */
wait(NULL); /* 等待子进程结束 */
/* 使用完毕后,分离共享内存段 */
if (shmdt(shm_addr) < 0)
{
perror("Fail to shmd!\n");
return -1;
}
/* 释放信号量 */
sem_unlink("full");
sem_unlink("empty");
sem_unlink("mutex");
return 0;
}
3)编译程序
$ gcc -o producer producer.c -lpthread
$ gcc -o consumer consumer.c -lpthread
4)运行程序
运行生产者程序:
$ ./producer > producer.txt
运行后,会发现生产者进程卡住了,因为生产者生产了10个内容,empty=0了,正在等待消费者进程进行消费。
另外起一个终端运行消费者程序:
$ ./consumer > consumer.txt
此时生产者和消费者都会运行结束,查看producer.txt和consumer.txt的内容:
生产者日志:
# 以下是producer.txt的内容
I'm producer. pid = 1287
1287: buf_in=0, shm_addr[buf_in]=0,
1287: buf_in=1, shm_addr[buf_in]=1,
1287: buf_in=2, shm_addr[buf_in]=2,
1287: buf_in=3, shm_addr[buf_in]=3,
1287: buf_in=4, shm_addr[buf_in]=4,
1287: buf_in=5, shm_addr[buf_in]=5,
1287: buf_in=6, shm_addr[buf_in]=6,
1287: buf_in=7, shm_addr[buf_in]=7,
1287: buf_in=8, shm_addr[buf_in]=8,
1287: buf_in=9, shm_addr[buf_in]=9,
1287: buf_in=0, shm_addr[buf_in]=10,
1287: buf_in=1, shm_addr[buf_in]=11,
1287: buf_in=2, shm_addr[buf_in]=12,
1287: buf_in=3, shm_addr[buf_in]=13,
1287: buf_in=4, shm_addr[buf_in]=14,
1287: buf_in=5, shm_addr[buf_in]=15,
1287: buf_in=6, shm_addr[buf_in]=16,
...
1287: buf_in=6, shm_addr[buf_in]=526,
1287: buf_in=7, shm_addr[buf_in]=527,
1287: buf_in=8, shm_addr[buf_in]=528,
1287: buf_in=9, shm_addr[buf_in]=529,
Producer end.
消费者日志:
# 以下是consumer.txt的内容
1289: 0
1290: 1
1290: 2
1289: 3
1289: 4
1291: 5
1293: 6
1293: 7
1289: 8
1290: 9
1291: 10
1292: 11
1293: 12
1293: 13
1289: 14
1291: 15
1292: 16
...
Child-0: pid = 1289 end.
1292: 483
...
1290: 494
1291: 495
Child-4: pid = 1293 end.
1292: 496
...
1291: 525
Child-3: pid = 1292 end.
1291: 526
Child-1: pid = 1290 end.
1291: 527
1291: 528
1291: 529
Child-2: pid = 1291 end.
