







 本文介绍了Redis的主从复制、哨兵机制和集群的原理与实践。主从复制用于读写分离,但不支持自动故障转移;哨兵系统负责监控和自动故障切换;Redis集群则通过虚拟槽分区实现数据的均匀分布,支持横向扩展。搭建过程中涉及到配置文件的修改、命令行工具的使用以及哨兵的定时任务等。
本文介绍了Redis的主从复制、哨兵机制和集群的原理与实践。主从复制用于读写分离,但不支持自动故障转移;哨兵系统负责监控和自动故障切换;Redis集群则通过虚拟槽分区实现数据的均匀分布,支持横向扩展。搭建过程中涉及到配置文件的修改、命令行工具的使用以及哨兵的定时任务等。
技术的背景
1、一开始只有一台机器,所以请求都打在这台机器上,访问量少自然没问题,但是随着业务的发展,访问量越来越大,一台机器扛不住了,就想着集群来解决这个问题。
2、开始可能是写很少,读特别多的场景,那么就出现主从的方法,一主多从,将读都通过从节点拿数据,那么就是实现了读的负载均衡。主从如果master崩了后,出现需要手动去调整的问题。
3、引入哨兵机制可以解决当主节点崩了之后,动态将从节点晋升为主节点的问题。但是对于写入量大的场景,一台master就会出现瓶颈。
3、一主多从无法满足写入量大的场景,那么就出现了多主多从的集群,假设有三台机器(假设这里都是master),那么就面临如何将对应的请求发到哪一台机器上去的问题。
4、可以通过将对应的key进行hash,然后将hash值和对应的节点数取余,得到0,1,2的编号,然后将请求分别映射到0,1,2redis实例,但是这样子又会出现问题,就是每次增加节点或者减少节点的时候,都需要重新对不同的值进行取余,那么几乎所有数据都失效,就出现大面积缓存失效的问题,如果此时访问量过大,没有做相应的措施,短时间大量请求打到数据库的话,数据库有可能会崩溃。
5、为了防止大面积的缓存失效,就有了一致性hash的算法(也可以是虚拟hash槽的方法,这两个算法实现的效果类似,都解决了节点添加和减少导致的大面积缓存失效的问题),一致性hash的算法在节点数越多的情况下,数据的分布越均匀,但是如果节点数特别少,比如像上述说的3个,那么在一致性hash环中,可能分配特别不均匀。
6、如果节点过少的话,可以引入虚拟节点来达到数据均衡的效果。
1、主从复制
1.1、搭建主从复制
到githubhttps://github.com/tporadowski/redis/releases下载.zip文件,我这里是windows环境,所以就直接使用windows版本了。
下载后解压,进入到redis的根目录,在当前目录打开git base,
然后输入cp redis.windows.conf redis.windows-6379.conf 然后修改 dir ./ ==> dir ./6379
cp redis.windows.conf redis.windows-6379.conf 然后修改 port 6379 ==> port 6380 dir ./ ==> dir ./6380 同时加入 slaveof 127.0.0.1 6379
然后分别执redis-server.exe redis.windows-6379.conf redis-server.exe redis.windows-6380.conf
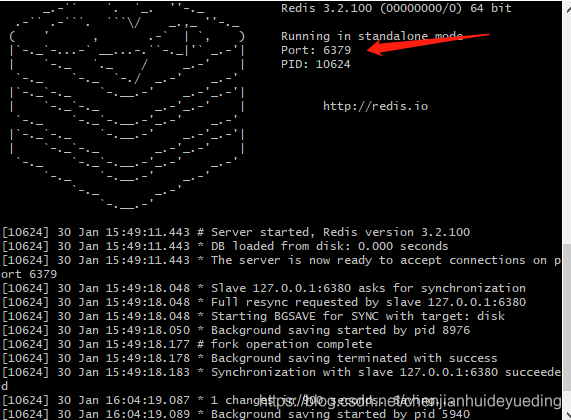
主服务器6379对应的redis实例日志信息:(可以看到有个Slave 127.0.0.1:6380 asks for synchronization的日志)
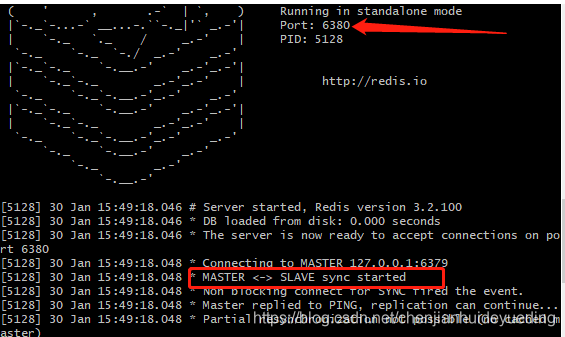
从服务器6380打印日志:
首先建立主服务器的cli连接:redis-cli.exe -p 6379 然后执行set name jeffchan
D:\software\Redis-x64-3.2.100>redis-cli.exe -p 6379
127.0.0.1:6379> set name jeffchan
OK
127.0.0.1:6379>连接从服务器:redis-cli.exe -p 6380 然后执行get name
