









1.机器配置及实验说明
基于前期搭建的双卡机器装机教程,配置如下:
| 硬件名称 | 参数 | 备注 |
|---|---|---|
| CPU | E5-2680V42 *2(线程28个) | 无 |
| GPU | 2080TI-22G 双卡 | 魔改卡 |
| 系统 | WSL Unbuntu 22.04.5 LTS | 虚拟机 |
本轮实验目的:基于VLLM/Ollama/ktransformers框架完成Deepseek大模型私有化部署,了解如何搭建大模型推理服务。
2.大模型推理框架介绍及实战
2.1 推理框架介绍
目前大模型推理框架主要包含VLLM/SGLang/ollama/ktransformer等框架,如下是各个框架的介绍:
-
VLLM:是UC Berkeley大佬Ion Stoica组开源的大模型推理引擎。其在2023.6.20首次发布,为了实现快速推理,经过特别优化,具有高服务吞吐量,使用pagedAttention的有效注意力内存管理。连续批处理和优化的CUDA内核,此外还支持各种解码算法、张量并行和流式输出,支持huggingface模型格式,提供兼容OpenAI的API接口官网链接

-
SGLang:是一个对标vLLM的大语言模型推理框架, 系统的整体架构如下图,分为前端和后端。 前端是对调用大语言模型的一些常用操作的抽象,提供一系列原语。 后端是具体的对推理过程的优化。 SGLang的两点主要的优化是RadixAttention和Structured output。在此基础之上,作为大模型推理的基础框架, 后续也有很多其他的系统优化工作是在SGLang框架上的。官网链接

-
ollama:是一个简明易用的本地大模型运行框架,只需一条命令即可在本地跑大模型。开源项目,专注于开发和部署先进的大型语言模型(LLM)官网链接,支持guff模型格式

-
KTransfomers:是一个由清华大学KVAV.AI团队开发的开源项目,旨在优化大语言模型(LLM)的推理性能,特别是在有限显存资源下运行大型模型。支持huggingface模型格式和guff的格式。

2.2 VLLM部署Deepseek大模型
为了方便快速部署,本轮实验采用Deepseek蒸馏模型(DeepSeek-R1-Distill-Qwen-1.5B),可以从huggingface社区或者modelscope进行下载
步骤一:模型下载
- 国外下载链接:https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
- 国内下载链接:https://hf-mirror.com/deepseek-ai
- git方式下载:
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
步骤二:安装VLLM
需要注意的是,安装vllm有比较多的依赖,例如torch环境、cuda版本等
(1)nvcc -V 版本和nvidia-smi版本保持一致:

驱动报错:

cmake报错:
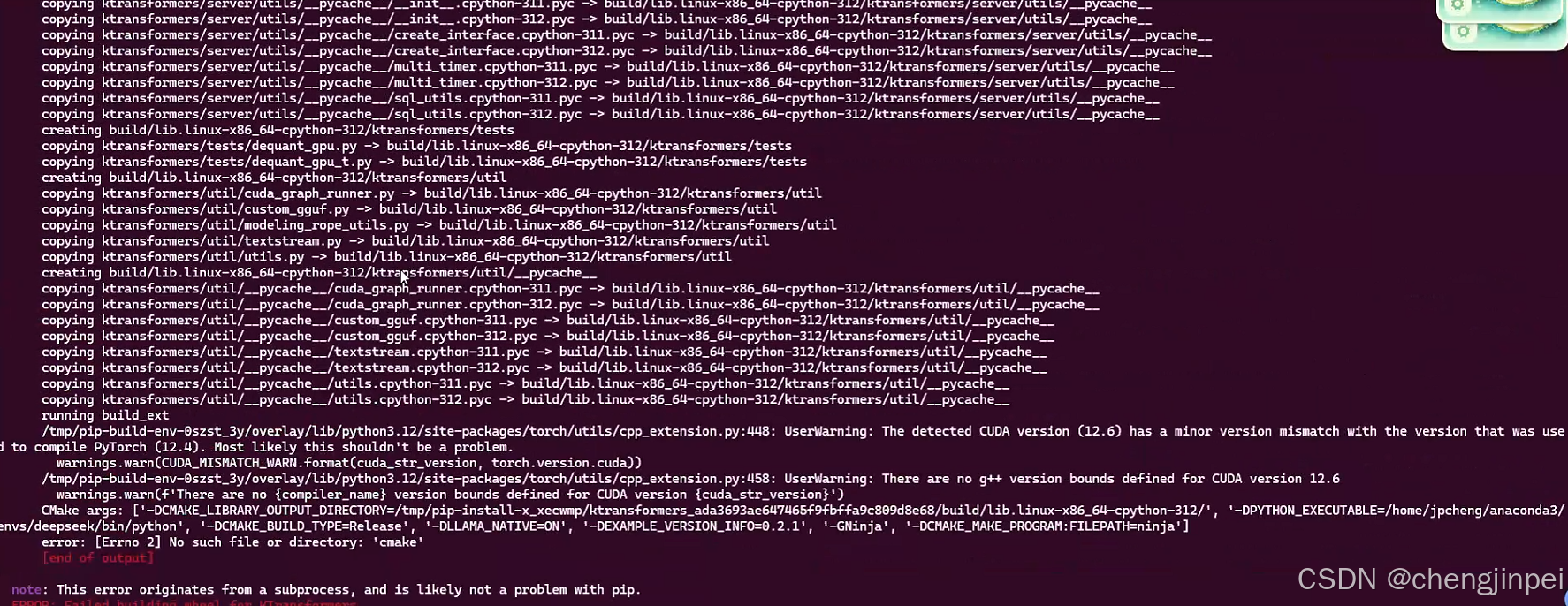
(2)torch版本依赖:安装vllm之前,虚拟环境中一定要有pytorch环境,否则会报错,这里建议部署的时候,新建环境,python和torch都安装最新版本,出错概率会小一些,否则会报如下错误:
```python
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [6 lines of output]
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/tmp/pip-install-sa81j1_y/xformers_5701c77d28094ba6bffdabe8c9ba5779/setup.py", line 24, in <module>
import torch
ModuleNotFoundError: No module named 'torch'
【错误分析】环境中未安装pytorch,按照驱动版本安装相应pytorch版本即可:

有时候还会遇到如下错误:
Please install it with "pip install transformers[torch]'

【错误解析】python的版本较老,对于一些新的模型不兼容,建议重建虚拟环境进行最新版本安装
(3)Xformer版本的依赖
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
torchvision 0.20.1+cu124 requires torch==2.5.1, but you have torch 2.6.0 which is incompatible.
【错误解析】Xformer版本与torch有强烈依赖关系,安装之前需要下载对应版本

对应关系可以参考xfomers官网链接
(4)安装VLLM

步骤三:配置模型,启动服务
(1)配置启动模型及配置sh 脚本
#启动时需要将注释内容删除,且对空格比较敏感
python -m vllm.entrypoints.openai.api_server \
--model /mnt/e/NLP/deepseek/DeepSeek-R1-Distill-Qwen-1.5B \ #模型存放绝对路径
--served-model-name deepseek-qwen-1.5b \ # 配置的服务名称
--dtype=half \ #精度
--tensor-parallel-size 1 \ # 并行tensor
--max-model-len 1000 \ #最大模型长度
--trust-remote-code \
--gpu-memory-utilization 0.9 #gpu的利用率
(2)启动脚本 sh start.sh


模型占用显存:

(3)调用模型服务:
curl -X POST "http://localhost:8000/v1/chat/completions" -H "Content-Type: application/json" --data '{
"model": "deepseek-qwen-1.5b",
"messages": [
{
"role": "user",
"content": "你是谁?"
}
]
}'
返回结果

2.3 ollama部署Deepseek大模型
步骤一:下载ollama
(1)网络下载:
curl -fsSL https://ollama.com/install.sh -o ollama_install.sh

(2)安装ollama


步骤二:下载Deepseek模型
ollama run deepseek-r1:1.5b

步骤三:模型测试

2.4 Ktransformer部署Deepseek大模型
步骤一:克隆仓库
git clone https://github.com/kvcache-ai/ktransformers.git

步骤二:安装ktransfomers库
pip install KTransformers -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simplesome-package
步骤三:启动模型
ktransformers --type transformers --model_path /mnt/e/NLP/deepseek/DeepSeek-R1-Distill-Qwen-1.5B


步骤四:测试模型接口
curl -X POST "http://localhost:10002/v1/chat/completions" -H "Content-Type: application/json" --data '{
"model": "deepseek-qwen-1.5b",
"messages": [
{
"role": "user",
"content": "你是谁?"
}
]
}'
返回结果:


















 189
189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