实验内容的输出和上一章节大同小异,不再进行赘述。
Linux0.11增加共享内存功能
终于Ubuntu上成功将生产者和消费者改成了共享内存,这下也了解了共享内存的玩法,这下可以考虑如何在Linux0.11上实现了。根据实验的提示开始编写共享内存相关函数的系统调用。
实现shm.c
先实现关键的内核函数,这里只实现了 shmget 和 shmat 两个函数,没有实现 shmdt 和 shmctl 函数,对于实验来讲已经足够了,有兴趣可自行实现。
shmget函数:这个函数比较简单,就是在内核维护一个共享内存的结构体(shm_tables)数组。
- 然后根据参数key判断共享内存在数组是否存在,如果存在则直接返回数组中对应的索引i;
- 如果不存在则申请物理页(get_free_page函数),构建一个结构体加入到数组中,并返回索引。
shmat函数:这个函数代码不多,但是要比shmget难理解,主要的点是在在于逻辑(虚拟)地址和线性地址区分,我一开始也是搞得有点迷糊,后面打印一些内容输出后终于明白了。
- put_page函数是将共享内存附加到进程的线性地址。(在运行中一般是输出0x10005000这个地址,这个是线性地址)
- 返回的是共享内存在当前进程的逻辑(虚拟)地址。(在运行中一般是输出0x5000这个地址,这个是逻辑(虚拟)地址)
关键的原理可以参考这张图:

一个简单的例子:
start_code: 0x10000000,这个是进程的线性起始地址。
长度brk: 0x5000
put_page共享内存附加到进程的线性地址:start_code + brk = 0x10005000
函数返回:0x5000,这个进程的逻辑(虚拟)地址。
具体代码参考如下:
#include <asm/segment.h> // 段操作头文件。定义了有关段寄存器操作的嵌入式汇编函数。
#include <linux/kernel.h> // 内核头文件。含有一些内核常用函数的原形定义。
#include <linux/sched.h> // 调度程序头文件,定义了任务结构 task_struct、初始任务 0 的数据,有一些有关描述符参数设置和获取的嵌入式汇编函数宏语句。
#include <linux/mm.h> // 内存管理头文件。含有页面大小定义和一些页面释放函数原型。
#include <errno.h> // 错误号头文件。包含系统中各种出错号。(Linus 从 minix 中引进的)。
#define SHM_NUM 32 /* 最多32块共享内存 */
/* 共享内存结构体 */
struct shm_tables
{
int key; /* 共享内存标识 */
int size; /* 共享内存大小 */
unsigned long page; /* 共享内存地址 */
} shm_tables[SHM_NUM];
/* 获取一块空闲的物理页面来创建共享内存。 */
/* 参数:key标识申请到的内存key,size表示申请的内存大小。 */
/* 返回:在共享内存表中的索引值。 */
int sys_shmget(int key, int size)
{
int i; /* 在共享内存表中的索引 */
unsigned long page; /* 存放共享内存物理地址 */
/* 查看 key 对应的共享内存是否已存在 */
for (i = 0; i < SHM_NUM; i++)
if (shm_tables[i].key == key) /* 如果存在则直接返回对应的索引值 */
return i;
/* 内存大小超过一页 */
if (size > PAGE_SIZE)
return -EINVAL; /* 返回参数无效的错误 */
/* 获取一块空闲物理内存页面,返回起始物理地址 */
page = get_free_page();
if (!page)
return -ENOMEM; /* 返回内存不足的错误 */
printk("shmget get memory's address is 0x%08x\n", page);
/* 记录到共享内存表中 */
for (i = 0; i < SHM_NUM; i++)
{
if (shm_tables[i].key == 0)
{
shm_tables[i].key = key;
shm_tables[i].size = size;
shm_tables[i].page = page;
return i;
}
}
/* 如果前面没有找到,则共享内存表已经满了。*/
/* 正常可以考虑在errno.h文件定义一个错误常量,然后返回。因为是实验,所以就直接返回-1。 */
return -1;
}
/* 将指定物理页面映射到当前进程的线性地址空间。 */
/* 参数shmid:就是shmget函数返回的共享内存表中的索引值。*/
/* 返回值:返回共享内存在当前进程的是逻辑(虚拟)地址。 */
void *sys_shmat(int shmid)
{
/* code_base进程代码段基址;data_base进程数据段基址;start_code进程基址。 */
/* 这三个地址都是线性地址。 */
unsigned long code_base, data_base, start_code;
/* 判断共享内存 shmid 是否越界 及 共享内存是否存在 */
if (shmid < 0 || shmid >= SHM_NUM || shm_tables[shmid].key == 0)
