




面试笔记
原则:回答比较抽象问题的时候,要举例说明
两者区别题 先说清楚一个,再来说另一个?
Java中有哪几种基本数据类型?
Java中有几种基本数据类型?8种
讲一下java中int数据占几个字节
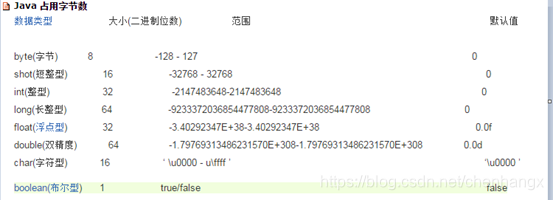
基本数据类型: 4类8种
`在内存中存放的是数据值本身(所占内存大小固定)
A:整数 占用字节数
byte 1
short 2
int 4
long 8 长整数值超过int型要加L或者l。
B:浮点型
float 4
double 8 单精度的浮点数超过float型要加F或者f。
C:字符
char 2 只能表示单字符(可以存储一个中文汉字:java语言中的字符占用两个字节)且必须使用单引号括起来
字符串常量是用""括起来的一串若干字符
D:布尔
boolean 1
Int占 4个字节,32位
Boolean 1位
面向对象的特征有哪些方面?
继承:(new dog) is (animal)一般类只能单继承,内部类实现多继承,接口可以多继承
封装:访问权限控制public > protected > 包 > private 内部类也是一种封装
多态:同一个对象在不同时刻体现出来的不同状态。
java多态,一个类可以实现多个接口! !
抽象: 就是把现实生活中的对象,抽象为类。
有了基本数据类型,为什么还需要包装类型?
包装类型:每一个基本的数据类型都会一一对应一个包装类型。
自动装箱和拆箱
Java是一个面向对象的语言,而基本的数据类型,不具备面向对象的特性。
"=="和equals方法究竟有什么区别?
非常经典的一个面试题?先说清楚一个,再来说另一个?
A:==
基本类型:比较的是值是否相同
引用类型:比较的是地址值是否相同
B:equals()
只能比较引用类型。默认情况下,比较的是地址值是否相同。
但是,我们可以根据自己的需要重写该方法。
equals 用来比较两个对象长得是否一样。判断两个对象的某些特征是否一样。实际上就是调用对象的equals方法进行比较。
讲一下String和StringBuilder的区别(final)?StringBuffer和StringBuilder的区别?
1.在java中提供三个类String StringBuillder StringBuffer来表示和操作字符串。字符串就是多个字符的集合。
String是内容不可变的字符串。String底层使用了一个不可变的字符数组(final char[])

String str =new String(“bbbb”);
而 StringBuillder StringBuffer,是内容可以改变的字符串。StringBuillder StringBuffer底层使用的可变的字符数组(没有使用final来修饰)
2.最经典就是拼接字符串。
1、String进行拼接.String c = “a”+”b”;
2、StringBuilder或者StringBuffer
StringBuilder sb = new StringBuilder(); sb.apend(“a”).apend(“b”)
拼接字符串不能使用String进行拼接,要使用StringBuilder或者StringBuffer
3.StringBuilder是线程不安全的,效率较高.而StringBuffer是线程安全的,效率较低。
讲一下java中的集合?
Java中的集合分为value,key–vale(Conllection Map)两种。
- 存储值(value)又分为List 和Set.
List是有序的,可以重复的。
Set是无序的,不可以重复的。根据equals和hashcode判断,也就是如果
一个对象要存储在Set中,必须重写equals和hashCode方法。
ArrayList和LinkedList的区别?
ArrayList底层使用时数组。LinkedList使用的是链表。
- 数组查询具有所有查询特定元素比较快。而插入和删除和修改比较慢(数组在内存中是一块连续的内存,如果插入或删除是需要移动内存)。
- 链表不要求内存是连续的,在当前元素中存放下一个或上一个元素的地址。查询时需要从头部开始,一个一个的找。所以查询效率低。插入时不需要移动内存,只需改变引用指向即可。所以插入或者删除的效率高。
ArrayList使用在查询比较多,但是插入和删除比较少的情况,而LinkedList使用在查询比较少而插入和删除比较多的情况。
HashMap的数据结构
《吊打面试官》系列-HashMap - 敖丙
HashMap常见面试题解析
- 1.7
数组加链表.数据节点是一个Entry节点 他的内部类
数据插入过程使用头插法[提升查找的效率] (可能会造成链表的循环下次Get是出现死循环)没有加锁 - 1.8
链表加数组加红黑树,Entry节点也变成了一个Node节点
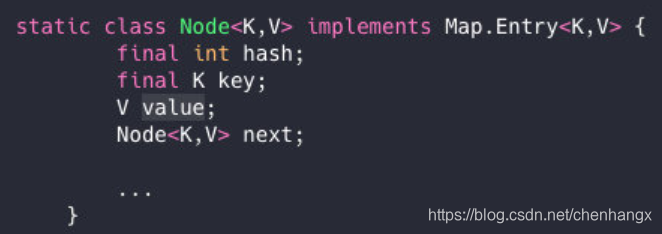
为啥改为尾部插入呢?
在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了 - 扩容机制
数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize
- 什么时候resize呢?
有两个因素:
Capacity:HashMap当前长度。(76/100)
LoadFactor:负载因子,默认值0.75f。

