




 TensorFlow Serving是Google为机器学习模型生产环境部署提供的高性能服务系统,支持模型版本控制、多模型服务、REST API等。其核心概念是Servable,由Loader、Source、AspiredVersions和Manager管理。当Source发现新模型版本,会通知Manager进行加载,Manager根据版本策略决定加载哪些模型。在部署时,需要先导出模型为SavedModel格式,再启动服务。TensorFlow Serving简化了模型迭代和部署流程。
TensorFlow Serving是Google为机器学习模型生产环境部署提供的高性能服务系统,支持模型版本控制、多模型服务、REST API等。其核心概念是Servable,由Loader、Source、AspiredVersions和Manager管理。当Source发现新模型版本,会通知Manager进行加载,Manager根据版本策略决定加载哪些模型。在部署时,需要先导出模型为SavedModel格式,再启动服务。TensorFlow Serving简化了模型迭代和部署流程。
Tersonflow Serving原理
前言
当我们将模型训练完毕后,往往需要将模型在生产环境中部署。最常见的方式,是在服务器上提供一个 API,即客户机向服务器的某个 API 发送特定格式的请求,服务器收到请求数据后通过模型进行计算,并返回结果。如果仅仅是做一个 Demo,不考虑高并发和性能问题,其实配合 Flask 等 Python 下的 Web 框架就能非常轻松地实现服务器 API。
不过,如果是在真的实际生产环境中部署,这样的方式就显得力不从心了。这时,TensorFlow 为我们提供了 TensorFlow Serving 这一组件,能够帮助我们在实际生产环境中灵活且高性能地部署机器学习模型。
Tensorflow Serving 是google为机器学习模型生产环境部署设计的高性能的服务系统。具有以下特性:
- 支持模型版本控制和回滚
- 支持多模型服务,比如用最新版本/所有版本/指定版本
- 支持 gRPC/ REST API 调用
- 支持批处理batching
- 支持模型的热更新
Tersonflow Serving实现原理
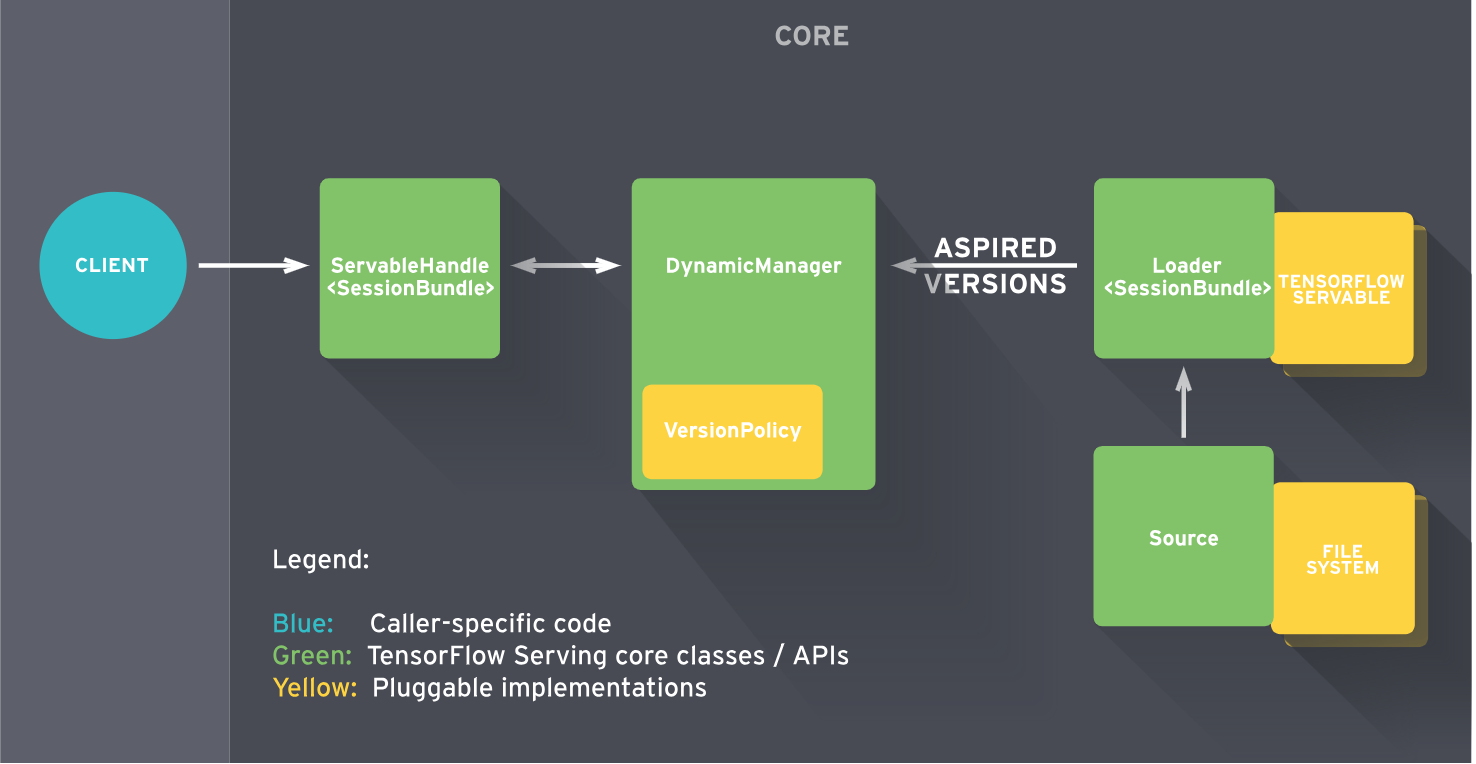
首先我们需要花一些时间来了解TF Serving如何处理ML模型的整个生命周期。在这里,我们将介绍TF服务的主要构建块。
TF Serving服务由一些抽象组成,这些抽象类用于不同任务的API,其中最重要的是Servable,Loader,Source,Aspired Versions和Manager。
让我们来看看他们之间是如何互动的:
 </
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9470
9470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









