




第8章 比高斯更快的计算
该章通过从1加到100的功能,介绍了数据结构——栈、处理器的寻址方式。
书中例程的功能就是在页面输出:1+2+3+…+100=5050。
从1加到100的故事
计算机不懂的等差数列求和公式,但是它运行速度很快,从1一直加到100,就是一眨眼的事。
代码清单8-1
作者提供了源码,可以查看配书源码和工具的c08文件夹。
显示字符串
该章节主要介绍了程序时如何实现显示 ‘1+2+3+…+100’ 这个字符串的。
和上一章的方式基本类似,就是在声明字符串的时候,采用一起声明的的方式了。
;第七章的方式
; 相当于把字符和显示属性放在一起声明
mytext db 'L',0x07,'a',0x07,'b',0x07,'e',0x07,'l',0x07,' ',0x07,'o',0x07,\
'f',0x07,'f',0x07,'s',0x07,'e',0x07,'t',0x07,':',0x07
;第八章的方式
; 只声明字符串相关内容,显示属性在循环显示的时候赋值为0x07。
message db '1+2+3+...+100=' ;声明了字符串。
这样就更加直观了。可以看出来,书中的例子都是循序渐进改进的。
计算1到100的累加和
思路上很简单,代码也不难理解。
思路:
- ax清0,存储每次累加的和。
- cx从1~100依次累加到ax中。
代码:书中代码没有注释,我给代码加了一些注释。
;以下计算1到100的和
xor ax,ax ; ax清0
mov cx,1 ; cx初值为1
@f:
add ax,cx ; (ax)=(ax)+(cx)
inc cx ; (cx)++
