






 本文深入解析 Sizzle 的核心机制,包括复杂的 CSS 选择器解析流程、属性映射、过滤器等关键技术点,并探讨如何利用浏览器特性提高查找效率。
本文深入解析 Sizzle 的核心机制,包括复杂的 CSS 选择器解析流程、属性映射、过滤器等关键技术点,并探讨如何利用浏览器特性提高查找效率。
今天我开始攻略jQuery的心脏,css选择器。不过Sizzle是如此复杂的东西,我发现不能跟着John Resig的思路一行行读下去,因此下面的代码和jQuery的次序是不一样的。
jQuery的代码是包含在一个巨大的闭包中,Sizzle又在它里面开辟另一个闭包。它是完全独立于jQuery,jQuery通过find方法来调用Sizzle。一开始是这几个变量,尤其是那个正则,用于分解我们传入的字符串
var chunker = /((?:/((?:/([^()]+/)|[^()]+)+/)|/[(?:/[[^[/]]*/]|['"][^'"]*['"]|[^[/]'"]+)+/]|//.|[^ >+~,(/[//]+)+|[>+~])(/s*,/s*)?/g,
done = 0,
toString = Object.prototype.toString;
然后我们看其表达式,用于深加工与过滤以及简单的查找:
//@author 司徒正美|なさみ|cheng http://www.cnblogs.com/rubylouvre/ All rights reserved
var Expr = Sizzle.selectors = {
order: [ "ID", "NAME", "TAG" ],
match: {
ID: /#((?:[/w/u00c0-/uFFFF_-]|//.)+)/,
CLASS: //.((?:[/w/u00c0-/uFFFF_-]|//.)+)/,
NAME: //[name=['"]*((?:[/w/u00c0-/uFFFF_-]|//.)+)['"]*/]/,
ATTR: //[/s*((?:[/w/u00c0-/uFFFF_-]|//.)+)/s*(?:(/S?=)/s*(['"]*)(.*?)/3|)/s*/]/,
TAG: /^((?:[/w/u00c0-/uFFFF/*_-]|//.)+)/,
CHILD: /:(only|nth|last|first)-child(?:/((even|odd|[/dn+-]*)/))?/,
POS: /:(nth|eq|gt|lt|first|last|even|odd)(?:/((/d*)/))?(?=[^-]|$)/,
PSEUDO: /:((?:[/w/u00c0-/uFFFF_-]|//.)+)(?:/((['"]*)((?:/([^/)]+/)|[^/2/(/)]*)+)/2/))?/
},
attrMap: {//一些属性不能直接其HTML名字去取,需要用其在javascript的属性名
"class": "className",
"for": "htmlFor"
},
attrHandle: {
href: function(elem){
return elem.getAttribute("href");
}
},
relative: {
//相邻选择符
"+": function(checkSet, part, isXML){
var isPartStr = typeof part === "string",
isTag = isPartStr && !//W/.test(part),
isPartStrNotTag = isPartStr && !isTag;
if ( isTag && !isXML ) {
part = part.toUpperCase();
}
for ( var i = 0, l = checkSet.length, elem; i < l; i++ ) {
if ( (elem = checkSet[i]) ) {
while ( (elem = elem.previousSibling) && elem.nodeType !== 1 ) {}
checkSet[i] = isPartStrNotTag || elem && elem.nodeName === part ?
elem || false :
elem === part;
}
}
if ( isPartStrNotTag ) {
Sizzle.filter( part, checkSet, true );
}
},
//亲子选择符
">": function(checkSet, part, isXML){
var isPartStr = typeof part === "string";
if ( isPartStr && !//W/.test(part) ) {
part = isXML ? part : part.toUpperCase();
for ( var i = 0, l = checkSet.length; i < l; i++ ) {
var elem = checkSet[i];
if ( elem ) {
var parent = elem.parentNode;
checkSet[i] = parent.nodeName === part ? parent : false;
}
}
} else {
for ( var i = 0, l = checkSet.length; i < l; i++ ) {
var elem = checkSet[i];
if ( elem ) {
checkSet[i] = isPartStr ?