D:\software\Redis-x64-3.2.100>redis-cli.exe -p 6380
127.0.0.1:6380> get name
"jeffchan"
127.0.0.1:6380>注意:从服务器是不支持写操作的,执行的话,会报以下错误。
127.0.0.1:6380> set name0 jeffchan0
(error) READONLY You can't write against a read only slave.可以通过在从服务器的客户端执行slaveof no noe来断开主从连接,但是注意从服务的数据不会删除,只是不再从主服务器接受数据而已
从服务:
127.0.0.1:6380> slaveof no one
OK
主服务:
127.0.0.1:6379> set name1 jeffchan1
OK
从服务:
127.0.0.1:6380> get name1
(nil)
可以发现从服务器已经不再从服务器同步数据了。可以在从服务器客户端执行:slaveof 127.0.0.1 6379命令来建立主从连接
断开主服务器,从服务器无法连接主服务器:
[5128] 30 Jan 16:48:55.908
Sending command to master in replication handshake: -Writing to master: Unknown error此时从服务器还是没有晋升为master,执行写命令的话,还是会提示异常。此时要通过手动去调整这个主从集群。如果要动态选举master的话,那么需要引入redis的哨兵,这个在后续解释。
1.2、主从复制的过程
主从复制的过程可以分成三个阶段,一开始是从服务器发送sync的命令给到主服务器,主服务器会执行bgsave命令,同时对后续过来的请求进行缓存,生成对应的快照文件后发送给从服务器,
从服务器接收到对应的快照后,执行快照的内容保存起来,执行完后;主服务器会将缓存的命令发送给从服务器,从服务器接收并执行命令;最有一个阶段就是主服务器的每一个写命令都会同步非到从服务器,从服务接受并执行命令。
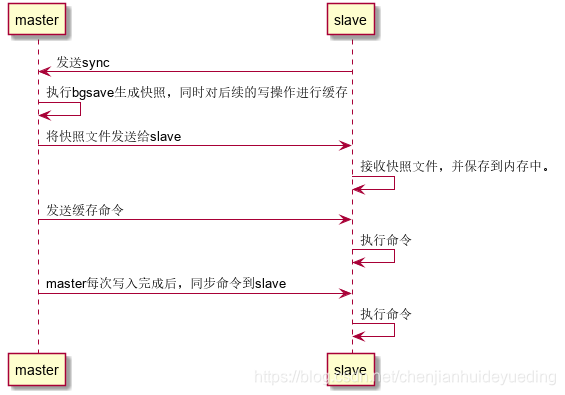
主从复制可以进行可以分担master的读压力,提高查询的性能;但是它不具备故障转移,动态选举master等功能,当master崩了后需要手动调整从节点为master或者从新启动master。
2、哨兵机制
在根目录创建一个sentinel.conf文件,输入内容:
sentinel monitor master 127.0.0.1 6379 1
sentinel down-after-milliseconds master 5000
sentinel config-epoch master 0
启动./redis-server.exe sentinel.conf --sentinel
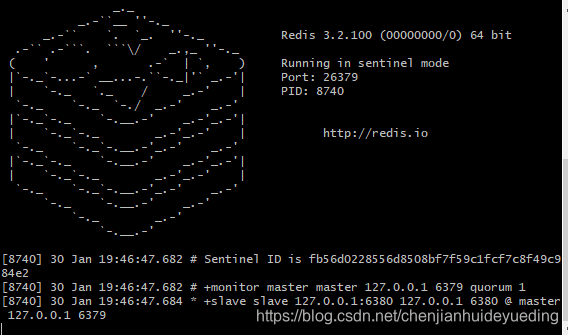
执行完后发现配置文件被修改了,记录了监控的信息
sentinel myid fb56d0228556d8508bf7f59c1fcf7c8f49c984e2
sentinel monitor master 127.0.0.1 6379 1
sentinel down-after-milliseconds master 5000
sentinel config-epoch master 0
# Generated by CONFIG REWRITE
port 26379
dir "D:\\software\\Redis-x64-3.2.100"
sentinel leader-epoch master 0
sentinel known-slave master 127.0.0.1 6380
sentinel current-epoch 0此时将主节点移除:
[884] 31 Jan 09:14:02.873
+promoted-slave slave 127.0.0.1:6380 127.0.0.1 6380 @ master 127.0.0.1 6379
[884] 31 Jan 09:14:02.873