cmp cx,100 ; 比较cx和100
jle @f ; jle(Jump Less equal) cx<=100则继续循环
溢出问题:
ax最大只能表示65535,这里和为5050,不会溢出。
累加和各个数位的分解与显示
栈和栈段的初始化
上一章是将分解出来的位数保存在事先声明的数据段,该章使用栈进行处理。
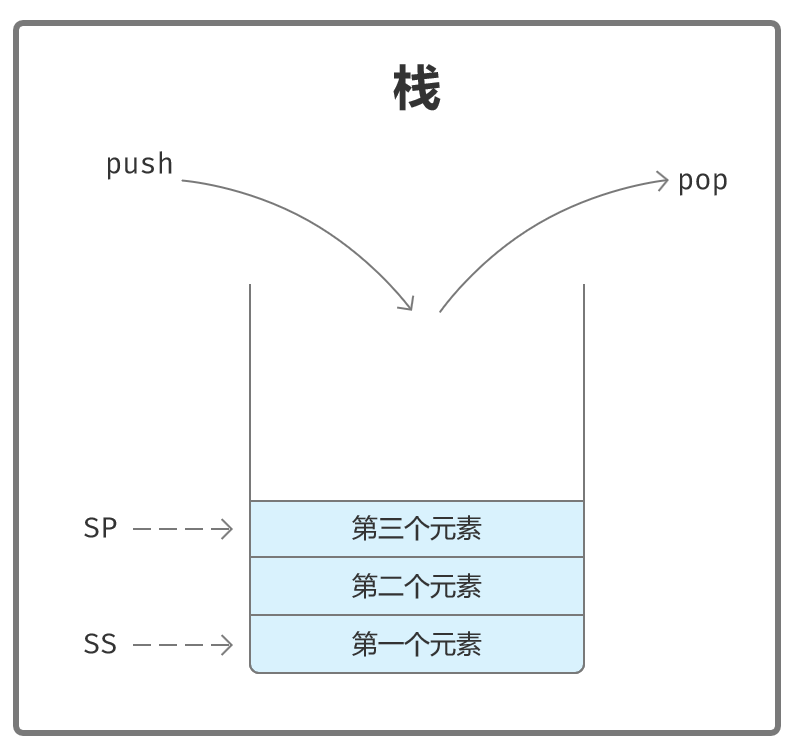
栈(Stack)是一种特殊的数据存储结构,数据的存取只能从一端进行,遵循先进后出(FILO:First Input Last Output)的原则。
栈通过栈段SS(Stack Segment)和栈指针SP(Stack Pointer)进行访问。
栈操作:
- push 推入数据
- pop 弹出数据
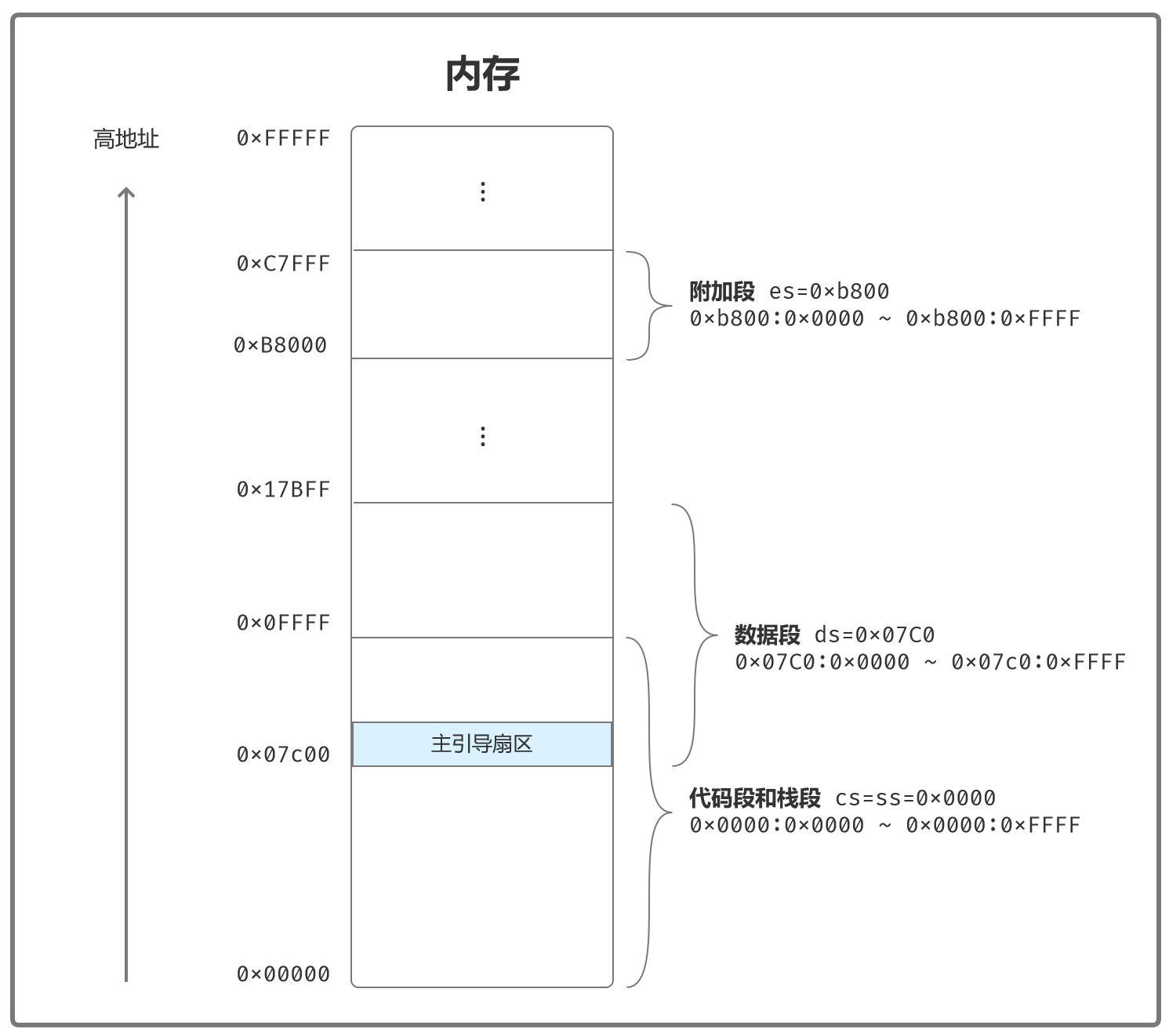
书中栈段的初始化地址是:0x0000:0x0000~0x0000:0xFFFF
根据代码段、数据段、扩展段等其他段的设置可以得到如下内存映像:
分解各个数位并压栈
书中代码我加一些注释:
mov bx,10 ;余数放在bx中
xor cx,cx ;(cx)=0,用cx记录循环的次数,即数的为位数
@d:
inc cx ;每次循环 cx+1
xor dx,dx ;相当于 mov dx,0
div bx
or dl,0x30 ;相当于加上0x30
push dx ;将余数推入栈,一次推入两个字节
cmp ax,0 ;检测商是否为0
jne @d ;商不为0,则继续循环
程序第50行为什么用 or dl,0x30?
