




 本文介绍Apache Tika,一款强大的内容分析工具包,能够解析多种文档格式,包括Word、Excel、PDF及网页,轻松提取文本信息。通过Maven依赖集成,示例代码展示了如何使用Tika从不同类型的文件中抽取内容。
本文介绍Apache Tika,一款强大的内容分析工具包,能够解析多种文档格式,包括Word、Excel、PDF及网页,轻松提取文本信息。通过Maven依赖集成,示例代码展示了如何使用Tika从不同类型的文件中抽取内容。
Tika-内容分析工具包
在maven仓库下载最新版依赖 https://mvnrepository.com/artifact/org.apache.tika/tika-parsers
懒得去的同学,提供一个笔者正在使用的依赖
<!-- https://mvnrepository.com/artifact/org.apache.tika/tika-parsers -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.18</version>
</dependency>
提取url中的文字信息
public class TikaDemo {
public static void main(String[] args) throws IOException, TikaException {
Tika tika = new Tika();
String s = tika.parseToString(new URL("https://www.baidu.com"));
System.out.println(s);
}
}
输出结果:

提取word中的文字
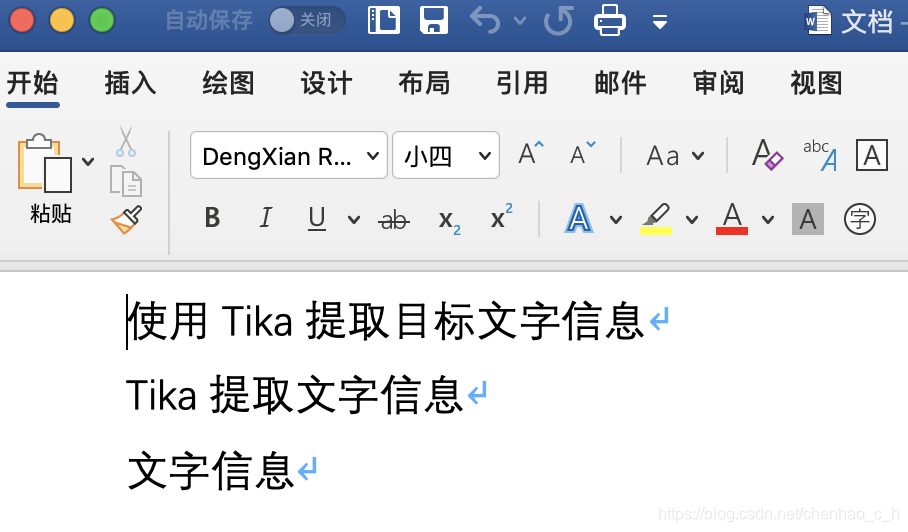
public class TikaDemo {
public static void main(String[] args) throws IOException, TikaException {
Tika tika = new Tika();
File file = new File("文档.docx");
String s = tika.parseToString(file);
System.out.println(s);
}
}
输出结果:

提取excel中的文字
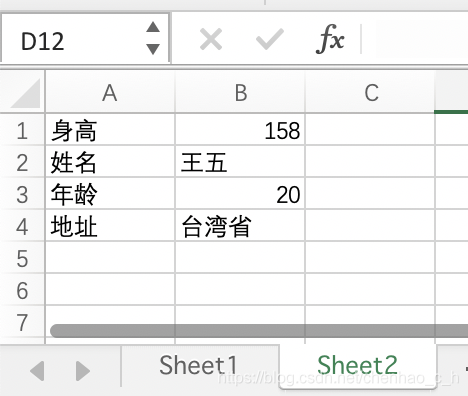
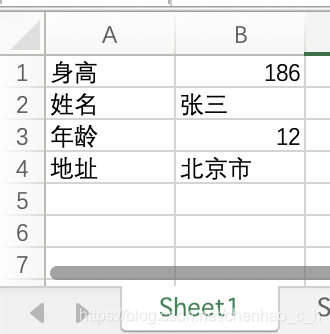
public class TikaDemo {
public static void main(String[] args) throws IOException, TikaException {
Tika tika = new Tika();
File file = new File("工作簿.xlsx");
String s = tika.parseToString(file);
System.out.println(s);
}
}
输出内容:

提取pdf文件中的文字

public class TikaDemo {
public static void main(String[] args) throws IOException, TikaException {
Tika tika = new Tika();
File file = new File("pdf文件.pdf");
String s = tika.parseToString(file);
System.out.println(s);
}
}输出结果:


















&spm=1001.2101.3001.5002&articleId=85049919&d=1&t=3&u=0e87cbb22e3243ceac729a2604d1e692)
 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