elem.parentNode :
elem.parentNode === part;
}
}
if ( isPartStr ) {
Sizzle.filter( part, checkSet, true );
}
}
},
//后代选择符
"": function(checkSet, part, isXML){
var doneName = done++, checkFn = dirCheck;
if ( !part.match(//W/) ) {
var nodeCheck = part = isXML ? part : part.toUpperCase();
checkFn = dirNodeCheck;
}
checkFn("parentNode", part, doneName, checkSet, nodeCheck, isXML);
},
//兄长选择符
"~": function(checkSet, part, isXML){
var doneName = done++, checkFn = dirCheck;
if ( typeof part === "string" && !part.match(//W/) ) {
var nodeCheck = part = isXML ? part : part.toUpperCase();
checkFn = dirNodeCheck;
}
checkFn("previousSibling", part, doneName, checkSet, nodeCheck, isXML);
}
},
find: {
ID: function(match, context, isXML){
if ( typeof context.getElementById !== "undefined" && !isXML ) {
var m = context.getElementById(match[1]);
return m ? [m] : [];//就算只有一个也放进数组
}
},
NAME: function(match, context, isXML){
if ( typeof context.getElementsByName !== "undefined" ) {
var ret = [], results = context.getElementsByName(match[1]);
for ( var i = 0, l = results.length; i < l; i++ ) {
if ( results[i].getAttribute("name") === match[1] ) {
ret.push( results[i] );
}
}
return ret.length === 0 ? null : ret;
}
},
TAG: function(match, context){
return context.getElementsByTagName(match[1]);
}
},
preFilter: {//这里,如果符合的话都返回字符串
CLASS: function(match, curLoop, inplace, result, not, isXML){
match = " " + match[1].replace(////g, "") + " ";
if ( isXML ) {
return match;
}
for ( var i = 0, elem; (elem = curLoop[i]) != null; i++ ) {
if ( elem ) {
//相当于hasClassName
if ( not ^ (elem.className && (" " + elem.className + " ").indexOf(match) >= 0) ) {
if ( !inplace )
result.push( elem );
} else if ( inplace ) {
curLoop[i] = false;
}
}
}
return false;
},
ID: function(match){
return match[1].replace(////g, "");
},
TAG: function(match, curLoop){
for ( var i = 0; curLoop[i] === false; i++ ){}
return curLoop[i] && isXML(curLoop[i]) ? match[1] : match[1].toUpperCase();
},
CHILD: function(match){
//把nth(****)里面的表达式都弄成an+b的样子
if ( match[1] == "nth" ) {
// parse equations like 'even', 'odd', '5', '2n', '3n+2', '4n-1', '-n+6'
var test = /(-?)(/d*)n((?:/+|-)?/d*)/.exec(
match[2] == "even" && "2n" || match[2] == "odd" && "2n+1" ||
!//D/.test( match[2] ) && "0n+" + match[2] || match[2]);
// calculate the numbers (first)n+(last) including if they are negative
match[2] = (test[1] + (test[2] || 1)) - 0;
match[3] = test[3] - 0;
}
// TODO: Move to normal caching system
match[0] = done++;
return match;
},
ATTR: function(match, curLoop, inplace, result, not, isXML){
var name = match[1].replace(////g, "");
if ( !isXML && Expr.attrMap[name] ) {
match[1] = Expr.attrMap[name];
}
if ( match[2] === "~=" ) {
match[4] = " " + match[4] + " ";
}
return match;
},
PSEUDO: function(match, curLoop, inplace, result, not){
if ( match[1] === "not" ) {
// If we're dealing with a complex expression, or a simple one
if ( match[3].match(chunker).length > 1 || /^/w/.test(match[3]) ) {
match[3] = Sizzle(match[3], null, null, curLoop);
} else {
var ret = Sizzle.filter(match[3], curLoop, inplace, true ^ not);
if ( !inplace ) {
result.push.apply( result, ret );
}
return false;
}
} else if ( Expr.match.POS.test( match[0] ) || Expr.match.CHILD.test( match[0] ) ) {
return true;
}
return match;
},
POS: function(match){
match.unshift( true );
return match;
}
},
filters: {//都是返回布尔值
enabled: function(elem){
//不能为隐藏域
return elem.disabled === false && elem.type !== "hidden";
},