return -EINVAL;
/* linux0.11中code_base、data_base、start_code都是一样的。可以参考 kernal/fork.c中copy_mem方法。 */
/* 在后面使用put_page进行附加的时候,用哪个都可以。 */
// code_base = get_base(current->ldt[1]); // 取代码段基址。
// data_base = get_base(current->ldt[2]); // 取数据段基址。
// start_code = current->start_code; // 进程基址。
// printk("current's code_base=0x%08x, data_base=0x%08x, start_code=0x%08x\n", code_base, data_base, start_code);
printk("current->start_code=0x%08x, current->brk=0x%08x, page=0x%08x\n", current->start_code, current->brk, shm_tables[shmid].page);
/* 把物理页面映射到进程的线性地址空间,映射到代码段+数据段后,堆栈段前。 */
/* 参考《注释》书籍图13-6 */
put_page(shm_tables[shmid].page, current->start_code + current->brk);
/* 修改总长度,brk为代码段和数据段的总长度 */
current->brk += PAGE_SIZE;
/* 返回共享内存在当前进程的是逻辑(虚拟)地址。 */
/* 返回无指定类型的指针,具体是用于int、char或其他类型,则用应用程序自己转换。 */
return (void *)(current->brk - PAGE_SIZE);
}
这里可以考虑将结构体 shm_tables 的定义放置到头文件 ./include/linux/shm.h,和信号量sem.h类似,更加规范一些,但是因为应用程序没有用到其中相关的变量,所以直接放在这个文件也行。
新增系统调用
增加了内核函数,相关的地方都需要进行调整,经过前面的实验,这个已经非常熟练了。
1)修改/include/unistd.h,添加新增的系统调用的编号:
/* 实验6 */
#define __NR_sem_open 72
#define __NR_sem_wait 73
#define __NR_sem_post 74
#define __NR_sem_unlink 75
/* 实验7 */
#define __NR_shmget 76
#define __NR_shmat 77
2)修改/kernel/system_call.s,需要修改总的系统调用数:
nr_system_calls = 78
3)修改/include/linux/sys.h,声明全局新增函数:
extern int sys_setregid();
/* 实验6 */
extern int sys_sem_open();
extern int sys_sem_wait();
extern int sys_sem_post();
extern int sys_sem_unlink();
/* 实验7 */
extern int sys_shmget();
extern int sys_shmat();
fn_ptr sys_call_table[] = {
//...sys_setreuid,sys_setregid,
sys_sem_open, sys_sem_wait, sys_sem_post, sys_sem_unlink, // 实验6
sys_shmget, sys_shmat // 实验7
};
4)修改 linux-0.11/kernel/Makefile,添加shm.c编译规则:
# 添加 shm.o
OBJS = sched.o system_call.o traps.o asm.o fork.o \
panic.o printk.o vsprintf.o sys.o exit.o \
signal.o mktime.o who.o sem.o shm.o
# ...
# 添加 shm.o 的依赖
## Dependencies:
shm.s shm.o: shm.c ../include/linux/kernel.h ../include/unistd.h
sem.s sem.o: sem.c ../include/linux/sem.h ../include/linux/kernel.h ../include/unistd.h
至此内核修改就完成了,可以尝试编译及运行内核程序,如果没有错误,表示修改成功。下面就要在Linux0.11上运行生产者消费者程序试试看。
运行生产者消费者程序
生产者和消费者程序都需要针对Linux0.11进行修改调整。
1)实现producer.c
#define __LIBRARY__ /* 定义一个符号常量,见下行说明。unistd.h文件中会用到。 */
#include <unistd.h> /* 提供对 POSIX 操作系统 API 的访问,例如 fork(), pipe(), read(), write(), close() 等 */
#include <stdio.h> /* 提供输入输出函数,例如 printf() */
