






比较,这是纯 chromadb 模型,每次需要从json 导入数据,修改从 mysql 导入数据,相关问题只需要维护在 数据库即可。
以下是对这段 Python 代码的详细解释:
MySQL DDL
CREATE TABLE `questions_answers` (
`id` int NOT NULL AUTO_INCREMENT,
`question` text,
`answer` text,
`category` varchar(255) DEFAULT NULL,
`source` varchar(255) DEFAULT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`img` text,
`video` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=425 DEFAULT CHARSET=utf81. 模块导入部分
import http.server
import socketserver
import cgi
import json
import os
import re
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
from googletrans import Translator
import mysql.connector
import chromadb
这段代码导入了多个 Python 库,用于实现不同的功能:
http.server和socketserver:用于创建简单的 HTTP 服务器,处理来自客户端的 HTTP 请求(GET、POST 等),是构建 Web 应用后端服务的基础模块。cgi:用于处理通过 POST 方法提交的表单数据,解析表单中的字段和值等信息。json:用于处理 JSON 格式的数据,可能在与客户端交互或者内部数据存储、传输等场景中使用。os:提供了与操作系统交互的功能,例如文件路径操作、目录操作等,代码中可能用于处理模型文件路径等相关操作。re:正则表达式模块,用于文本处理中按照特定模式匹配、替换等操作,像代码里文本清洗时去除 HTML 标签等就用到了正则表达式。string:包含了常用的字符串常量和工具函数,在这里用于文本处理(如去除标点符号等操作)。sklearn.feature_extraction.text.TfidfVectorizer:从scikit-learn库中导入,用于实现 TF-IDF 算法,将文本转换为向量表示,进而可以提取文本的关键词特征等,在代码里用于关键词提取功能。sklearn.metrics.pairwise.cosine_similarity:同样来自scikit-learn库,用于计算两个向量之间的余弦相似度,这里可用于衡量问题向量之间的相似程度。sentence_transformers.SentenceTransformer:用于将文本句子转换为向量表示,是一种基于深度学习的文本嵌入模型,代码中依靠它把用户输入的问题转换为向量,便于后续在向量数据库中进行相似度查询等操作。googletrans.Translator:用于调用谷歌翻译服务,实现文本的翻译功能,比如将英文问题翻译为中文,方便后续处理流程。mysql.connector:用于连接 MySQL 数据库,实现与数据库的交互,如查询问题答案、获取相关图片和视频链接等操作。chromadb:是一个向量数据库相关的库,用于存储和查询文本向量数据,代码里将标准问题的向量存储在其中,方便后续查找与用户问题相似的标准问题。
2. 数据库连接与 ChromaDB 初始化部分
# 配置MySQL连接信息,修改为你实际的数据库连接参数
mydb = mysql.connector.connect(
host="192.168.1.39",
user="root",
password="abcd1234",
database="qa"
)
mycursor = mydb.cursor(dictionary=True) # 设置返回结果为字典形式,方便操作
# 初始化ChromaDB客户端(采用新的构造方式,无参数初始化,使用默认配置)
client = chromadb.Client()
# 获取或创建一个集合(类似于表)来存储标准问题向量
try:
collection = client.get_or_create_collection(name="standard_questions")
print("成功获取或创建 ChromaDB 集合")
except Exception as e:
print(f"获取或创建 ChromaDB 集合失败,原因: {e}")
raise
- 数据库连接:
首先通过mysql.connector.connect函数配置并建立与 MySQL 数据库的连接,指定了数据库服务器的主机地址(192.168.1.39)、用户名(root)、密码(abcd1234)以及要连接的数据库名称(qa)。然后创建了一个游标(mycursor),并设置其返回结果为字典形式,这样在后续从数据库查询数据时,结果可以方便地以字典形式进行访问(例如通过列名获取对应的值)。 - ChromaDB 客户端与集合初始化:
使用chromadb.Client()初始化了一个ChromaDB的客户端实例,这里采用的是无参数初始化方式,会使用默认配置来创建客户端。接着尝试获取或创建一个名为standard_questions的集合,这个集合类似于数据库中的表,用于存储标准问题向量。如果集合不存在,会自动创建;如果已经存在,则直接获取该集合,若获取或创建过程中出现异常,会打印出错误原因并抛出异常,终止程序执行。
