



引言
在当今数字化时代,公司知识库对于企业的知识管理和信息共享至关重要。本文将详细介绍如何使用 Cursor 开发一套完整的公司前后端知识库,涵盖从需求描述到部署上线的全过程,希望能为技术开发者提供有价值的参考。
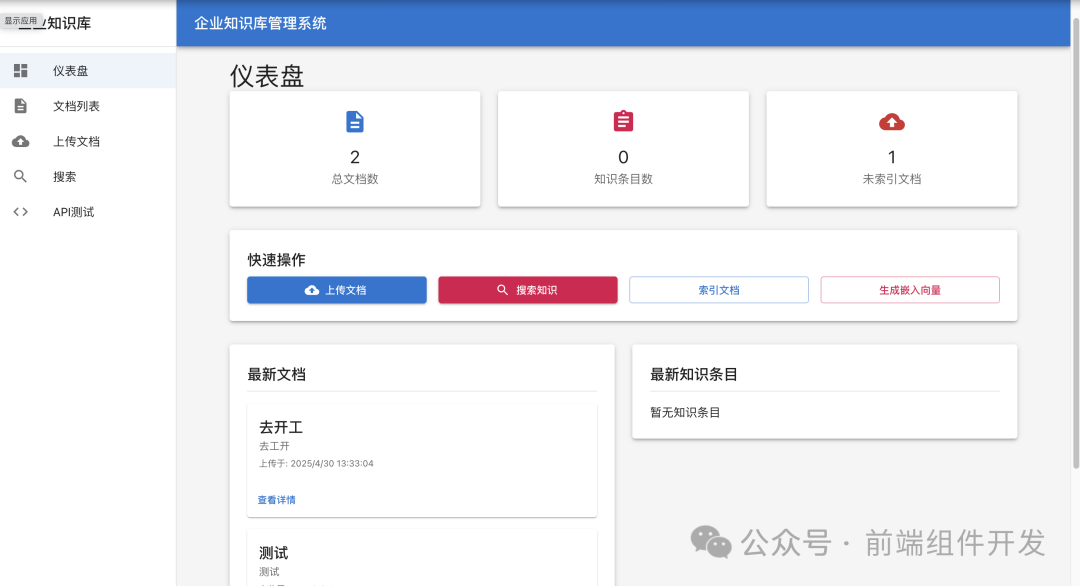
一、简洁结构化描述需求
在开始开发之前,清晰明确的需求描述是项目成功的基础。我们的目标是开发一个前后端分离的公司知识库系统,具体技术选型如下:
•前端框架:选择当下流行的 Vue.js 框架,它具有高效的响应式组件系统和丰富的生态系统,能够快速构建用户友好的界面。
•后端技术:采用 Java Spring Boot 框架,其强大的生态和便捷的开发特性,适合构建稳定、可扩展的后端服务。
•大模型:集成 DeepSeek 大模型,利用其强大的自然语言处理能力,实现知识库的智能搜索、内容生成等功能。DeepSeek 的 API Key 为 [具体 API Key],用于与大模型进行交互。
通过这样简洁明了的需求描述,团队成员能够快速明确项目的技术方向和目标,为后续的开发工作奠定基础。
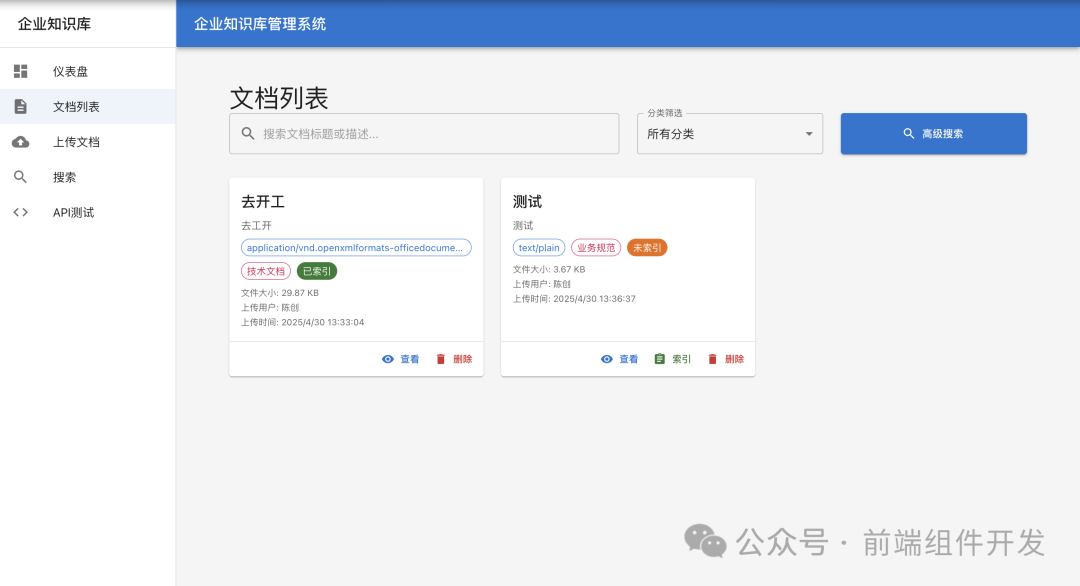
二、启动运行项目与前后端接口调试
(一)启动前端项目
1.首先确保本地环境已安装 Node.js 和 npm。打开终端,进入前端项目目录。
2.执行npm install命令,安装项目所需的依赖包。
3.依赖安装完成后,执行npm run dev命令启动前端开发服务器。此时,前端项目会在本地指定端口(如 8080)运行,浏览器会自动打开项目首页。
(二)启动后端项目
1.后端项目基于 Java Spring Boot,使用 IDE(如 IntelliJ IDEA)打开项目。
2.确保已配置好 Java 开发环境(JDK 版本符合项目要求)。
3.在 IDE 中找到项目的主类(通常带有@SpringBootApplication注解),点击运行按钮启动后端服务。后端项目默认会在 8081 端口运行(可在配置文件中修改端口号)。
(三)前后端接口调试
前后端项目启动后,需要进行接口调试以确保数据交互正常。这里可以使用 Postman 或 Swagger 等工具进行接口测试。
1.Swagger 集成(后端):在 Spring Boot 项目中添加 Swagger 依赖,通过配置类启用 Swagger。启动后端项目后,访问http://localhost:8081/swagger-ui.html,可以看到自动生成的接口文档。
