







 本文介绍了SQL Server中处理字符串的基础和进阶技巧,包括ascii()、char()、ltrim()、rtrim()、substring()等函数的使用,并通过实例演示如何提取地址和号码,以及处理复杂字符串问题。同时,还讨论了如何将大写中文数字转换为小写。
本文介绍了SQL Server中处理字符串的基础和进阶技巧,包括ascii()、char()、ltrim()、rtrim()、substring()等函数的使用,并通过实例演示如何提取地址和号码,以及处理复杂字符串问题。同时,还讨论了如何将大写中文数字转换为小写。
前言:
要处理之前提及的,一些爬回来到数据库里面的大量!大量!大量的部分有逻辑的数据,要按照我们系统需要的格式进行处理。
先来看看是怎样的数据?又要处理成什么样数据?这里我把数据分类浓缩到一个表里,单独做展示,因为不可能拿原数据搞搞阵的啊。

是的,处理的数据大概如上面,要把它们分成地址和号码两列。
当然,数据量如上面那么少手动处理一下就好,但是数据有上万、上百万呢?
这里,我做了个取舍,因为还有很多其他无法完全考虑到的不规则数据,所以只对大批量可批次处理的数据进行整理,其余的就只好筛选出来后期进行手工处理了。
一、关于字符串处理函数(基础)
涉及数据处理,脑袋中首先就想到了:
left()/right()、ltrim()/rtrim()、replace()、substring()、cast()、convert()…
当然,还有很多函数,以上几个只是我平时处理数据库数据时,比较常用到的一些字符串处理函数而已。
现在就由此展开稍作整理记录。
1、字符转换函数
- ascii()和char()
ascii():将字符转换为对应ascii码
char():将ascii码转换为对应字符
select ascii('c') --c的ASCII码:99
select ascii(',') --逗号的ASCII码:44
select ascii(99) --99的ASCII码:57
select char(0) --0ascii码对应的字符:
select char(128) --128ascii码对应的字符:€
select char(129) --129ascii码对应的字符:NULL
char()的范围为0-128,不在范围内则返回null- unicode()和nchar
和ascii()、char()的用法是相似的。
unicode():将字符转换为对应ascii码
nchar():将ascii码转换为对应字符
select unicode('c') --a的ASCII码:99
select unicode(',') --逗号的ASCII码:44
select unicode(99) --99的ASCII码:57
select nchar(0) --0ascii码对应的字符:
select nchar(65535) --128ascii码对应的字符:
select nchar(65536) --129ascii码对应的字符:NULL
nchar()的范围为0-65535,不在范围内则返回null- lower()和upper()
lower(字符串):将大写英文字符转换为小写
upper(字符串):将小写英文字符转换为大写
select lower('XUEJIE') --xuejie
select lower('九十九A') --九十九a
select upper('xuejie') --XUEJIE
select upper('99a') --99A
仅限英文大小写转换- str()
str(字符串,指定的长度,小数位数):把数值按指定的长度和小数位数返回
select str(3.1415926,10) --【 3】字符串整数位小于指定长度10,左边补足9个空格
select str(233.1415926,1) --【*】
select str(2333333,4,3) --【****】当字符串整数位大于指定长度时,指定长度为多少,返回多少个*
select str(233.1415926,6,-3) --【NULL】
select str(233.1415926,-6,3) --【NULL】当指定的长度值或小数位数值为负数时,返回null
select str(3.1415926,1) --【3】正确的使用范例
select str(233.1415926,6,3) --【233.14】正确的使用范例
2、空格去除函数
- ltrim()和rtrim()
ltrim(字符串):去掉字符串左边的所有空格
rtrim(字符串):去掉字符串右边的所有空格
select ' 处理左边空格' --【 处理左边空格】
select ltrim(' 处理左边空格') --【处理左边空格】
select '处理右边空格 ' --【处理右边空格 】
select rtrim('处理右边空格 ') --【处理右边空格】3、从字符串中截取子字符串函数
- left()和right()
left(字符串,截取指定长度):从字符串左边第一位开始截取指定长的的字符串
right(字符串,截取的长度):从字符串右边第一位开始截取指定长的的字符串
select left('233.1415926',3) --233
select left('233.1415926',-3) --传递到 left 函数的长度参数无效
select right('233.1415926',3) --926
