




 本文深入探讨了CountVectorizer在文档向量化中的应用,通过计数将文档转换为向量,实现词语频率的稀疏表示。文章详细介绍了如何设置词汇表的大小和最低文档频率,展示了如何使用Spark MLlib中的CountVectorizer进行特征抽取,并提供了实例代码。
本文深入探讨了CountVectorizer在文档向量化中的应用,通过计数将文档转换为向量,实现词语频率的稀疏表示。文章详细介绍了如何设置词汇表的大小和最低文档频率,展示了如何使用Spark MLlib中的CountVectorizer进行特征抽取,并提供了实例代码。
特征抽取CountVectorizer
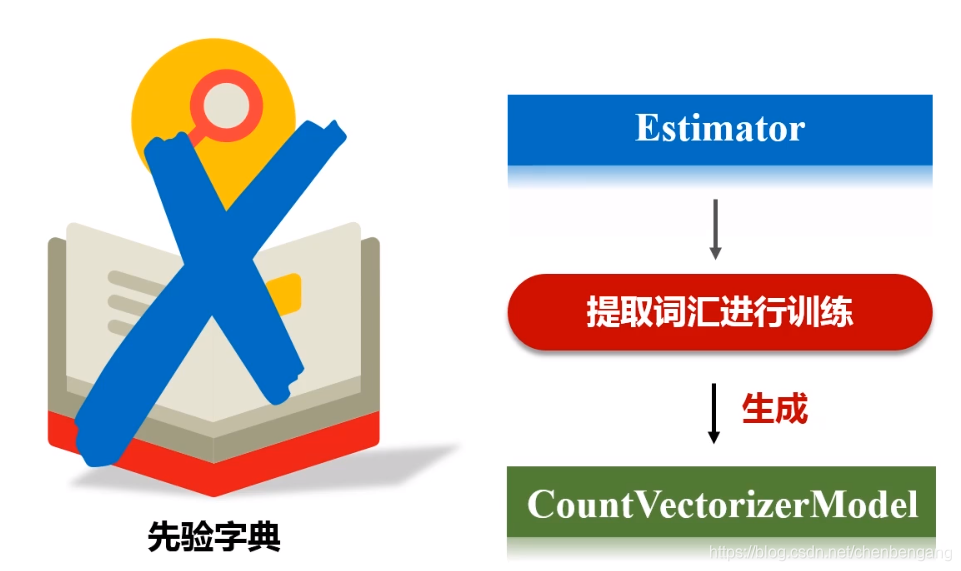
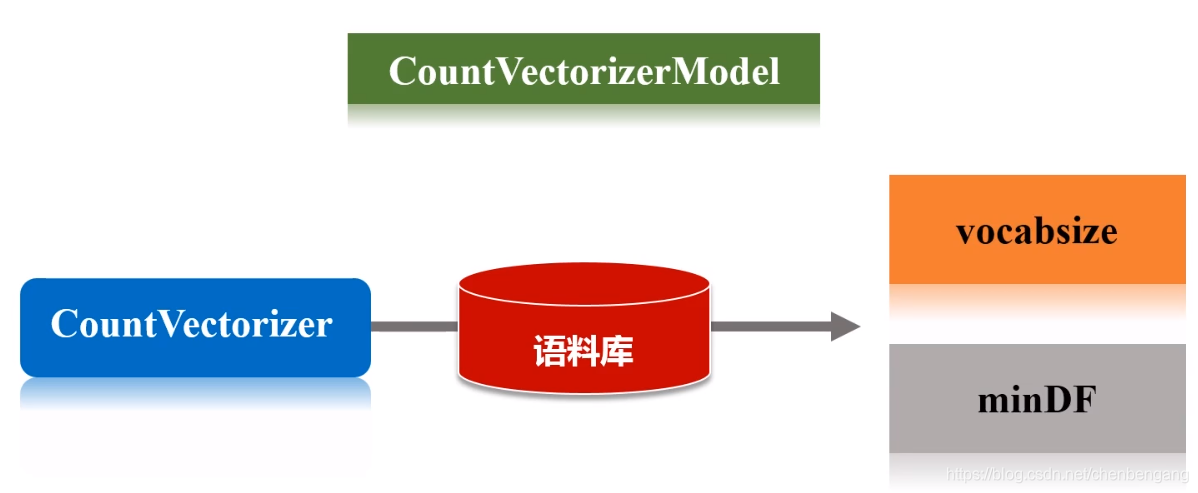
// 通过计数将文档转化为向量的,产生文档关于词语的稀疏表示
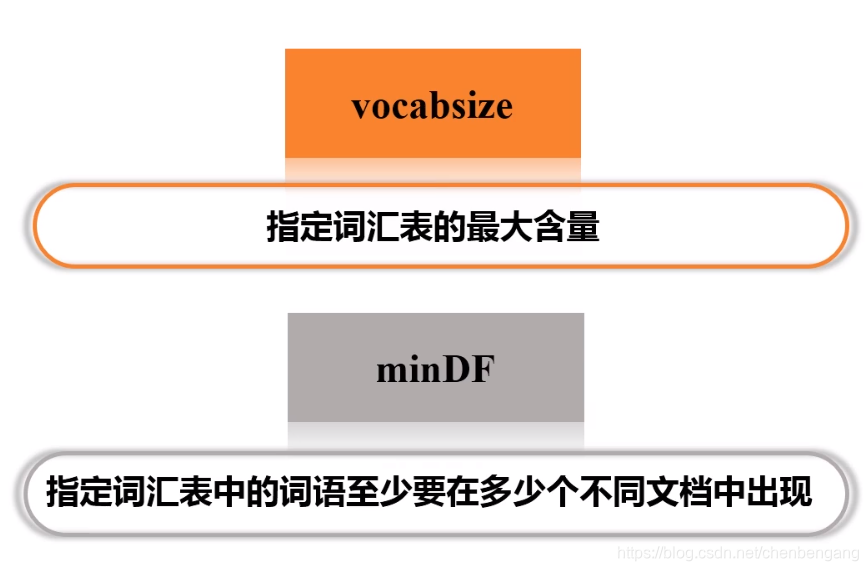
// CountVectorizer将根据语料库中的词频排序从高到低进行选择,词汇表的最大含量由vocabsize超参数来指定,超参数minDF,
// 则指定词汇表中的词语至少要在多少个不同文档中出现
import org.apache.spark.sql.SparkSession
val spark=SparkSession.builder().master("local").appName("CountVectorizerTest").getOrCreate()
// 开启RDD的隐式转换
import implicits._
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
// 也可以使用parallelize来创建RDD
val df=spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(1, Array("a", "b", "b", "c", "a"))
)).toDF("id","words")
df.show()
val cvModel: CountVectorizerModel=new CountVectorizer().
setInputCol("words").
setOutputCol("features").
setVocabSize(3).//词汇表的大小
setMinDF(2).//词汇表中的词至少在两个文档中出现过
fit(df)
cvModel.vocabulary
[b, a, c]
cvModel.transform(df).show(false)
+---+---------------+-------------------------+
|id |words |features |
+---+---------------+-------------------------+
|0 |[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])|
|1 |[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])|
+---+---------------+-------------------------+
// CountVectorizerModel可以通过指定一个先验词汇表来直接生成,如以下例子,直接指定词汇表的成员是“a”,“b”,“c”三个词:
val cvm = new CountVectorizerModel(Array("a", "b", "c")).
setInputCol("words").
setOutputCol("features")
cvm.transform(df).select("features").show(false)
+-------------------------+
|features |
+-------------------------+
|(3,[0,1,2],[1.0,1.0,1.0])|
|(3,[0,1,2],[2.0,2.0,1.0])|
+-------------------------+

















 5560
5560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









