







今天工作上处理了一个现网问题
有一个大数据环境的yarn ui上的一个flink任务的Tracking URL打不开,点开报错http 500,并且Log Aggregation Status NOT_START
如下图所示可以查到相关任务状态
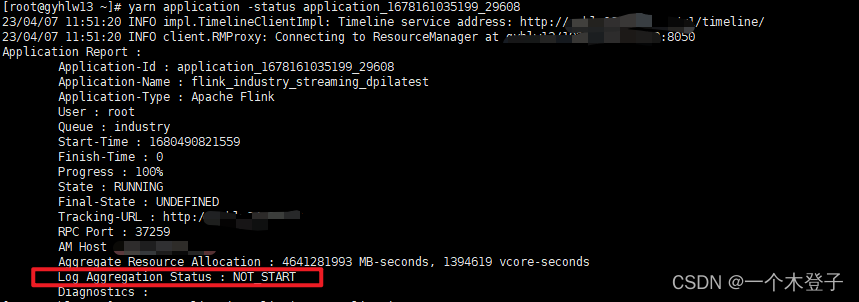
前端点进去是这样的报错

然后再后台用yarn命令查看一下日志和该进程在不在

很可惜也查不到,甚至还提示我Invalid ApplicationId specified,说这个id无效,可明明在列表运行
首先就是在网上查询相关报错的资料,发现都查不到 o(╥﹏╥)o
没办法,万事靠自己,先查了一下Log Aggregation Status是什么,发现是一个监控任务日志的工具,于是,一个想法蹦进了我的脑子,一顿操作猛如虎,问题解决了!!!!!
哈哈哈哈哈哈
下面说一下解决方法
1.先看一下该任务是在哪台服务器上运行的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8916
8916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