select right('233.1415926',-3) --传递到 right 函数的长度参数无效
- substring()
substring(字符串,截取的起始位置,截取的长度):从字符串左边指定的截取起始位置,开始截取指定长的的字符串
select substring('233.1415926',4,3) --.14
select substring('233.1415926',0,1) --
select substring('233.1415926',-1,5) --233
substring()用得好,没有你截不到,只有你想不到。
等一下也是会用到这个函数进行我的数据处截取4、子字符串位置获取函数
- charindex()和patindex()
charindex(子字符串,母字符串):找出子字符串在母字符串中出现的开始位置
patindex(带通配符的子字符串,母字符串):找出带通配符的子字符串在母字符串中出现的开始位置
select charindex('e','chenxuejie') --3
select charindex('E','chenxuejie') --3
select patindex('e','e') --1
select patindex('e','chenxuejie') --0 子字符串和母字符串完全一样返回1,否则返回0
select patindex('%e%','chenxuejie') --3 e字符前后模糊查询
select patindex('e%','chenxuejie') --0 以e字符开始,后面模糊查询
select patindex('%e','chenxuejie') --10 以e字符结束,前面模糊查询
select patindex('%[cxj]%','chenxuejie') --1 []中任意一个字符只要在母字符串中出现,返回第一次出现的位置
select patindex('%[^cxj]%','chenxuejie') --2 [^]除去括号中字符,其他任意字符在母字符串中出现,返回第一次出现的位置
划重点,patindex()函数可以很好地解决本次我的问题。
用通配符,从一堆中、英、数、符号参杂的字符串中取出数字混合字母的号码。5、字符串操作函数
- replace()
replace(字符串,被替换字符串,替换字符串)
select replace('chenxuejie','chen','') --xuejie
select replace('chenxuejie','cccc','xxx') --chenxuejie- reverse()
reverse(字符串):将字符串的顺序颠倒
select reverse(123) --321
select reverse('!a陈@#') --#@陈a!- replicate()
replicate(字符串,重复的次数n):按照重复的次数值将字符串重复n次
select replicate('chen',3) --chenchenchen
select replicate('chen',0) --
select replicate('chen',-3) --NULL- quotename()
quotename(字符串,字符括号)
select quotename(123,'[]') --[123]
select quotename(123,'【】') --NULL 符号只能为英文字符,否则返回null
select quotename('chen','''') --'chen'
select quotename('chen') --[chen] 默认为[]- space()
space(数值):返回指定数值长的的空格
select space(10) --【 】
select space(-10) --NULL- stuff()
stuff(字符串,截取的初始位置,截取的长度,替换字符串)
其实这个和replace()差不多,只不过replace()不可以按照位置截取指定的字符串。
select stuff('chenxuejie',5,6,'123') --chen123
select stuff('chenxuejie',5,0,'123') --chen123xuejie
select stuff('chenxuejie',11,6,'123') --NULL 截取的初始位置不能超出字符串长度
select stuff('chenxuejie',-1,6,'123') --NULL6、数据类型的转换函数
- cast()
cast(字符串 as 转换为于与字符串数据类型相同的类型)
我一般是用在整数转为小数,或者小数要保留小数点后几位数
select cast(141592 AS int) --141592
select cast(141 AS decimal(9,2)) --141.0000
select cast('3.1415926' AS decimal(9,2)) --3.14
select cast('3.1415926' AS int) --在将 varchar 值 '3.1415926' 转换成数据类型 int 时失败。- convert()
我一般都是用这个将日期转换为字符串截取需要的日期格式
select convert(varchar(10),getdate(),120) --2020-04-09
select convert(varchar(7),getdate(),120) --2020-047、日期获取函数