因为除以10的余数为0~9,1只可能出现低4位
0000 1111(低4位)
or 0011 0000(0x30)
所以使用or和add是一样的效果。
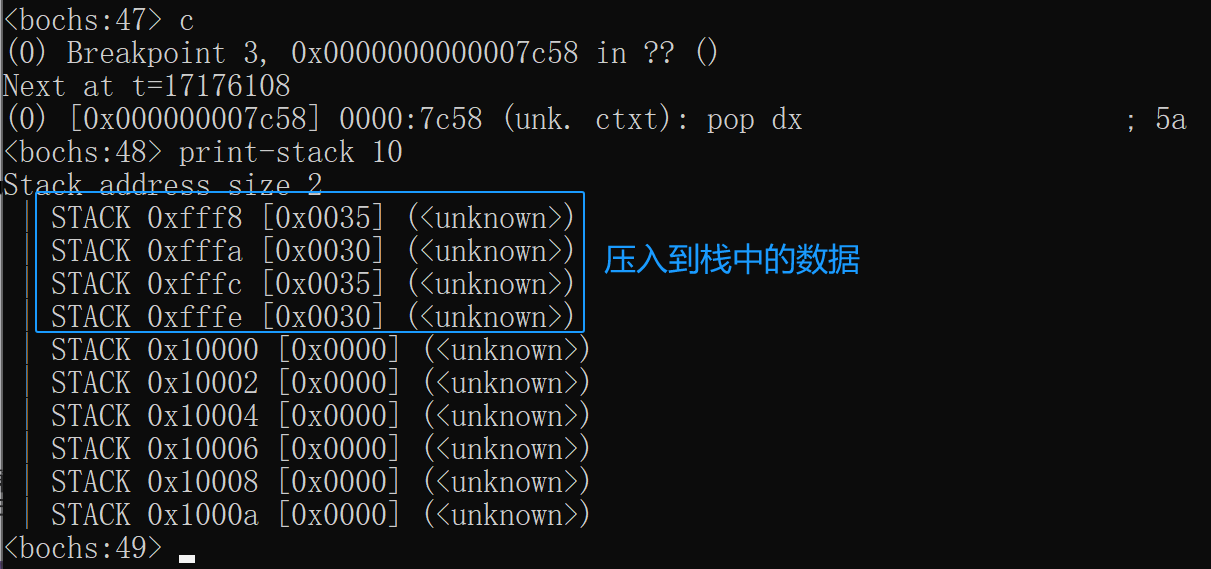
当该代码执行完成时,栈中的情况如下所示:
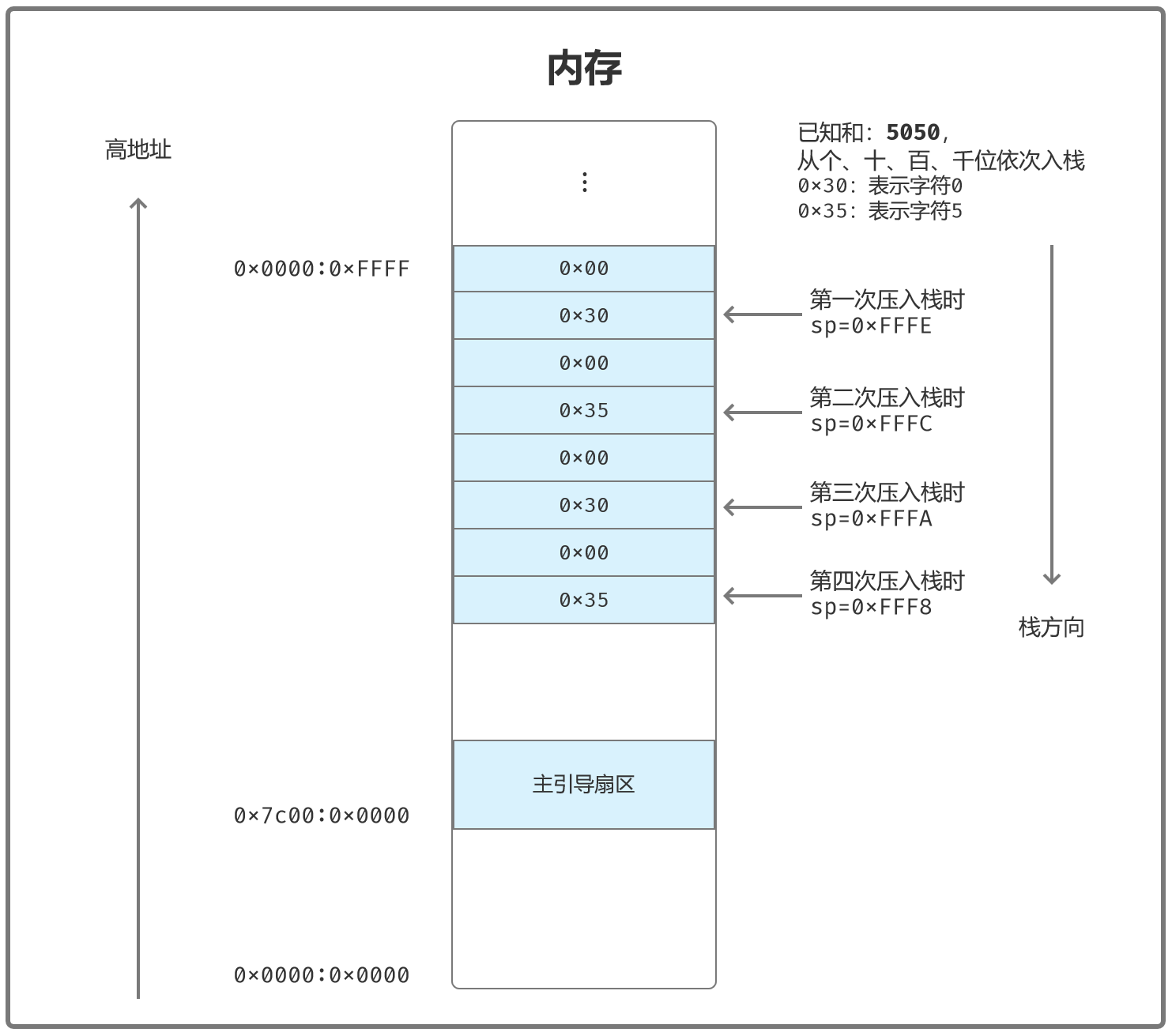
第一次压入栈时,SP=0x0000 - 2,高位会被舍弃掉,所以就是0xFFFE,这个地方不太好理解。
为什么不能压入一个字节?
因为个、十、百、千每个数字都是1个字节就够了,为什么要压入两个字节?
