




 本文介绍使用Python的Pandas库进行数据转换的方法,包括样例数据构建、利用melt方法实现列转行、通过pivot方法完成行转列,并提供带有班级信息的完整示例。
本文介绍使用Python的Pandas库进行数据转换的方法,包括样例数据构建、利用melt方法实现列转行、通过pivot方法完成行转列,并提供带有班级信息的完整示例。
@创建于:2022.07.01
@修改于:2022.07.01
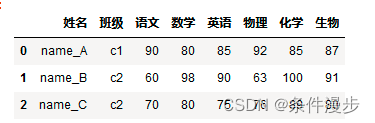
1、构建一个样例数据
import pandas as pd
import numpy as np
df = pd.DataFrame({'姓名': ['name_A', 'name_B', 'name_C'],
'班级': ['c1', 'c2', 'c2'],
'语文': [90, 60, 70],
'数学': [80, 98, 80],
'英语': [85, 90, 75],
'物理': [92, 63, 76],
'化学': [85,100, 89],
'生物': [87, 91, 80]})
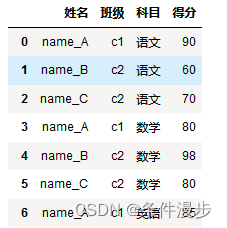
2、一行生成多行【列转行】
用到pandas的melt方法。
# 一行转多列
df_c = pd.melt(df, id_vars=['姓名', '班级'], var_name="科目", value_name="得分")
df_c
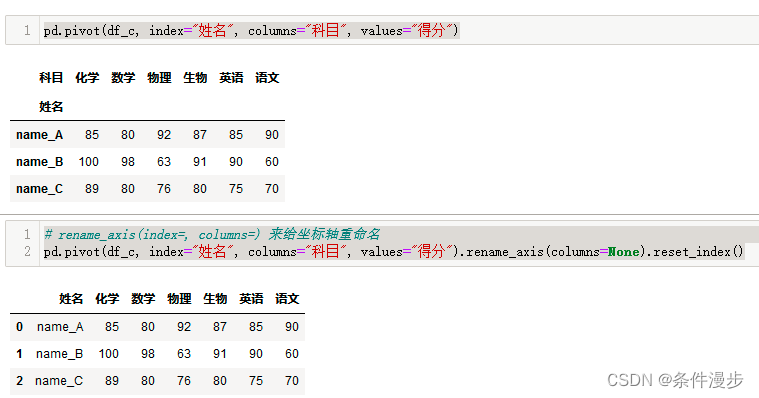
3、多行合并一行【行转列】
pd.pivot(df_c, index="姓名", columns="科目", values="得分")
# rename_axis(index=, columns=) 来给坐标轴重命名
pd.pivot(df_c, index="姓名", columns="科目", values="得分").rename_axis(columns=None).reset_index()
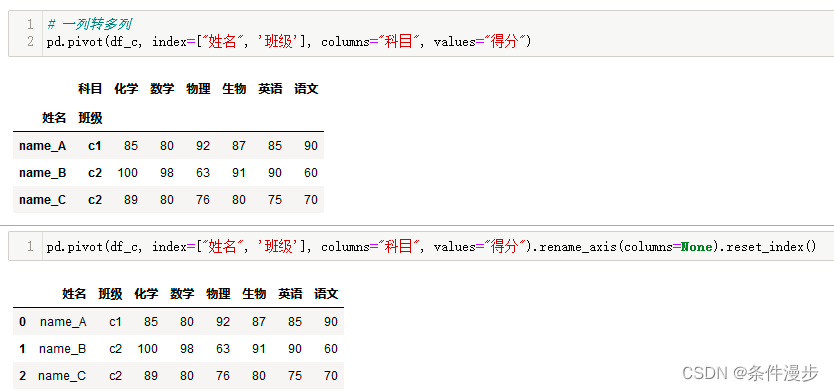
上面丢掉了班级,如何增加班级呢?
pd.pivot(df_c, index=["姓名", '班级'], columns="科目", values="得分").rename_axis(columns=None).reset_index()
4、参考链接
pandas行转列、列转行、以及一行生成多行
pandas如何进行优雅的列转行、行转列?
Pandas中Dataframe行转列

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