#include <stdlib.h> /* 提供通用工具函数,例如 exit(), malloc(), free() */
#include <fcntl.h> /* 提供对文件控制选项的访问,例如 open(), lseek(),O_CREAT等 */
#include <linux/sem.h> /* 提供对 POSIX 信号量的访问,例如 sem_open(), sem_wait(), sem_post(), sem_unlink() */
#define M 530 /* 打出数字总数 */
#define N 5 /* 消费者进程数 */
#define BUFSIZE 10 /* 缓冲区大小 */
#define SHM_KEY 0x1234 /* 共享内存的key,用来在生产者和消费者进程之间进行识别 */
#define SHM_SIZE 1024 /* 共享内存的大小,实际11就可以了,1024看起来更帅气一些 */
_syscall2(sem_t *, sem_open, const char *, name, unsigned int, value);
_syscall1(int, sem_wait, sem_t *, sem);
_syscall1(int, sem_post, sem_t *, sem);
_syscall1(int, sem_unlink, const char *, name);
_syscall2(int, shmget, int, key, int, size);
_syscall1(int, shmat, int, shmid);
int main()
{
sem_t *empty, *full, *mutex; /* 3个信号量 */
int shm_id; /* 共享内存id */
int *shm_addr; /* 共享内存在当前进程虚拟地址空间的起始地址 */
int i; /* 循环变量和子进程计数器 */
int buf_in = 0; /* 记录上次写入缓冲区位置 */
/* 1. 创建信号量 */
if ((mutex = sem_open("mutex", 1)) == NULL)
{
perror("sem_open() error!\n");
return -1;
}
if ((empty = sem_open("empty", BUFSIZE)) == NULL)
{
perror("sem_open() error!\n");
return -1;
}
if ((full = sem_open("full", 0)) == NULL)
{
perror("sem_open() error!\n");
return -1;
}
/* 2. 创建共享内存段,用于进程间通信 */
shm_id = shmget(SHM_KEY, SHM_SIZE); /* 获取一块空闲的物理页面来创建共享内存,第11个位置消费者进程用来存储读取的位置。 */
if (shm_id < 0)
{
perror("Fail to shmget!\n");
return -1;
}
shm_addr = (int *)shmat(shm_id); /* 将指定物理页面映射到当前进程的线性地址空间,返回当前进程的逻辑(虚拟)地址。 */
if (shm_addr == (void *)-1) /* 因为shm_addr转化为指针了,所以对比里-1也要转化为指针,避免编译器报警 */
{
perror("Fail to shmat!\n");
return -1;
}
/* 3. 生产消息 */
printf("I'm producer. pid = %d\n", getpid());
/* 生产多少个产品就循环几次 */
for (i = 0; i < M; i++)
{
sem_wait(empty); /* empty--,等待有空闲缓冲区, empty>0才能生产 */
sem_wait(mutex); /* mutex--,进入临界区 */
/* 从上次位置继续向共享缓冲区写入一个字符 */
shm_addr[buf_in] = i;
printf("%d: buf_in=%d, shm_addr[buf_in]=%d,\n", getpid(), buf_in, shm_addr[buf_in]);
/* 更新写入缓冲区位置,保证在0-9之间,缓冲区最大为10 */
buf_in = (buf_in + 1) % BUFSIZE;
sem_post(mutex); /* mutex++, 离开临界区 */
sem_post(full); /* full++,增加已占用缓冲区计数 */
}
printf("Producer end.\n");
fflush(stdout); /*确保将输出立刻输出到标准输出。*/
sleep(3); /* 确保消费者消费完成 */
/* 4. 回收 */
/* 使用完毕后,分离共享内存段,本次实验未实现该函数。 */
/* 清理资源(在实际应用中,这通常会在所有进程都完成共享内存的使用后进行),本次实验未实现该函数。 */
/* 释放信号量 */
sem_unlink("full");
sem_unlink("empty");
sem_unlink("mutex");
return 0;
}
2)实现consumer.c
#define __LIBRARY__ /* 定义一个符号常量,见下行说明。unistd.h文件中会用到。 */