- 扩容?它是怎么扩容的呢?
扩容:创建一个新的Entry空数组,长度是原数组的2倍。
ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
- 为什么要重新Hash呢,直接复制过去不香么?
是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式---> index = HashCode(Key) & (Length - 1)
- HashMap的默认初始化长度是多少?为啥是16?

HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。 - 为啥我们重写equals方法的时候需要重写hashCode方法呢?
在java中,所有的对象都是继承于Object类。Ojbect类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
那里的 equals是比较两个对象的内存地址
HashMap是通过key的hashCode去寻找index的,那index一样就形成链表了,也就是说”杭歌“和”歌杭“的index都可能是2,在一个链表上的。
get的时候,他就是根据key去hash然后计算出index,找到了2,equals方法找到具体的”杭歌“和”歌杭“.建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
HashMap和HashTable的区别?HashTable和ConcurrentHashMap的区别?
相同点:HashMap和HasheTalbe都可以使用来存储key–value的数据。
区别:
1、HashMap是可以把null作为key或者value的,而HashTable是不可以的。
2、HashMap是线程不安全的,效率较高。而HashTalbe是线程安全的,效率较低。
HashTalbe直接在方法上锁,并发度很低
我想线程安全但是我又想效率高?
ConcurrentHashMap并发更高
通过把整个Map分为N个Segment(类似HashTable),可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
锁升级
无锁-(判断)-升级
讲一下线程的几种实现方式?
①实现方式?(哪4种)
callable接口与runnable接口的区别?
答:(1)是否有返回值
(2)是否抛异常
(3)落地方法不一样,一个是run,一个是call
FutureTask

②怎么启动?
thread.start();
启动线程使用start方法,而启动了以后执行的是run方法。
③怎么区分线程?在一个系统中有很多线程,每个线程都会打印日志,我想区分是哪个线程打印的怎么办?
thread.setName(“设置一个线程名称”); 这是一种规范,在创建线程完成后,都需要设置名称。
有没有使用过线程并发库
JUC
线程池:线程复用;控制最大并发数;管理线程。
Executos.newFixedThreadPool(int):一池N线程(不用)