- year()/month()/day()
日期字符串中年/月/日的获取
select year('2020-04-09') --2020
select month('2020-04-09') --4
select day('2020-04-09') --9- datepart()/ datename()
这两个和上面year()/month()/day()差不多,也可以按年/月/日返回值,不过datepart()/ datename()指定返回的值类型
datepart(year/yy/month/mm/day/dd,字符串)
datename(year/yy/month/mm/day/dd,字符串)
--以整数值的形式返回日期
select datepart(yy, '2020-04-09 02:43:18.587') --2020
select datepart(mm, '2020-04-09 02:43:18.587') --4
select datepart(dd, '2020-04-09 02:43:18.587') --9
--以字符串的形式返回日期
select datename(yy, '2020-04-09 02:43:18.587') --2020
select datename(mm, '2020-04-09 02:43:18.587') --04
select datename(dd, '2020-04-09 02:43:18.587') --9- getdate()
获取系统当前的精确时间
select getdate() --2020-04-09 02:43:18.587- dateadd()
date(year/yy/month/mm/day/dd,时间添加/减少的数值,字符串):在指定日期添加/减少相应的年/月/日数值
select dateadd(year,-1,'2020-04-09 02:43:18.587') --年+1:2019-04-09 02:43:18.587
select dateadd(month,1,'2020-04-09 02:43:18.587') --月+1:2020-05-09 02:43:18.587
select dateadd(day,1,'2020-04-09 02:43:18.587') --日+1:2020-04-10 02:43:18.587- datediff()
datediff(year/yy/month/mm/day/dd,日期1,日期2):获取两个日期之间间隔的年/月/日数量值
--一般来说都是小日期在前,不然会产生负值
select datediff(yy,'2020-04-09','2030-12-12') --10
select datediff(mm,'2020-04-09','2020-12-12') --8
select datediff(dd,'2020-04-09','2020-04-12') --3二、字符串处理进阶
上面介绍了一些关于处理字符串的函数的最基础用法,而要想处理复杂的字符串时,往往需要将多个基础函数合并使用。
下面就以处理我上面的数据作为例子,组合这些基础函数来达到我想要的处理效果。
三十二栋101号
三十二幢12楼1201
三十二座12楼三单元1203房
1205号
1206
1栋0105
三十二座
三十二幢12楼2B
32号楼1梯A
32号楼1梯A、23B、33C号
32号楼1梯2单元201、202、203
???如上面的数据,我要怎么处理出地址和号码两列呢?
可以这样啊!所有数据中取出最后一个数字,然后按照取出来的数字再截取该数字前面的字符串,这样不就分为地址和号码了吗!(机智如我)
至于…像这种【32号楼1梯2单元201、202、203】后面连带几个号码的地址,就后期再特殊处理咯,因为要的也是单一的号码而已,有多个的话要另外新增一行作为新的地址数据。
摩拳擦掌、跃跃欲试~
1、最后一个号码的提取
- SQL
以【32号楼1梯A、23B、33C号】取出33C为例
--顺序颠倒
select reverse('32号楼1梯A、23B、33C号')
返回:号C33、B32、A梯1楼号23
--取出33C的开始位置
select PATINDEX('%[a-zA-Z0-9]%',reverse('32号楼1梯A、23B、33C号'))
返回:2
--从颠倒的字符串第一位到33C,将需要的号码以外的字符用''替换,即确保是以你要的号码开头
select STUFF(reverse('32号楼1梯A、23B、33C号'),1,PATINDEX('%[a-zA-Z0-9]%',reverse('32号楼1梯A、23B、33C号') )-1,'')
返回:C33、B32、A梯1楼号23
--从第一位开始截取出号码C33,截取长度为非所要号码开始的位置长度,即除C33之外,到【、】,为第四位
select SUBSTRING(
STUFF(reverse('32号楼1梯A、23B、33C号'),1,PATINDEX('%[a-zA-Z0-9]%',reverse('32号楼1梯A、23B、33C号') )-1,''),
0,
PATINDEX('%[^a-zA-Z0-9]%',STUFF(reverse('32号楼1梯A、23B、33C号'),1,PATINDEX('%[a-zA-Z0-9]%',reverse('32号楼1梯A、23B、33C号') )-1,''))
)
返回:C33