3. 文本处理相关函数部分
# 设置工作目录(原代码中的相关部分,保留结构但可能需根据实际调整其作用)
work_dir = "E:/hw2024/rag"
# 模型文件所在目录(原代码中的相关部分,保留结构但可能需根据实际调整其作用)
model_path = os.path.join(work_dir, "text2vec-base-chinese-sentence")
# 初始化文本嵌入模型(原代码中的相关部分,保留加载模型逻辑)
try:
model = SentenceTransformer("text2vec-base-chinese-sentence")
print("成功加载 SentenceTransformer 模型")
except Exception as e:
print(f"加载 SentenceTransformer 模型失败,原因: {e}")
raise
def clean_text(text):
"""
文本清洗与规范化函数
参数:
text (str): 输入文本
返回:
str: 清洗后的文本
"""
print(f"开始清洗文本: {text}")
# 去除HTML标签
text = re.sub(r'<.*?>', '', text)
# 去除特殊字符和标点符号
text = text.translate(str.maketrans('', '', string.punctuation))
# 转换为小写
text = text.lower()
# 去除多余空格
text =''.join(text.split())
print(f"清洗后的文本: {text}")
return text
def extract_keywords(text):
"""
关键词提取函数(使用TF-IDF算法)
参数:
text (str): 输入文本
返回:
list: 关键词列表
"""
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([text])
feature_names = vectorizer.get_feature_names_out()
keywords = []
for col in tfidf_matrix.nonzero()[1]:
keywords.append(feature_names[col])
print(f"提取的关键词: {keywords}")
return keywords
def vectorize_question(question):
"""
将问题转换为向量表示
参数:
question (str): 输入问题
返回:
list: 问题向量
"""
print(f"开始将问题 {question} 转换为向量表示")
try:
vector = model.encode([question])[0]
print(f"成功将问题转换为向量,向量维度: {len(vector)}")
return vector
except Exception as e:
print(f"将问题转换为向量时失败,原因: {e}")
raise
- 工作目录与模型加载:
先定义了工作目录(work_dir),用于指定相关文件(比如模型文件等)所在的路径,然后通过os.path.join函数拼接出模型文件的具体路径(model_path),再尝试使用SentenceTransformer类加载指定名称(text2vec-base-chinese-sentence)的文本嵌入模型,如果加载成功会打印提示信息,若失败则打印错误原因并抛出异常。 - 文本清洗函数
clean_text:
这个函数用于对输入的文本进行清洗和规范化操作。首先打印出正在清洗的原始文本,然后依次执行以下几个清洗步骤:- 使用正则表达式
re.sub(r'<.*?>', '', text)去除文本中的 HTML 标签,将所有匹配<.*?>模式(即 HTML 标签)的内容替换为空字符串。 - 通过
text.translate(str.maketrans('', '', string.punctuation))去除文本中的特殊字符和标点符号,这里利用了str.maketrans函数创建一个转换表,将标点符号对应的映射都设置为空,实现去除标点的效果。 - 调用
text.lower()将文本转换为小写形式,统一文本的大小写格式。 - 使用
' '.join(text.split())去除文本中多余的空格,将连续的多个空格替换为单个空格,使文本格式更规整。最后返回清洗后的文本,并打印出清洗后的文本内容。
- 使用正则表达式
- 关键词提取函数
extract_keywords:
它接受一个文本输入,利用TfidfVectorizer类创建一个 TF-IDF 向量器对象,然后对输入的单个文本(通过fit_transform方法,虽然这里只有一个文本,但接口要求传入可迭代对象,所以用列表包裹文本)进行向量化处理,得到 TF-IDF 矩阵。接着获取特征名称(即所有可能的词汇),遍历 TF-IDF 矩阵中非零元素所在的列索引,根据列索引获取对应的特征名称作为关键词,最后将提取到的关键词组成列表返回,并打印出关键词列表内容。 - 问题向量化函数
vectorize_question:
该函数的目的是将输入的问题转换为向量表示。首先打印出正在处理的问题内容,然后尝试使用之前加载的model(SentenceTransformer模型实例)的encode方法对问题进行编码,取返回结果中的第一个元素(因为encode方法返回的是一个包含单个向量的列表,即使只输入一个问题也是如此包装的)作为问题向量,打印出向量的维度信息后返回该向量。若在向量化过程中出现异常,则打印错误原因并抛出异常,终止函数执行。
4. 向量数据库查询与最佳映射选择部分
def query_vector_database(user_question_vector, user_question, top_k=5, similarity_threshold=0.7):
"""
在ChromaDB集合中查询与用户问题向量相似的问题
参数:
user_question_vector (list): 用户问题向量
user_question (str): 用户原始问题
top_k (int): 返回的最相似问题数量,默认为5
similarity_threshold (float): 相似度阈值,默认为0.7
返回:
list: 包含候选问题、相似度的字典列表
"""
print(f"开始在向量数据库中查询,用户问题向量: {user_question_vector}")
try:
results = collection.query(
query_embeddings=[user_question_vector],
n_results=top_k
)
print(f"查询得到的原始结果: {results}")
candidates = []
for i in range(len(results['ids'][0])):
question_id = results['ids'][0][i]
similarity = results['distances'][0][i]
question = results['documents'][0][i]
print('similarity', similarity, '/n', 'question:', question)
candidates.append({
"question": question,
"similarity": similarity
})
print(f"查询向量数据库得到 {len(candidates)} 个候选映射问题")
return candidates
except Exception as e:
print(f"查询向量数据库时出现错误,原因: {e}")
raise
def choose_best_mapping(candidates, user_question):
"""
从候选映射问题中选择最佳映射问题
参数:
candidates (list): 候选映射问题及其相关信息的字典列表
user_question (str): 用户原始问题
返回:
dict: 最佳映射问题及其相关信息的字典,如果没有合适的映射则返回None
"""
if not candidates:
print("没有候选映射问题,无法选择最佳映射")
return None
print(f"开始从 {len(candidates)} 个候选映射问题中选择最佳映射问题,用户原始问题: {user_question}")
# 计算关键词重叠度
user_keywords = set(extract_keywords(user_question))
for candidate in candidates:
candidate_keywords = set(extract_keywords(candidate['question']))
candidate['keyword_overlap'] = len(user_keywords.intersection(candidate_keywords))
# 综合考虑相似度得分、关键词重叠度和问题长度差异来选择最佳候选
# best_candidate = max(candidates, key=lambda x: (x['similarity'], x['keyword_overlap'], -abs(len(x['question']) - len(user_question))))
best_candidate = min(candidates, key=lambda x: (x['similarity'], -x['keyword_overlap'], abs(len(x['question']) - len(user_question))))
return best_candidate
- 向量数据库查询函数
query_vector_database:
它的功能是在ChromaDB集合中查找与用户问题向量相似的问题。首先打印出正在查询的用户问题向量信息,然后使用collection.query方法,传入用户问题向量(包装在列表中,符合方法要求的参数格式)以及要返回的最相似问题数量(top_k,默认为 5),向ChromaDB集合发起查询请求。如果查询成功,获取到原始查询结果后,遍历结果中的ids、distances和documents等相关信息(这些信息对应着问题的标识、与用户问题的距离以及问题文本内容等),将每个候选问题及其相似度组成字典,添加到candidates列表中,打印出查询得到的候选映射问题数量后返回该列表。若查询过程中出现异常,则打印错误原因并抛出异常,终止函数执行。 - 最佳映射选择函数
choose_best_mapping:
此函数用于从候选映射问题中挑选出最佳的一个。首先判断传入的候选问题列表是否为空,如果为空则打印提示信息并返回None,表示无法选择最佳映射。然后对于非空的候选列表,先提取用户原始问题的关键词集合(通过调用extract_keywords函数并转换为集合类型,方便后续计算交集等操作),接着遍历每个候选问题,同样提取其关键词集合,并计算该候选问题与用户问题的关键词重叠度,将其添加到候选问题字典的keyword_overlap字段中。最后通过min函数结合一个自定义的键函数(这里根据相似度得分、关键词重叠度和问题长度差异来综合判断,与原来代码中使用max不同,改为了min,可能是基于不同的业务逻辑需求,比如希望选择相似度稍低但关键词重叠更合理、长度差异更合适的问题作为最佳候选等情况),从候选问题列表中选出最佳候选问题并返回。
5. 用户问题处理主函数部分
def process_question(user_question):
"""
处理用户问题的主函数
参数:
user_question (str): 用户输入的问题
返回:
str: 最佳映射问题的答案,如果没有找到合适映射则返回提示信息
"""
print(f"开始处理用户问题: {user_question}")
translator = Translator()
# 使用正则表达式判断是否为纯英文语句,匹配只包含英文字母、空格、常见标点符号(可根据实际调整)的字符串
is_english = bool(re.match(r'^[a-zA-Z\s.,:;?!\'"-]*$', user_question))
print('is_english:',is_english)
if is_english:
# 如果是纯英文,先翻译为中文
chinese_question = translator.translate(user_question, dest='zh-cn').text
cleaned_question = clean_text(chinese_question)
else:
cleaned_question = clean_text(user_question)
print(cleaned_question)
user_question_vector = vectorize_question(cleaned_question)
candidates = query_vector_database(user_question_vector, user_question)
best_mapping = choose_best_mapping(candidates, user_question)
if best_mapping:
# 根据最佳映射问题从MySQL数据库中获取答案以及其他相关数据(如图片、视频链接等)
best_question = best_mapping['question']
mycursor.execute("SELECT answer, img, video FROM questions_answers WHERE question = %s", (best_question,))
result = mycursor.fetchone()
if result:
answer = result['answer']
img_link = result.get('img')
video_link = result.get('video')
# 根据是否为英文输入构建相应语言的开头提示语
if is_english:
response = "Your question is: " + f"{user_question}" + ", I guess the question you're going to ask is: \n"
else:
response = "你的问题是: " + f"{user_question}" + ", 我猜想你要问的问题是:\n"
# 展示候选问题(示例,可根据实际需求调整展示格式等)
for i, candidate in enumerate(candidates, start=1):
if is_english:
translated_question = translator.translate(candidate['question'], dest='en').text
response += f"{i}. {translated_question}\n"
else:
response += f"{i}. {candidate['question']}\n"
response += "\n\n"
# 根据是否为英文输入构建相应语言的最佳映射问题提示语
if is_english:
response += "【Selected best mapping question】: \n"
else:
response += "【选择的最佳映射问题】: \n"
if is_english:
best_mapping_question_translated = translator.translate(best_question, dest='en').text
response += f"{best_mapping_question_translated}\n\n"以下是完整代码
import http.server
import socketserver
import cgi
import json
import os
import re
import string
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
from googletrans import Translator
import mysql.connector
import chromadb