线程池7个重要参数
工作中需要手写线程池
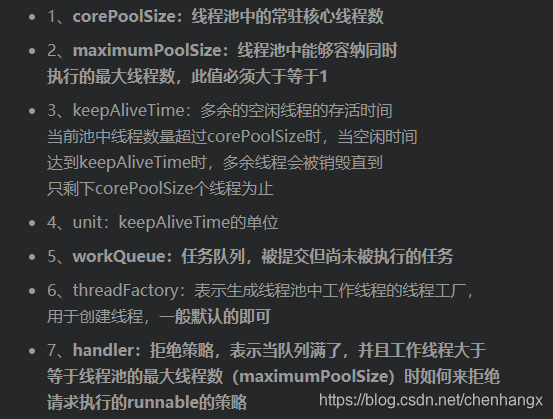
线程池底层工作原理
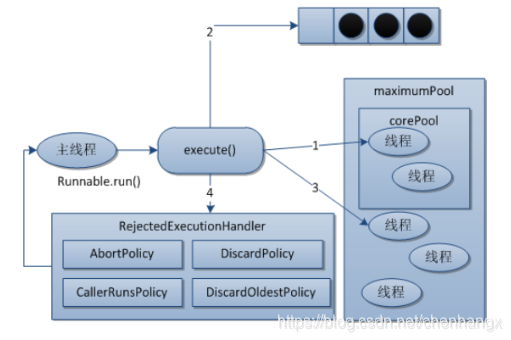
JDK内置的拒绝策略
以下内置拒绝策略均实现了RejectedExecutionHandle接口
讲一下什么是设计模式?常用的设计模式有哪些?
设计模式就是经过前人无数次的实践总结出的,设计过程中可以反复使用的、可以解决特定问题的设计方法。
单例(饱汉模式、饥汉模式)
1、构造方法私有化,让出了自己类中能创建外其他地方都不能创建
2、在自己的类中创建一个单实例(饱汉模式是一出来就创建创建单实例,而饥汉模式需要的时候才创建)
3、提供一个方法获取该实例对象**(创建时需要进行方法同步)**
工厂模式:Spring IOC就是使用了工厂模式.
对象的创建交给一个工厂去创建。
代理模式:Spring AOP就是使用的动态代理。
IO流
一个输入流的对象用int read()方法从流中读数据时,该方法的返回值()
int read(); //从输入流中读取单个字节数据(0~255),如到输入流末尾则返回-1
读取文本文件的时候,用字符流,如果用字节流可能会出现只读了半个字的情况,出现乱码~
- Java 基础
封装、继承、多态的使用
重载和重写的区别
Object 类下有哪些方法
HashCode、equal、==
String、StringBuiler、StringBuffer
自动拆箱与自动装箱(特别是 Integer) - Java 集合
HashMap 的所有知识(1.7、1.8、头插、尾插)
ConcurrentHashMap、HashTable、Collections.SynchronizedMap
LinkedList、ArrayList - 多线程
线程池的五大参数、执行原理、拒绝策略
Synchronized(作用于对象、代码块、方法)
Volatile(缓存行、可见性、重排序)
AQS(ReentranLock) - JVM
方法运行时的内存区域
双亲委派加载机制
垃圾回收算法与垃圾回收器 - 计算机网络
应用层:HTTP(1.0、1.1、2.0、HTTPS)、DNP
传输层:TCP(拥塞避免、滑动窗口、重传机制)、UDP
网络层:IPv4、IPv6、ICMP - 操作系统
进程与线程、几种状态
七种进程间通信(匿名管道、管道、信号、信号量、消息链表、共享内存、套接字)
分页和分段
CPU 调度算法(先来先服务、短作业优先、优先级调度、多级反馈队列调度)
- Redis
五大数据结构
Redis 持久化
缓冲雪崩、缓存穿透、双写一致性等等
内存淘汰机制 - Mysql
为什么使用 B+ 树做索引(与其他的数据类型做比较、红黑树、二叉平衡树、B树等等)
存储引擎(Innodb、MyIsam)
事务隔离级别、MVCC
SQL 优化(慢查询、各种索引理一遍)
由Object引出 两大类方法
一、equals和hashcode
1. 是否重写过这两个方法 -> 引出 hashmap hashset的底层原理(ok)
2. 重写过但是只知道对象比较的时候会用到,讲不清原理(勉强)
2. 重写过但是不知道为什么去重写(不行)
3. 没重写过(不行)
二、JVM
1. 内存模型
2. 垃圾回收机制
三、wait notify notifyAll -> 引出多线程相关问题(123必须知道,467可加分,5单独评判)
1. start方法和run方法有什么区别
2. 线程池的核心参数
3. 核心参数各司其职,流程怎么走
4. 为什么不推荐使用JDK定义好的线程池,推荐使用自定义线程池
5. 锁相关问题:sync和lock的区别 sync和volatile的区别(一点不知道不行)
6. 原子类
7. 线程协作工具:countdownlunch等
四、根据简历,对使用到的框架进行初步询问
1. Spring:
1.1 ioc aop概念(说得出原理 加分)
1.2 Bean生命周期(磕磕绊绊没关系,说得出加分)Bean 的作用域 5 默认单例
1.3 事务四大特性,隔离级别,传播属性
1.4 事务失效的场景
2. Mybatis
2.1 #{}和${}的区别(讲出拼接引号即可,讲出预编译的加分)
2.2 一级缓存 二级缓存 异同点(点出作用域就行,能讲出具体存放的数据结构存放在PerpetualCache中的hashmap加分)
2.3 延迟加载原理
3. 消息中间件 -> 消息丢失场景(可以不问)
hashmap的原理,hashcode相同的对象怎么存入hashmap的?hashmap的优点?
.spring 的后置处理器有哪些,有什么作用
spring 用到哪些设计模式
jsp由几部分组成
TreadLocal 线程并发

















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