#include <unistd.h> /* 提供对 POSIX 操作系统 API 的访问,例如 fork(), pipe(), read(), write(), close() 等 */
#include <stdio.h> /* 提供输入输出函数,例如 printf() */
#include <stdlib.h> /* 提供通用工具函数,例如 exit(), malloc(), free() */
#include <linux/sem.h> /* 提供对 POSIX 信号量的访问,例如 sem_open(), sem_wait(), sem_post(), sem_unlink() */
#define M 530 /* 打出数字总数 */
#define N 5 /* 消费者进程数 */
#define AVG M / N /* 每个消费者消费数字平均数 */
#define BUFSIZE 10 /* 缓冲区大小 */
#define SHM_KEY 0x1234 /* 共享内存的key,用来在生产者和消费者进程之间进行识别 */
#define SHM_SIZE 1024 /* 共享内存的大小,实际11就可以了,1024看起来更帅气一些 */
_syscall2(sem_t *, sem_open, const char *, name, unsigned int, value);
_syscall1(int, sem_wait, sem_t *, sem);
_syscall1(int, sem_post, sem_t *, sem);
_syscall1(int, sem_unlink, const char *, name);
_syscall2(int, shmget, int, key, int, size);
_syscall1(int, shmat, int, shmid);
int main()
{
sem_t *empty, *full, *mutex; /* 3个信号量 */
int shm_id; /* 共享内存id */
int *shm_addr; /* 共享内存在当前进程虚拟地址空间的起始地址 */
pid_t pid; /* fork的进程id */
int j, k; /* 循环变量 */
int buf_out = 0; /* 记录上次从缓冲区读取位置 */
int data; /* 子进程从共享内存读取的数据 */
int child; /* 子进程总数 */
/* 1. 打开已存在的信号量,这些信号量在生产者进程创建过了,消费者进程这里的第二个参数实际上是没有用的。 */
if ((mutex = sem_open("mutex", 1)) == NULL)
{
perror("sem_open() error!\n");
return -1;
}
if ((empty = sem_open("empty", BUFSIZE)) == NULL)
{
perror("sem_open() error!\n");
return -1;
}
if ((full = sem_open("full", 0)) == NULL)
{
perror("sem_open() error!\n");
return -1;
}
/* 2. 创建共享内存段,用于进程间通信 */
shm_id = shmget(SHM_KEY, SHM_SIZE); /* 获取一块空闲的物理页面来创建共享内存,第11个位置消费者进程用来存储读取的位置。 */
if (shm_id < 0)
{
perror("Fail to shmget!\n");
return -1;
}
/* 3. 消费者进程,一共创建N个消费者进程 */
for (j = 0; j < N; j++)
{
pid = fork();
if (pid < 0) /* 创建进程失败 */
{
perror("Fail to fork!\n");
return -1;
}
else if (pid == 0)
{
/* 这行代码要放到子进程里,每个子进程都有自己的虚拟内存空间和线性地址。 */
shm_addr = (int *)shmat(shm_id); /* 将指定物理页面映射到当前进程的虚拟地址空间 */
if (shm_addr == (void *)-1) /* 因为shm_addr转化为指针了,所以对比里-1也要转化为指针,避免编译器报警 */
{
perror("Fail to shmat!\n");
return -1;
}
/* 每个进程平均读取数字,即每个进程读取 M/N 个数字 */
for (k = 0; k < AVG; k++)
{
/* full大于0,才能消费 */
sem_wait(full); /* full--, 等待有数据可读 */
sem_wait(mutex); /* mutex--,进入临界区 */
/* 从文件第11个位置获得上次读取位置 */
buf_out = shm_addr[BUFSIZE];
/* 从上次读取位置继续读取数据 */
data = shm_addr[buf_out];
/* 在内存第11个位置写入下次应读取位置 */
buf_out = (buf_out + 1) % BUFSIZE;
shm_addr[BUFSIZE] = buf_out;
printf("%d: %d\n", getpid(), data); /* 打印消费者进程 ID和消费的数据 */