# 配置MySQL连接信息,修改为你实际的数据库连接参数
mydb = mysql.connector.connect(
host="192.168.1.39",
user="root",
password="abcd1234",
database="qa"
)
mycursor = mydb.cursor(dictionary=True) # 设置返回结果为字典形式,方便操作
# 初始化ChromaDB客户端(采用新的构造方式,无参数初始化,使用默认配置)
client = chromadb.Client()
# 获取或创建一个集合(类似于表)来存储标准问题向量
try:
collection = client.get_or_create_collection(name="standard_questions")
print("成功获取或创建 ChromaDB 集合")
except Exception as e:
print(f"获取或创建 ChromaDB 集合失败,原因: {e}")
raise
# 设置工作目录(原代码中的相关部分,保留结构但可能需根据实际调整其作用)
work_dir = "E:/hw2024/rag"
# 模型文件所在目录(原代码中的相关部分,保留结构但可能需根据实际调整其作用)
model_path = os.path.join(work_dir, "text2vec-base-chinese-sentence")
# 初始化文本嵌入模型(原代码中的相关部分,保留加载模型逻辑)
try:
model = SentenceTransformer("text2vec-base-chinese-sentence")
print("成功加载 SentenceTransformer 模型")
except Exception as e:
print(f"加载 SentenceTransformer 模型失败,原因: {e}")
raise
def clean_text(text):
"""
文本清洗与规范化函数
参数:
text (str): 输入文本
返回:
str: 清洗后的文本
"""
print(f"开始清洗文本: {text}")
# 去除HTML标签
text = re.sub(r'<.*?>', '', text)
# 去除特殊字符和标点符号
text = text.translate(str.maketrans('', '', string.punctuation))
# 转换为小写
text = text.lower()
# 去除多余空格
text =''.join(text.split())
print(f"清洗后的文本: {text}")
return text
def extract_keywords(text):
"""
关键词提取函数(使用TF-IDF算法)
参数:
text (str): 输入文本
返回:
list: 关键词列表
"""
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([text])
feature_names = vectorizer.get_feature_names_out()
keywords = []
for col in tfidf_matrix.nonzero()[1]:
keywords.append(feature_names[col])
print(f"提取的关键词: {keywords}")
return keywords
def vectorize_question(question):
"""
将问题转换为向量表示
参数:
question (str): 输入问题
返回:
list: 问题向量
"""
print(f"开始将问题 {question} 转换为向量表示")
try:
vector = model.encode([question])[0]
print(f"成功将问题转换为向量,向量维度: {len(vector)}")
return vector
except Exception as e:
print(f"将问题转换为向量时失败,原因: {e}")
raise
def query_vector_database(user_question_vector, user_question, top_k=5, similarity_threshold=0.7):
"""
在ChromaDB集合中查询与用户问题向量相似的问题
参数:
user_question_vector (list): 用户问题向量
user_question (str): 用户原始问题
top_k (int): 返回的最相似问题数量,默认为5
similarity_threshold (float): 相似度阈值,默认为0.7
返回:
list: 包含候选问题、相似度的字典列表
"""
print(f"开始在向量数据库中查询,用户问题向量: {user_question_vector}")
try:
results = collection.query(
query_embeddings=[user_question_vector],
n_results=top_k
)
print(f"查询得到的原始结果: {results}")
candidates = []
for i in range(len(results['ids'][0])):
question_id = results['ids'][0][i]
similarity = results['distances'][0][i]