disabled: function(elem){
return elem.disabled === true;
},
checked: function(elem){
return elem.checked === true;
},
selected: function(elem){
// Accessing this property makes selected-by-default
// options in Safari work properly
elem.parentNode.selectedIndex;
return elem.selected === true;
},
parent: function(elem){
//是否是父节点(是,肯定有第一个子节点)
return !!elem.firstChild;
},
empty: function(elem){
//是否为空,一点节点也没有
return !elem.firstChild;
},
has: function(elem, i, match){
return !!Sizzle( match[3], elem ).length;
},
header: function(elem){
//是否是h1,h2,h3,h4,h5,h6
return /h/d/i.test( elem.nodeName );
},
text: function(elem){
//文本域,下面几个相仿,基本上可以归类于属性选择器
return "text" === elem.type;
},
radio: function(elem){
return "radio" === elem.type;
},
checkbox: function(elem){
return "checkbox" === elem.type;
},
file: function(elem){
return "file" === elem.type;
},
password: function(elem){
return "password" === elem.type;
},
submit: function(elem){
return "submit" === elem.type;
},
image: function(elem){
return "image" === elem.type;
},
reset: function(elem){
return "reset" === elem.type;
},
button: function(elem){
return "button" === elem.type || elem.nodeName.toUpperCase() === "BUTTON";
},
input: function(elem){
return /input|select|textarea|button/i.test(elem.nodeName);
}
},
setFilters: {//子元素过滤器
first: function(elem, i){
return i === 0;
},
last: function(elem, i, match, array){
return i === array.length - 1;
},
even: function(elem, i){
return i % 2 === 0;
},
odd: function(elem, i){
return i % 2 === 1;
},
lt: function(elem, i, match){
return i < match[3] - 0;
},
gt: function(elem, i, match){
return i > match[3] - 0;
},
nth: function(elem, i, match){
return match[3] - 0 == i;
},
eq: function(elem, i, match){
return match[3] - 0 == i;
}
},
filter: {
PSEUDO: function(elem, match, i, array){
var name = match[1], filter = Expr.filters[ name ];
if ( filter ) {
return filter( elem, i, match, array );
} else if ( name === "contains" ) {
return (elem.textContent || elem.innerText || "").indexOf(match[3]) >= 0;
} else if ( name === "not" ) {
var not = match[3];
for ( var i = 0, l = not.length; i < l; i++ ) {
if ( not[i] === elem ) {
return false;
}
}
return true;
}
},
CHILD: function(elem, match){
var type = match[1], node = elem;
switch (type) {
case 'only':
case 'first':
while (node = node.previousSibling) {
if ( node.nodeType === 1 ) return false;
}
if ( type == 'first') return true;
node = elem;
case 'last':
while (node = node.nextSibling) {
if ( node.nodeType === 1 ) return false;
}
return true;
case 'nth':
var first = match[2], last = match[3];
if ( first == 1 && last == 0 ) {
return true;
}
var doneName = match[0],
parent = elem.parentNode;
if ( parent && (parent.sizcache !== doneName || !elem.nodeIndex) ) {
var count = 0;
for ( node = parent.firstChild; node; node = node.nextSibling ) {
if ( node.nodeType === 1 ) {
node.nodeIndex = ++count;//添加一个私有属性
}
}
parent.sizcache = doneName;
}
var diff = elem.nodeIndex - last;
if ( first == 0 ) {
return diff == 0;//判断是否为第一个子元素
} else {
return ( diff % first == 0 && diff / first >= 0 );
}
}
},
ID: function(elem, match){
return elem.nodeType === 1 && elem.getAttribute("id") === match;
},
TAG: function(elem, match){
return (match === "*" && elem.nodeType === 1) || elem.nodeName === match;
},
CLASS: function(elem, match){
return (" " + (elem.className || elem.getAttribute("class")) + " ")
.indexOf( match ) > -1;
},
ATTR: function(elem, match){
var name = match[1],
result = Expr.attrHandle[ name ] ?