fflush(stdout); /* 确保数据送到终端 */
sem_post(mutex); /* mutex++,离开临界区 */
sem_post(empty); /* empty++,增加空闲缓冲区计数 */
}
printf("Child-%d: pid = %d end.\n", j, getpid());
return 0;
}
}
/* 4. 回收 */
/* 回收子进程资源 */
child = N; /* 包括生产者在内的子进程总数 */
while (child--) /* 等待所有子进程结束 */
wait(NULL); /* 等待子进程结束 */
/* 使用完毕后,分离共享内存段,本次实验未实现该函数。 */
/* 释放信号量 */
sem_unlink("full");
sem_unlink("empty");
sem_unlink("mutex");
return 0;
}
和Ubuntu下的消费者程序不同,指定物理页面映射到当前进程的线性地址空间,即 shmat 这行代码必须要放到子进程内,不然输出的时候会错乱。
关于这个问题我也排查了一段时间,最后才发现,分析原因主要就是fork的写时复制(copy on write)机制。
当fork进程时,子进程和父进程都有自己的线性地址,但对应的物理内存都是一样的,只是只能读不能写,当子进程需要写入的时候(即这行代码:shm_addr[BUFSIZE] = buf_out),内核就会申请一个新的物理页进行写入,这个写入的地方就不是共享内存的地址了。 所以需要在每个子进程内都附加上这段共享内存。
但是不知道为什么在Ubuntu上的消费者程序就不需要这么做,估计是新的内核在fork的时候对共享内存进行了处理。
3)将相关文件复制到Linux0.11文件系统
# 在 oslab 目录下
$ sudo ./mount-hdc
$ cp ./consumer.c ./hdc/usr/root/
$ cp ./producer.c ./hdc/usr/root/
$ cp ./linux-0.11/include/unistd.h ./hdc/usr/include/
$ cp ./linux-0.11/include/linux/sem.h ./hdc/usr/include/linux/
$ sudo umount hdc
4)编译及运行Linux-0.11
# 在 oslab 目录下
$ cd ./linux-0.11
$ make all
$ ../run
5)在Linux0.11中编译生产者消费者程序
$ gcc -o producer producer.c
$ gcc -o consumer consumer.c
$ sync
编译时出现这个报错:
In function sem_open:
warning: return of pointer from integer lacks a cast
这个是因为_syscall2函数中出错了会返回-1,和定义的指针类型不同,这个在实验中可以忽略,不影响实验效果。
6)在Linux0.11中运行生产者消费者程序
# 通过在命令后加一个 & ,可以使其在后台运行。进而就可以执行消费者程序。
# 在实验过程中,执行消费者程序时,也需要增加一个 & ,不然shell界面会输出错乱。
$ ./producer > producer.txt &
$ ./consumer > consumer.txt &
$ sync
运行程序时发现先内核报了一个错误:

排查发现是在 ./mm/memory.c 中的 free_page 函数报出的。因为内核异常,会导致整个程序终止,写入的日志就不完整了,考虑到这个问题并不是致命,我暂时把这个 panic 注释掉了。
关于这个问题,有兴趣可以自行排查,有一些思路:在free_page函数内,打印出当前的进程信息和要释放的地址,看能否观察到具体释放的是哪一个物理内存页面。
7)将日志文件移动到Ubuntu下
# 在 oslab 目录下
$ sudo ./mount-hdc
$ sudo cp ./hdc/usr/root/producer.txt ./
$ sudo cp ./hdc/usr/root/consumer.txt ./
8)查看日志
生产者日志:
# producer.txt
I'm producer. pid = 6
6: buf_in=0, shm_addr[buf_in]=0,
6: buf_in=1, shm_addr[buf_in]=1,
6: buf_in=2, shm_addr[buf_in]=2,
6: buf_in=3, shm_addr[buf_in]=3,
6: buf_in=4, shm_addr[buf_in]=4,
6: buf_in=5, shm_addr[buf_in]=5,
6: buf_in=6, shm_addr[buf_in]=6,
6: buf_in=7, shm_addr[buf_in]=7,
6: buf_in=8, shm_addr[buf_in]=8,
6: buf_in=9, shm_addr[buf_in]=9,
6: buf_in=0, shm_addr[buf_in]=10,
6: buf_in=1, shm_addr[buf_in]=11,
6: buf_in=2, shm_addr[buf_in]=12,
6: buf_in=3, shm_addr[buf_in]=13,
...