--将截取出来的C33颠倒,即为33C
select REVERSE(
SUBSTRING(
STUFF(reverse('32号楼1梯A、23B、33C号'),1,PATINDEX('%[a-zA-Z0-9]%',reverse('32号楼1梯A、23B、33C号') )-1,''),
0,
PATINDEX('%[^a-zA-Z0-9]%',STUFF(reverse('32号楼1梯A、23B、33C号'),1,PATINDEX('%[a-zA-Z0-9]%',reverse('32号楼1梯A、23B、33C号') )-1,''))
)
)
返回:33C
如果是要截取第一个号码,大致思路也是一样的,就是不用再用reverse()去将字符串颠倒了。
将截取第一个号码/最后一个号码的方法写成函数,传入字符串进行处理。
- 标量值函数[dbo].[substring_firstorlast]
-- =============================================
-- Author: chenxuejie
-- Create date: 2019-04
-- Description: 截取字符串中出现的第一个/最后一个数字,
--传入参数1取最后一个号码,传入参数0取第一个出现的号码
-- =============================================
CREATE FUNCTION [dbo].[substring_firstorlast]
(
@string VARCHAR(max),
@firstorlast INT
)
RETURN VARCHAR(max)
as
BEGIN
DECLARE @return_sub VARCHAR(max) --截取出来的字段
DECLARE @return_col VARCHAR(max) --对截取出来的字段二次赋值,再进行去除中文处理的字段
IF @firstorlast=1 --最后一个数字
SET @return_sub=
REVERSE(
SUBSTRING(
STUFF(reverse(@string),1,PATINDEX('%[a-zA-Z0-9]%',reverse(@string) )-1,''),
0,
PATINDEX(
'%[^a-zA-Z0-9]%',
STUFF(reverse(@string),1,PATINDEX('%[a-zA-Z0-9]%',reverse(@string) )-1,'')
)
)
)
ELSE--第一个数字
SET @return_sub=
SUBSTRING(
STUFF(@string,1,PATINDEX('%[a-zA-Z0-9]%',@string)-1,''),
0,
PATINDEX(
'%[^a-zA-Z0-9]%',
STUFF(@string,1,PATINDEX('%[a-zA-Z0-9]%',@string)-1,'')
)
)
--RETURN @return_sub
/*
但是,上面的函数还是会对一些纯号码/号码开头/中文/符号的字符串的处理存在一些问题
SELECT [dbo].[substring_firstorlast]('1205号',1) --【空】
SELECT [dbo].[substring_firstorlast]('1206',1) --【空】
SELECT [dbo].[substring_firstorlast]('三十二座',1) --null
SELECT [dbo].[substring_firstorlast]('???',1) --null
所以,在下面加多一段对这些特殊字符串的判断处理,这时要将上面的返回注释掉
*/
--当截取出来的字段为''时,将值置为原本的字符串
--因为如果字符为串纯号码/号码开头/中文/符号......的话无法截取出纯数字:如1205号/1206/三十二座/???,会变为''/nul
--所以这种情况就返回原本的@string,返回:1205号/1206/三十二座/???
IF (@return_sub='0' or @return_sub='' or @return_sub is null )
SET @return_col =@string
ELSE
SET @return_col =@return_sub
--RETURN @return_col
--像1205号这种还能拯救一下
--去除截取到的@return_sub中的中文,这样三十二座/中文符号就会都返回空值,就这样吧,总要做取舍,尽我所能了
DECLARE @len INT --做循环的变量从1开始
DECLARE @return_real VARCHAR(max) --最终返回的值
SELECT @return_real = '',
@len = 1;
WHILE( @len <= LEN(@return_col))--当@len大于截取出来的字符串@return_col的长度时,跳出循环
BEGIN
IF( ASCII(SUBSTRING(@return_col, @len, 1)) < 122 )
SET @return_real = @return_real + SUBSTRING(@return_col, @len, 1);
SET @len = @len + 1;
END;
--RETURN CONVERT(INT,@returnInt_real)
RETURN @return_real--不能返回整型,因为号码有A/B/C......
