 Scrapy框架详解与实战指南
Scrapy框架详解与实战指南





 本文详细介绍了Scrapy的安装、目录结构、整体架构及其工作流程。通过一个京东全品类爬虫实战,展示了如何定义数据、创建爬虫、使用管道进行数据存储,并配置和运行爬虫。
本文详细介绍了Scrapy的安装、目录结构、整体架构及其工作流程。通过一个京东全品类爬虫实战,展示了如何定义数据、创建爬虫、使用管道进行数据存储,并配置和运行爬虫。
本文从 scrapy 安装开始,简要介绍 scrapy 的项目结构和运行原理,并通过一个 JD 全品类实例演示。
0. 什么是 Scrapy
Scrapy | A Fast and Powerful Scraping and Web Crawling Framework
License: BSD License
Written in: Python
Initial release: 26 June 2008
Stable release: 1.4.0 / 18 May 2017; 5 months ago
Developer(s): Scrapinghub, Ltd.
An open source and collaborative framework for extracting the data you need from websites.
In a fast, simple, yet extensible way.
Scrapy,Python 开发的一个快速,高层次的屏幕抓取和 web 抓取框架,用于抓取 web 站点并从页面中提取结构化的数据。简言之,就是一个爬虫框架。既然是框架,那就用!用!用!
1. Scrapy 安装
目前,Scrapy 已经支持 Python3.X,本文默认使用 Ubuntu+Anaconda3(Python3.6) 环境。
官方提供 pip 进行安装:pip install scrapy,其实 Anaconda 自带的包管理 conda 安装更顺利:conda install scrapy。
当终端运行scrapy version出现类似 “Scrapy 1.5.0” 说明安装成功。
2. Scrapy 目录结构
Scrapy 中工具命令分为两种,一种为全局命令,一种为项目命令。具体区别以后会详述,可对比下面两张图有直观感受。
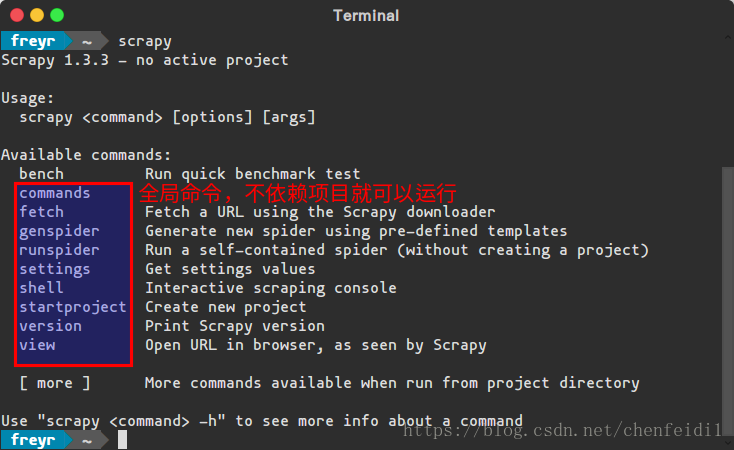
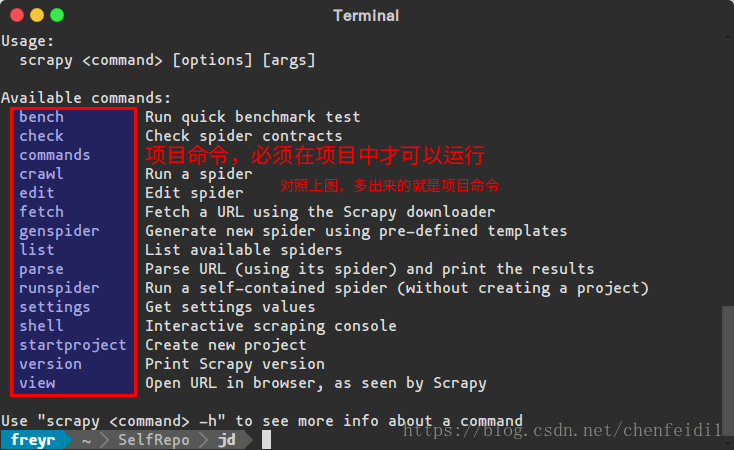
为了方便目录结构讲解,先创建一个项目 jd:
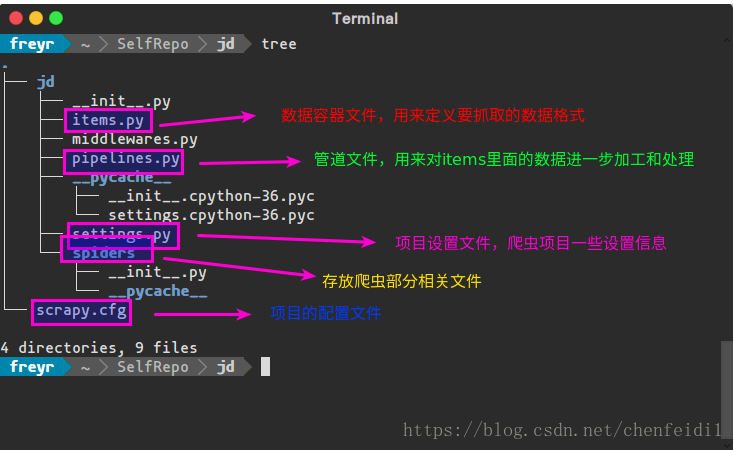
scrapy startproject jd此时会出现新目录jd,进入后发现还有一个同名jd目录,暂时称外层目录为爬虫目录(基本的命令操作都在这里进行),内层为项目目录。初始化的目录结构和各文件说明如图(使用方法和之间关系后面会说明):
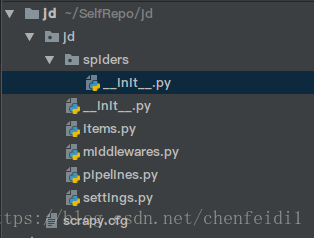
最后上一张 Pychrm 下项目结构图:
3. Scrapy 整体架构
3.1 框架组件
Scrapy 的框架主要有以下组件:
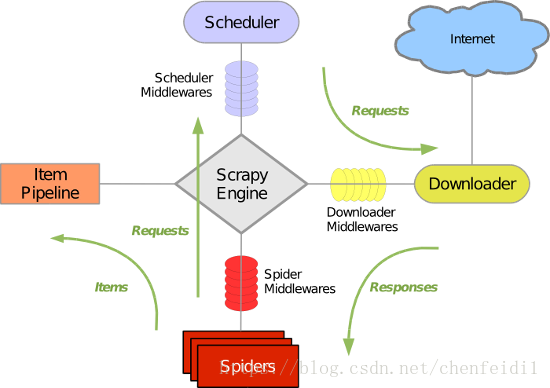
引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1672
1672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