6: buf_in=8, shm_addr[buf_in]=528,
6: buf_in=9, shm_addr[buf_in]=529,
Producer end.
消费者日志:
# consumer.txt
0. 0
1. 1
2. 2
3. 3
4. 4
5. 5
6. 6
7. 7
8. 8
9. 9
10. 10
11. 11
12. 12
13. 13
14. 14
15. 15
16. 16
17. 17
18. 18
...
9: 294
9: 295
Child-0: pid = 9 end.
12: 296
12: 297
...
12: 330
Child-3: pid = 12 end.
13: 331
13: 332
...
11: 428
Child-2: pid = 11 end.
10: 429
...
13: 504
Child-4: pid = 13 end.
10: 505
10: 506
10: 507
...
10: 527
10: 528
10: 529
Child-1: pid = 10 end.
实验报告
完成实验后,在实验报告中回答如下问题:
1) 对于地址映射实验部分,列出你认为最重要的那几步(不超过 4 步),并给出你获得的实验数据。
这个在上面实验中已经总结了,本质上就是如下三步:
- 查找变量i的逻辑(虚拟)地址:通过dba-asm调试器进行查找。
- 查找变量i的线性地址:进程的LDT表可以通过LDTR和GDTR查找出来;而后通过逻辑地址的段寄存器ds,在LDT表中查找到对应项,即可得到基地址,加上逻辑地址中的偏移地址就是线性地址了。
- 查找变量i的物理地址:开启分页后,线性地址分解成3个部分,依次在页目录表、页表中查找,而后加上线性地址最后12位,便是物理地址了。
2) test.c 退出后,如果马上再运行一次,并再进行地址跟踪,你发现有哪些异同?为什么?
我发现了3个不同,尝试排查了下原因,一开始摸不着头脑,后来结合《注释》书籍和源码,大概明白了原因。
2.1) GDT表中对应的LDT段描述符不一样(0xa2d00068 0x000082f9 -> 0x52d00068 0x000082fd,LDT段基址发生了变化。
答:在 Linux 0.11 中,每个进程都有自己的局部描述符表(LDT),用于描述该进程的代码段、数据段等。全局描述符表(GDT)中有一个 LDT 段描述符,用于指向每个进程的 LDT。
当 shell 程序执行 test.c 程序时,会 fork 一个新进程,fork程序内会新申请一个物理内存页存储进程结构信息(进程结构信息中存储了 LDT),然后设置新进程的 LDT,并在 GDT 中设置相应的 LDT 段描述符。物理内存页的申请具有不确定性,所以每次运行 test.c,其 LDT 地址可能不一样。
相关代码参考如下:
- fork进程:./kernel/fork.c 中的 copy_process
- 新申请内存页:./kernel/fork.c 中的 77 行。
- 设置新进程的LDT:./kernel/fork.c 中的 54、55 行。
- 在GDT中设置相应的LDT段描述符:./kernel/fork.c 中的 131 行。
2.2) 页目录项发生了变化(0x00fa9027 -> 0x00fa6027),页目录项存储的内容是表示页表的情况(高20位是表示页表基址),因此可以得出页表的基址发生了变化。这点可以查看 fs/exec.c 中 do_execve 函数的328、329行。
2.3) 页表项也发生了变化(0x00fa7067 -> 0x00fa3067),页表项存储的内容是表示物理页的情况(高20位是表示物理页基址),因此可以得出物理页的基址发生了变化。原因同上。
参考资料
从以下资料得到了不少帮助,特此表示感谢。
完。



















 3514
3514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