question = results['documents'][0][i]
print('similarity', similarity, '/n', 'question:', question)
candidates.append({
"question": question,
"similarity": similarity
})
print(f"查询向量数据库得到 {len(candidates)} 个候选映射问题")
return candidates
except Exception as e:
print(f"查询向量数据库时出现错误,原因: {e}")
raise
def choose_best_mapping(candidates, user_question):
"""
从候选映射问题中选择最佳映射问题
参数:
candidates (list): 候选映射问题及其相关信息的字典列表
user_question (str): 用户原始问题
返回:
dict: 最佳映射问题及其相关信息的字典,如果没有合适的映射则返回None
"""
if not candidates:
print("没有候选映射问题,无法选择最佳映射")
return None
print(f"开始从 {len(candidates)} 个候选映射问题中选择最佳映射问题,用户原始问题: {user_question}")
# 计算关键词重叠度
user_keywords = set(extract_keywords(user_question))
for candidate in candidates:
candidate_keywords = set(extract_keywords(candidate['question']))
candidate['keyword_overlap'] = len(user_keywords.intersection(candidate_keywords))
# 综合考虑相似度得分、关键词重叠度和问题长度差异来选择最佳候选
# best_candidate = max(candidates, key=lambda x: (x['similarity'], x['keyword_overlap'], -abs(len(x['question']) - len(user_question))))
best_candidate = min(candidates, key=lambda x: (x['similarity'], -x['keyword_overlap'], abs(len(x['question']) - len(user_question))))
return best_candidate
def process_question(user_question):
"""
处理用户问题的主函数
参数:
user_question (str): 用户输入的问题
返回:
str: 最佳映射问题的答案,如果没有找到合适映射则返回提示信息
"""
print(f"开始处理用户问题: {user_question}")
translator = Translator()
# 使用正则表达式判断是否为纯英文语句,匹配只包含英文字母、空格、常见标点符号(可根据实际调整)的字符串
is_english = bool(re.match(r'^[a-zA-Z\s.,:;?!\'"-]*$', user_question))
print('is_english:',is_english)
if is_english:
# 如果是纯英文,先翻译为中文
chinese_question = translator.translate(user_question, dest='zh-cn').text
cleaned_question = clean_text(chinese_question)
else:
cleaned_question = clean_text(user_question)
print(cleaned_question)
user_question_vector = vectorize_question(cleaned_question)
candidates = query_vector_database(user_question_vector, user_question)
best_mapping = choose_best_mapping(candidates, user_question)
if best_mapping:
# 根据最佳映射问题从MySQL数据库中获取答案以及其他相关数据(如图片、视频链接等)
best_question = best_mapping['question']
mycursor.execute("SELECT answer, img, video FROM questions_answers WHERE question = %s", (best_question,))
result = mycursor.fetchone()
if result:
answer = result['answer']
img_link = result.get('img')
video_link = result.get('video')
# 根据是否为英文输入构建相应语言的开头提示语
if is_english:
response = "Your question is: " + f"{user_question}" + ", I guess the question you're going to ask is: \n"