Expr.attrHandle[ name ]( elem ) :
elem[ name ] != null ?
elem[ name ] :
elem.getAttribute( name ),
value = result + "",
type = match[2],
check = match[4];
return result == null ?
type === "!=" :
type === "=" ?
value === check :
type === "*=" ?
value.indexOf(check) >= 0 :
type === "~=" ?
(" " + value + " ").indexOf(check) >= 0 :
!check ?
value && result !== false :
type === "!=" ?
value != check :
type === "^=" ?
value.indexOf(check) === 0 :
type === "$=" ?
value.substr(value.length - check.length) === check :
type === "|=" ?
value === check || value.substr(0, check.length + 1) === check + "-" :
false;
},
POS: function(elem, match, i, array){
var name = match[2], filter = Expr.setFilters[ name ];
if ( filter ) {
return filter( elem, i, match, array );
}
}
}
};
var origPOS = Expr.match.POS;
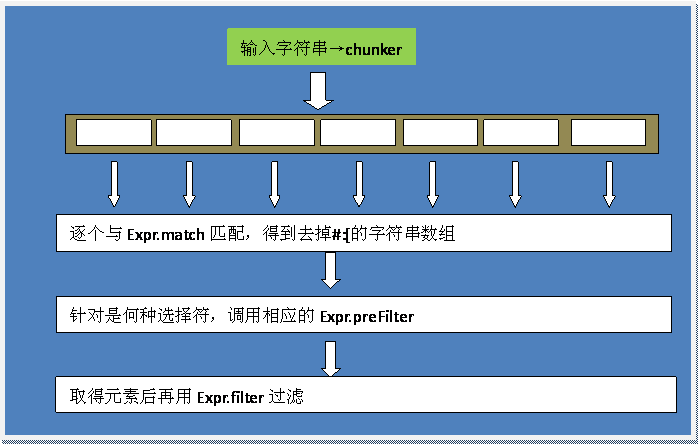
但上图没有完全显现Sizzle复杂的工作机制,它是从左到右工作,加工了一个字符串,查找,然后过滤非元素节点,再跟据其属性或内容或在父元素的顺序过滤,然后到下一个字符串,这时搜索起点就是上次的结果数组的元素节点,想象一下草根的样子吧。在许多情况下,选择器都是靠工作的,element.getElementsByTagName(*),获得其一元素的所有子孙,因此Expr中的过滤器特别多。为了过快查找速度,如有些浏览器已经实现了getElementsByClassName,jQuery也设法把它们利用起来。
for ( var type in Expr.match ) {
//重写Expr.match中的正则,利用负向零宽断言让其更加严谨
Expr.match[ type ] = RegExp( Expr.match[ type ].source + /(?![^/[]*/])(?![^/(]*/))/.source );
}
接着下来我们还是未到时候看上面的主程序,继续看它的辅助方法。
//把NodeList HTMLCollection转换成纯数组,如果有第二参数(上次查找的结果),则把它们加入到结果集中
var makeArray = function(array, results) {
array = Array.prototype.slice.call( array );
if ( results ) {
results.push.apply( results, array );
return results;
}
return array;
};
try {
//基本上是用于测试IE的,IE的NodeList HTMLCollection不支持用数组的slice转换为数组
Array.prototype.slice.call( document.documentElement.childNodes );
//这时就要重载makeArray,一个个元素搬入一个空数组中了
} catch(e){
makeArray = function(array, results) {
var ret = results || [];
if ( toString.call(array) === "[object Array]" ) {
Array.prototype.push.apply( ret, array );
} else {
if ( typeof array.length === "number" ) {
for ( var i = 0, l = array.length; i < l; i++ ) {
ret.push( array[i] );
}
} else {
for ( var i = 0; array[i]; i++ ) {
ret.push( array[i] );
}
}
}
return ret;
};
}

















 7106
7106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