2.接口测试:以获取知识库列表接口为例,在 Swagger 或 Postman 中发送 GET 请求到http://localhost:8081/knowledge/list,后端会返回知识库的列表数据。检查返回的数据格式、字段是否正确,以及响应状态码是否为 200 OK。
3.跨域处理:如果前后端运行在不同端口,可能会遇到跨域问题。在后端项目中添加跨域配置,允许前端域名的请求,确保前后端能够正常通信。
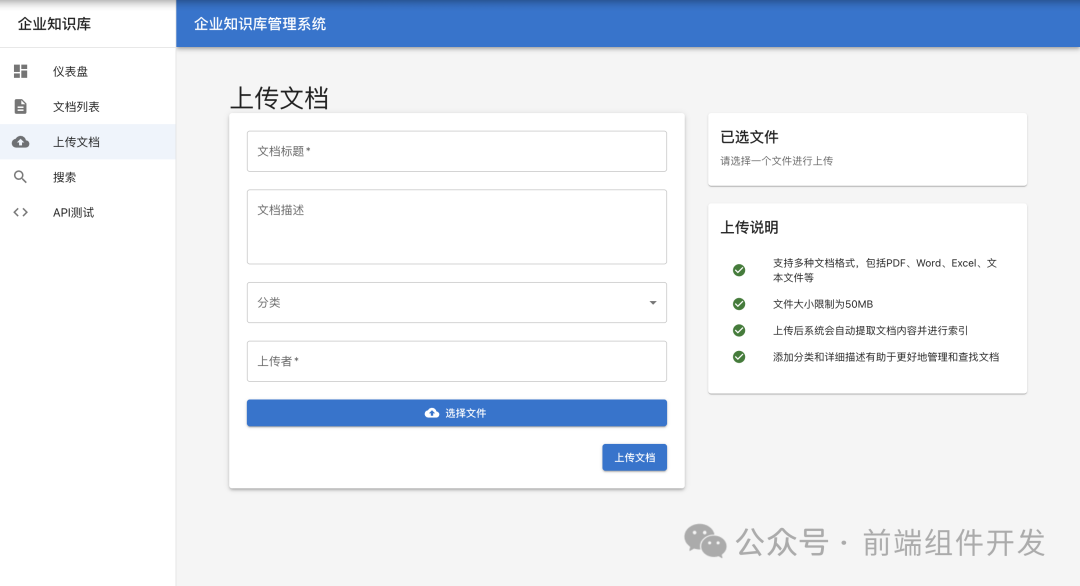
三、项目调试问题解决
在项目调试过程中,难免会遇到各种问题。此时,将问题场景准确地发送给 Cursor,能够快速定位和解决问题。以下是一些常见的问题场景及解决方法:
(一)前端页面数据显示异常
问题场景:前端页面调用后端接口获取数据后,数据显示不正确或缺失。
解决步骤:
1.在前端控制台(F12 开发者工具)中查看网络请求,确认接口是否调用成功,返回的数据是否正确。
2.如果接口返回数据异常,将接口的 URL、请求方法、请求参数和返回结果等信息发送给 Cursor,分析后端数据处理逻辑是否存在问题,如数据库查询条件错误、数据格式转换错误等。
3.根据 Cursor 的建议,检查后端代码,修复数据处理逻辑中的问题,重新测试接口。
(二)后端接口无法访问
问题场景:后端接口在 Swagger 或 Postman 中无法访问,返回 404 Not Found 错误。
解决步骤:
1.检查后端项目的日志,查看是否有启动异常或错误信息,确认接口对应的 Controller 类和方法是否正确映射路径。
2.检查 Spring Boot 的配置文件(如 application.properties 或 application.yml),确保服务器端口配置正确,且接口路径没有拼写错误。
3.如果问题仍然存在,将后端项目的相关代码片段和错误日志发送给 Cursor,分析是否存在依赖冲突、类路径扫描问题等,根据建议进行修复。
(三)大模型交互失败
问题场景:调用 DeepSeek 大模型 API 时,返回错误信息,如 API Key 无效、请求超时等。
解决步骤:
1.首先确认 DeepSeek 的 API Key 是否正确,是否在有效期内。检查代码中 API Key 的配置是否正确,是否有空格或其他字符错误。
2.检查网络连接是否正常,请求的 URL 和参数是否符合 DeepSeek 大模型的 API 文档要求。
