




expand函数
395 static inline struct page *
396 expand(struct zone *zone, struct page *page,
397 int low, int high, struct free_area *area)
398 {
399 unsigned long size = 1 << high;
400
401 while (high > low) {
402 area--;
403 high--;
404 size >>= 1;
405 BUG_ON(bad_range(zone, &page[size]));
406 list_add(&page[size].lru, &area->free_list);
407 area->nr_free++;
408 set_page_order(&page[size], high); //把page+size对应的PG_private和private置位
409 }
410 return page;
411 }
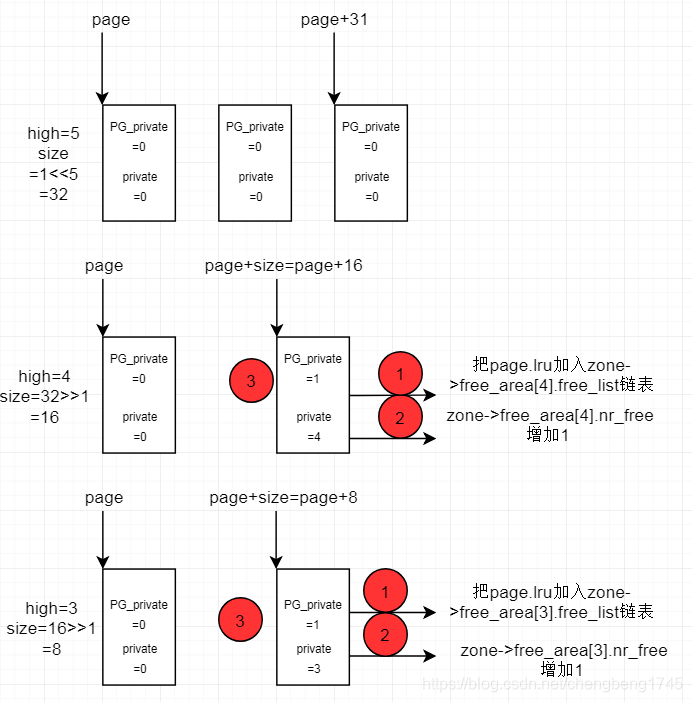
说明:
1)如果high=low,则不会执行,直接返回之前从buddy系统分配,要求low,并且buddy系统中也有low大小的块。则直接返回之前分配的page。
2)如果high>low,举了想申请order=3的块,现在只有order=5的块
算法核心:
1.分配到一个大内存,切成两个相等的内存(也就是降1阶),后面一块内存加入到zone中的free_area相应order链表中。
2. 这样递归下去,知道请求内存low大小,一半放到buddy系统中,一半给请求者。
如上图:
1)红色框的第1步,就是list_add(&page[size].lru, &area->free_list);
2)红色框的第2步,就是area->nr_free++;
2)红色框的第3步,就是 set_page_order(&page[size], high);
__rmqueue函数
459 static struct page *__rmqueue(struct zone *zone, unsigned int order)
460 {
461 struct free_area * area;
462 unsigned int current_order;
463 struct page *page;
464
465 for (current_order = order; current_order < MAX_ORDER; ++current_order) {
466 area = zone->free_area + current_order;
467 if (list_empty(&area->free_list))
468 continue;
469
470 page = list_entry(area->free_list.next, struct page, lru);
471 list_del(&page->lru);
472 rmv_page_order(page);
473 area->nr_free--;
474 zone->free_pages -= 1UL << order;
475 return expand(zone, page, order, current_order, area);
476 }
477
478 return NULL;
479 }
两个主要工作:
-
从zone中分得一个大于或者等于order大小的内存块
1.1 从请求order块开始,看相应的zone中free_area对应的order块链表是否空闲,如果当前没有,增加order块大小,直到MAX_ORDER。 -
把这个内存块从buddy系统去除
2.1 把page->lru从zone中的free_area中的链表去除,zone中的free_area中的nr_free减1
2.2 清除page的PG_private和private
2.3 zone中的free_pages减1 -
如果请求内存小于从buddy取出的内存,进行切割
expand函数,进行这个操作
buffered_rmqueue函数
645 static struct page *
646 buffered_rmqueue(struct zone *zone, int order, int gfp_flags)
647 {
648 unsigned long flags;
649 struct page *page = NULL;
650 int cold = !!(gfp_flags & __GFP_COLD);
651
652 if (order == 0) {
653 struct per_cpu_pages *pcp;
654
655 pcp = &zone->pageset[get_cpu()].pcp[cold];
656 local_irq_save(flags);
657 if (pcp->count <= pcp->low)
658 pcp->count += rmqueue_bulk(zone, 0,
659 pcp->batch, &pcp->list);
660 if (pcp->count) {
661 page = list_entry(pcp->list.next, struct page, lru);
662 list_del(&page->lru);
663 pcp->count--;
664 }
665 local_irq_restore(flags);
666 put_cpu();
667 }
668
669 if (page == NULL) {
670 spin_lock_irqsave(&zone->lock, flags);
671 page = __rmqueue(zone, order);
672 spin_unlock_irqrestore(&zone->lock, flags);
673 }
674
675 if (page != NULL) {
676 BUG_ON(bad_range(zone, page));
677 mod_page_state_zone(zone, pgalloc, 1 << order);
678 prep_new_page(page, order);
679
680 if (gfp_flags & __GFP_ZERO)
681 prep_zero_page(page, order, gfp_flags);
682
683 if (order && (gfp_flags & __GFP_COMP))
684 prep_compound_page(page, order);
685 }
686 return page;
687 }
说明:
1)如果order等于0,则使用每CPU页框高速缓存。
2)如果order不等于0,则从buddy系统分配内存。
3)函数就初始化(第一个)页框的页描述符
3.1 将第一个页清除一些标志,将private字段置0
3.2 将这个order所有的页的_count置为逻辑1。(就是从page到page+order-1)

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