因为push最少只能接受16位的操作数。如果是压入内存,需要指定关键词 word、dword。
出栈并显示各个数位
书中代码多写了一些注释:
;以下显示各个数位
@a:
pop dx ;将栈中的数据弹一个字(2字节),存储到dx
mov [es:di],dl ;显示的字符
inc di ;后面一个字节表示显示的属性
mov byte [es:di],0x07 ;字符显示的属性0000_0111,黑底白字
inc di ;继续下一个字符
loop @a
循环次数cx在前面分解数字的时候就算好了,所以这里没有体现。
使用栈先进后出的方式在显示数值的时候非常方便。
进一步认识栈
第一,push指令的操作数可以是16位寄存器或者16位内存单元,push指令执行后,压入栈中的仅仅是该寄存器或者内存单元里的数值,与该寄存器或内存单元不再相干。
第二,栈在本质上也只是普通的内存区域,之所以要用push和pop指令来访问,是因为你把它看成栈而已。
第三,要注意保持栈平衡。push和pop的次数要一样多。
第四,在编写程序前,必须充分估计所需要的栈空间,以防止破坏有用的数据。
第五,尽管不能完全阻止程序中的错误,但是,通过将栈定义到一个单独的64KB段,可以使错误仅局限于栈,而不破坏其他段的有用数据。
程序的编译和运行
观察程序的运行结果
在调试过程中查看栈中内容
使用 print-stack n 可以查看栈中的内容:
8086处理器的寻址方式
既然操作和处理的是数值,那么,必定涉及数值从哪里来,处理后送到哪里去,这称为寻址方式(Addressing Mode)。
寄存器寻址
最简单的寻址方式是寄存器寻址。
;直接操作寄存器
mov ax,cx
add bx,0xf000
inc dx
立即寻址
立即数寻址,指令的操作数是一个立即数:
add bx,0xf000 ;bx加上1个立即数 0xf000
mov dx,label_a ;标号会被转化为数值
一般高级语言叫做常量。
内存寻址
寄存器寻址的操作数位于寄存器中,立即寻址的操作数位于指令中,是指令的一部分。
所谓的内存寻址方式,就是如何在指令中指定操作数的偏移地址,供处理器访问内存时使用,这个偏移地址也叫有效地址(Effective Address, EA)。句话说,内存寻址方式就是在指令中指定偏移地址(有效地址)如何计算。
1.直接寻址
mov ax,[0x5c0f] ; DS*16+0x5c0f
add word [0x0230],0x5000 ; DS*16+0x0230
xor byte [es:label_b],0x50 ; es*16+label_b的地址
2.基址寻址
基址寻址:在指令的地址部分使用基址寄存器BX或者BP来提供一个基准地址。
引例,将buffer中的每个字+1。
buffer dw 0x20,0x100,0x0f,0x300,0xff00
inc word [buffer]
inc word [buffer+2]
inc word [buffer+4]
逐行处理,这种方式不太方便。如果有100个,就要写100行。
基址寻址:基地址+位移
mov [bx],dx ; DS*16+bx <- (dx)
add byte [bx],0x55 ; DS*16+bx <- 0x55
随意访问栈中的内容
mov ax,0x5000 ;将 0x5000 压入栈中
push ax
mov bp,sp ;将指向0x5000的指针保存下来
mov ax,0x7000 ;再压入一个 0x7000
push ax
mov dx,[bp] ; dx <- (ss*16+bp), 即0x5000
可以为基址寄存器BP加上一个位移,即可访问栈其他位置的内容:
mov dx,[bp-2] ; dx <- (ss*16+bp-2), 即0x7000
改进引例:
mov bx,buffer ;buffer标号所在地址为基地址
mov cx,5 ;循环5次
lpinc:
inc word [bx] ;+1
add bx,2 ;指向下一个地址
loop lpinc
3.变址寻址
变址寻址类似于基址寻址,唯一不同之处在于这种寻址方式使用的是变址寄存器(或称索引寄存器)SI和DI。
mov [si],dx ; ds*16+si <- (dx)
add ax,[di] ; ax <- ds*16+di
xor word [si],0x8000 ; ds*16+si <- 0x8000
带偏移量
mov [si+0x100],al ; ds*16+si+0x100 <- al
and byte [di+label_a],0x80 ; ds*16+di+label_a <- 0x80
4.基址变址寻址
将前面的基址和变址结合起来。
引例,将字符串反向排列。
string db 'abcdefghijklmnopqrstuvwxyz'
;先把字母逐个弹入栈。
mov cx,26
mov bx,string
lppush:
mov al,[bx]
push ax
inc bx
loop lppush
;依次弹出。
mov cx,26
mov bx,string
lppop:
pop ax
mov [bx],al
inc bx
loop lppop
使用基址寄存器(BX或者BP),变址寄存器(SI或者DI)
mov ax, [bx+si] ; ax <- (ds*16+bx+si)
mov word [bx+di], 0x3000 ; ds*16+bx+di <- 0x3000
改进引例:
mov bx, string
mov si, 0 ;源从0开始,一个从前
mov di, 25 ;目的从25开始。一个从后
order:
mov ah, [bx+si]
mov al, [bx+di]
mov [bx+si], al
mov [bx+di], ah
inc si
dec di
cmp si,di
jl order
使用基址寄存器和变址寄存器允许一个数值位移:
mov [bx+si+0x100],al
and byte [bx+di+label_a],0x80
完。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











