




 本文介绍了Pandas的DataFrame数据结构,包括其特性、实例化方法及行数据和列数据的选择。详细讲解了按位置、索引值、条件选择行数据,并展示了列数据的选择操作。
本文介绍了Pandas的DataFrame数据结构,包括其特性、实例化方法及行数据和列数据的选择。详细讲解了按位置、索引值、条件选择行数据,并展示了列数据的选择操作。
Pandas 数据结构
DataFrame 简介
DataFrame是Pandas中的一个表格型的数据结构,包含一组有序的列,每列的值的类型都可不同(整型、浮点型、布尔型、字符串等),DataFrame既有行索引也有列索引,可以被看作是由Series组成的字典
DataFrame也可以理解为带了行和列标签的二维数组:
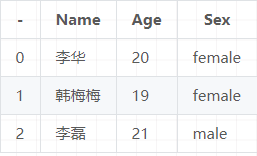
其中行标签为序号 0,1,2,列标签为 Name, Age, Sex. DataFrame 是最常用的Pandas对象, 与Series一样,DataFrame支持多种类型的输入数据:
- 列表、一维ndarray、字典、Series字典
- 二维ndarray
- Series
- DataFrame
除了数据,还可以有选择地传递 index(行标签)和 columns(列标签)参数。传递了index或clolumns,就可以确保生成的 DataFrame 里包有索引或列。Series 字典加上指定索引时,会丢弃与传递的索引不匹配的所有数据。
没有传递轴标签时,按常规依据输入数据进行构建。
DataFrame 实例化
DataFrame 可以使用字典、列表等实例化。
如果传入的数据全部是标量值(譬如字典:{‘a’:1, ‘b’:2}),那么必须传入index参数
df = pd.DataFrame({
'name': ['lihua', 'lilei', 'hanmeimei', 'xiaoming', 'xiaohong'],
'math': [99, 100, 80, 50, 118],
'english': [94, 83, 99, 79, 108],
'chinese': [107, 82, 76, 100, 113]
})
Output:
name math english chinese
0 lihua 99 94 107
1 lilei 100 83 82
2 hanmeimei 80 99 76
3 xiaoming 50 79  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