else:
response = "你的问题是: " + f"{user_question}" + ", 我猜想你要问的问题是:\n"
# 展示候选问题(示例,可根据实际需求调整展示格式等)
for i, candidate in enumerate(candidates, start=1):
if is_english:
translated_question = translator.translate(candidate['question'], dest='en').text
response += f"{i}. {translated_question}\n"
else:
response += f"{i}. {candidate['question']}\n"
response += "\n\n"
# 根据是否为英文输入构建相应语言的最佳映射问题提示语
if is_english:
response += "【Selected best mapping question】: \n"
else:
response += "【选择的最佳映射问题】: \n"
if is_english:
best_mapping_question_translated = translator.translate(best_question, dest='en').text
response += f"{best_mapping_question_translated}\n\n"
else:
response += f"{best_question}\n\n"
# 根据是否为英文输入构建相应语言的最终答案提示语
if is_english:
response += "【Final selected answer】: \n"
else:
response += "【最后选定的答案】:\n"
if img_link:
# 处理图片标签替换,将图片链接拼接进去
answer += f"<img src='{img_link}' />"
if video_link:
# 处理视频链接拼接(这里简单添加,可根据实际展示需求调整格式)
answer += f"<a href='{video_link}' target='_blank'>视频链接</a>"
response += answer
return response
else:
print("从数据库获取最佳映射问题对应答案等数据失败")
return "未找到对应答案,请检查数据库数据。"
else:
print("未找到合适的映射问题,返回提示信息")
return "未找到合适的映射问题,请进一步明确问题。"
# 定义处理请求的类,继承自BaseHTTPRequestHandler
class QuestionHandler(http.server.BaseHTTPRequestHandler):
def do_GET(self):
if self.path == "/":
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
with open('index.html', 'rb') as file:
self.wfile.write(file.read())
else:
self.send_error(404)
def do_POST(self):
if self.path == "/process_question":
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST'}
)
user_question = form.getvalue('user_question')
answer = process_question(user_question)
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(answer.encode('utf-8'))
else:
self.send_error(404)
# 设置服务器端口号
PORT = 8000
with socketserver.TCPServer(("", PORT), QuestionHandler) as httpd:
print(f"服务器启动,监听端口 {PORT}")
# 启动时将MySQL数据库中的问题数据加载到ChromaDB集合中(仅在集合为空时加载)
if collection.count() == 0:
mycursor.execute("SELECT question FROM questions_answers")
all_questions = mycursor.fetchall()
for question_data in all_questions:
question = question_data['question']
question_vector = vectorize_question(question)
collection.add(
ids=[question],
embeddings=[question_vector],
documents=[question]
)
print(f"服务器启动,监听端口 {PORT}")
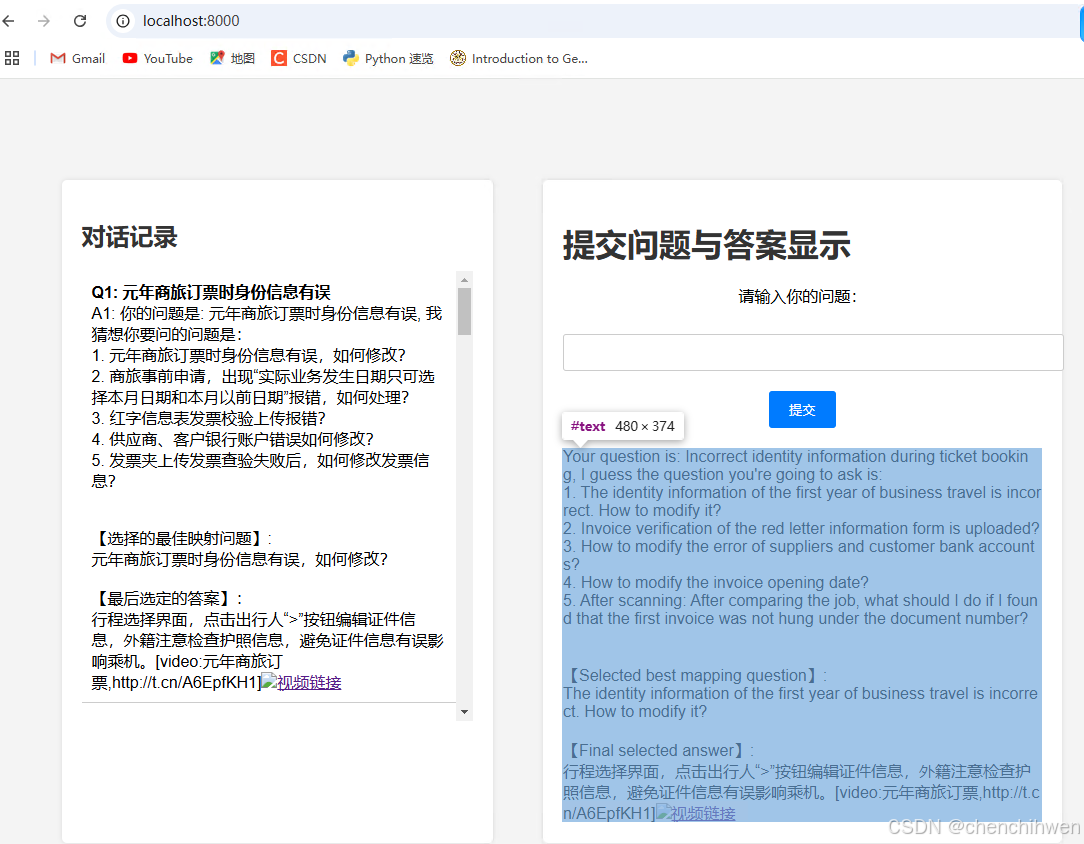
httpd.serve_forever()输出效果如下图

















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