3.如果问题依旧,将错误信息和调用大模型的代码片段发送给 Cursor,分析是否存在请求头设置错误、参数格式不正确等问题,及时进行修正。
四、前后端打包与部署上线
(一)前端打包
1.前端项目开发完成并测试通过后,进行生产环境打包。在终端执行npm run build命令,生成优化后的静态资源文件,存放在dist目录下。
2.可以根据项目需求,对打包配置进行优化,如压缩代码、图片优化、按需加载等,以提高前端页面的加载速度。
(二)后端打包
1.后端项目使用 Maven 进行打包。在 IDE 中点击 Maven 的package目标,或者在终端进入后端项目根目录,执行mvn clean package命令。
2.打包完成后,在target目录下会生成一个可执行的 JAR 包(如 knowledge-base-backend.jar),该 JAR 包包含了项目的所有依赖和代码。
(三)部署上线
1.服务器准备:选择合适的服务器(如阿里云、腾讯云等),安装必要的环境,如 Nginx(用于前端静态资源部署)、Java 运行环境(JRE)等。
2.前端部署:将前端打包生成的dist目录下的所有文件上传到 Nginx 的静态资源目录(如/usr/share/nginx/html),配置 Nginx 的虚拟主机,设置域名和端口映射,确保前端页面可以通过域名正常访问。
3.后端部署:将后端生成的 JAR 包上传到服务器的指定目录(如/opt/knowledge-base),通过执行java -jar knowledge-base-backend.jar命令启动后端服务。可以使用 Systemd 等工具将后端服务设置为开机自启动,提高服务的稳定性。
4.域名与 SSL 配置:为知识库系统申请域名,并配置 SSL 证书,实现 HTTPS 加密访问,保障数据传输的安全性。
5.上线验证:部署完成后,通过浏览器访问前端域名,测试各个功能模块是否正常运行,如知识库的新增、查询、编辑、删除等操作,确保前后端交互顺畅,大模型功能正常调用。
五、总结
通过以上步骤,我们成功地使用 Cursor 开发并部署了一套完整的公司前后端知识库系统。在整个开发过程中,Cursor 发挥了重要作用,帮助我们快速解决调试过程中遇到的问题,提高了开发效率。希望本文能够为读者在类似项目的开发中提供有益的参考,助力企业构建高效、智能的知识管理平台。



















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