end
- 验收一下
update deal_with_substring
set need_deal_number=[dbo].[substring_firstorlast](py_info,1)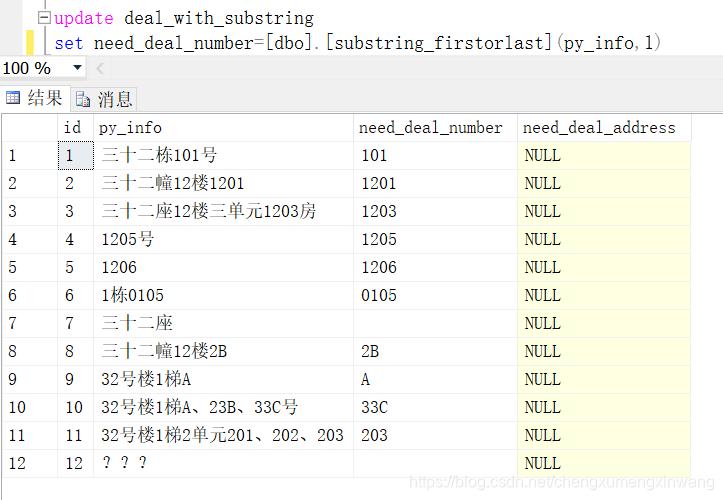

2、号码前地址的截取
难的解决了,这个就很简单啦~
update deal_with_substring
set need_deal_address=replace( py_info,substring(py_info,charindex(need_deal_number,py_info),500),'' )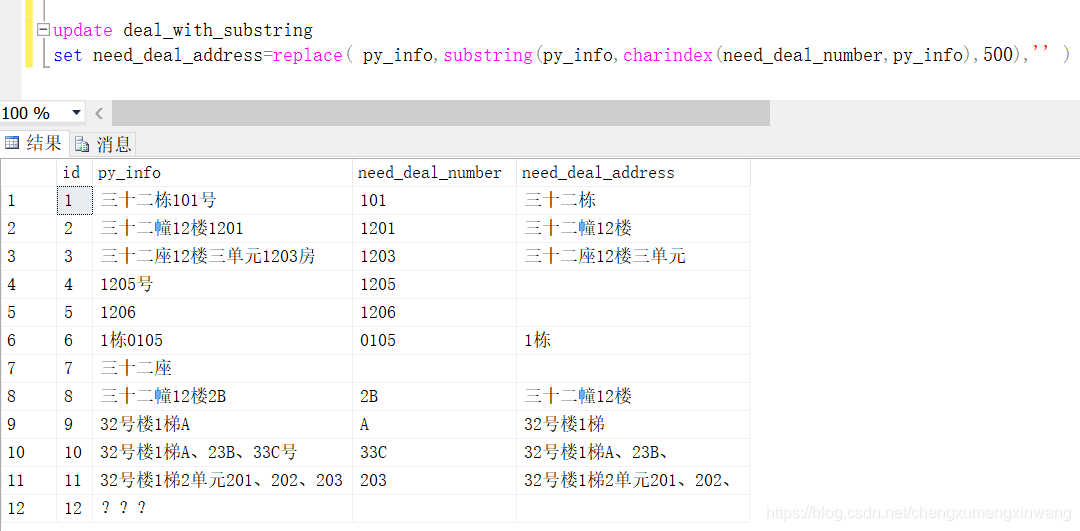
给自己鼓个掌~

3、然鹅…事情还没完…
又和我说需要先把大写的中文数字全部转换成小写,然后再处理…
如【三十二栋101号】变为【32栋101号】

不过,脑海中突然蹦出一个思路,可以先把十、百、千、万、这种单位的字符先替换为空,然后再一一把大写数字替换成小写,如:一替换为1、二替换为2…
就不展示了,碎觉!头发要紧…
三、结束!
以上就是对需要处理的数据,我能想到小方法了,还有更好的方法的话cue一下~互相学习!
好了,【SQL】SQL server关于字符串处理的十八般武艺,记录完毕,打板!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