+failover-state-reconf-slaves master master 127.0.0.1 6379
[884] 31 Jan 09:14:02.966
+failover-end master master 127.0.0.1 6379
[884] 31 Jan 09:14:02.966
+switch-master master 127.0.0.1 6379 127.0.0.1 6380此时发现已经将从节点6380提升了为master
重新启动master,发现6379又变成了master,6380变成了slave,整个过程都是动态完成的,不需要手动操作。哨兵也可以部署成集群的方式,它的作用可以监控主从集群的情况,当有足够的
哨兵确认对应的节点下线后,则节点被标记为下线状态。
对于哨兵来说,会有三个定时任务来:
1、每秒向所有主、从、其他哨兵发送ping指令,如果在down-after-milliseconds(可以配置的时间)时间内没有回应,那么标记为主观下线,相当于心跳检测
2、每两秒通过发布订阅某个channel进行信息交换,因为哨兵是集群的,各个哨兵之间需要交换各自对主从节点的判断。
3、每10秒对主、从实例发送info指令,用于确定redis的主从关系,因为在配置哨兵的时候,并没有指定从节点的,仅仅是指定master,所以需要info指令来获取slave的信息。
标记节点下线分为:主观下线和客观下线
主观下线是指当有一个哨兵发现某个ping的服务在指定时间内没有回应,会标记服务为主观下线
客观下线:是指多个哨兵,个数达到了配置文件中指定的个数都认为对应的服务主观下线,那么就会标记为客观下线。
3、redis集群
首先集群是为了解决横向扩展的问题。就是当请求量很大(这里包括写的能力,可以部署成多主多从),服务承受不住时,可以扩展机器,增加服务来应对突然增加的访问量。
redis集群有多种方案,这里只涉及官方3.0版本后推出的方案。RedisCluster
假设有6条数据,我们集群有3台机器(这里就不涉及从节点的情况,这三条机器这里都是master),那么可以会对数据进行hash分区然后对节点取余数来定位数据写入到哪台实例(分区方式:虚拟槽分区和一致性hash分区)
RedisCluster集群方案是采用虚拟槽分区的方式,所有的key都会通过CRC16方法进行hash值的计算,然后对16384取余,映射到槽点0 - 16383中。
假设三个实例分别叫做:A、B、C
那么key取值为【0 - 5460】存到redisA中去,值为【5461-10922】存到redisB中去,值为【10923-16383】存到redisC中去。即:
redisA : 0 - 5460
redisB: 5461-10922
redisC: 10923-16383
这样槽点的分布就很均匀。这种结构在新增节点和减少节点的时候会比较方便,比如,现在服务量上来了,我想要增加一台redisD实列,那么增加后,可以直接从三个节点节点中,均匀的抽一部分槽点给到redisD。此时的槽点分配值为:
redisA : 1365-5460
redisB: 6827-10922
redisC: 12288-16383
redisD:0-1364 5461-6826 10923-12287
此时的分配还是很均匀的。而且会发现,这里redis中因为添加节点实效的缓存就仅仅是对应的4分之一总的槽点对应的数据。这能有效的避免大面积的数据失效,导致缓存雪崩的问题。同理,减少一个节点也是将即将下线的节点所管理的槽点,均匀分配给其他还在线的节点。
redis集群可以很好的解决横向扩展的问题,让缓存系统在请求量一直上升的前提下,能通过扩展机器来达到负载均衡的效果。但是因为redis进行集群后,也会存下一些问题:不支持多数据库,目前只支持0数据库;多个实列间不支持事务;不支持多个key位于不同redis实例的mset,mget操作;key是数据分区的最小单位,不能将一个key对应很大的值存到不同的redis实例。

















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









