



 本文详细介绍了LinkhashTable框架,包括开散列哈希表的概念、拉链法实现、桶高度对效率的影响以及Insert、Find和Erase操作的模拟实现。重点讨论了如何通过调整平衡因子优化性能和避免深拷贝带来的效率损失。
本文详细介绍了LinkhashTable框架,包括开散列哈希表的概念、拉链法实现、桶高度对效率的影响以及Insert、Find和Erase操作的模拟实现。重点讨论了如何通过调整平衡因子优化性能和避免深拷贝带来的效率损失。
LinkhashTable框架详解
概念:开散列哈希表 (拉链法实现)
一个vector,每一个节点下面都可以挂一个单链,每一条单链表我们称之为一个哈希桶,以下即是开散列哈希表的示意图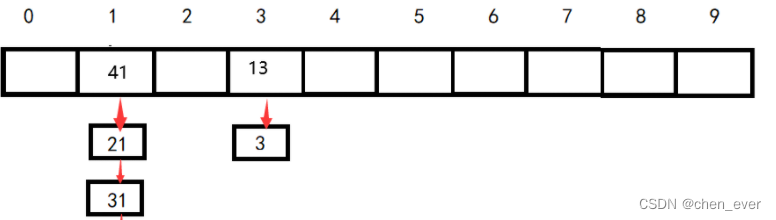
通过最直观的观察,我们就可以发现,相比较与闭散列开散列更有条理,key经处理后的不同组数据可以很好的被分类。将key处理后直接可以找到位子进行头插,而查找次数最多也就等于桶的高度。
所以在开散列中的效率主要取决于桶的高度,这个我们可以通过控制平衡因子来进行调整。在大部分场景中当平衡因子为1时进行扩容。
效率分析:在开散列哈希表中平衡因子最大为一,平均一下每一个桶的高度仅有一层,只需要进行一次查找,就算出现分布不均的情况,想必查找次数也并不会太多,在对随机数的处理上有很大的优势。相比于最大红黑树树深度次的查找相比,效率还是高了不少
框架:
template<class K, class V>
struct HashNode
{
HashNode(const pair<K, V>& kv)
:_kv(kv)
, _next(nullptr)
{}
pair<K, V> _kv;
HashNode<K, V>* _next;
};
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
bool Insert(const pair<K, V>& kv);
Node* Find(const K& key);
bool Erase(const K& key);
private:
vector<Node*> _tables;
size_t _n = 0;
};
Insert()模拟实现:
template<class K, class V, class Hash>
bool HashTable<K, V, Hash>::Insert(const pair<K, V>& kv)
{
if (!_tables.empty() && Find(kv.first))
return false;
Hash hs;
if (_n >= _tables.size())
{
//扩容
size_t newSize = _tables.size() == 0 ? 10 : 2 * _tables.size();
vector<Node*> newTables;
newTables.resize(newSize);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hs(cur->_kv.first) % _tables.size();
cur->_next = newTables[index];
newTables[index] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t index = hs(kv.first) % _tables.size();
Node* NewNode = new Node(kv);
NewNode->_next = _tables[index];
_tables[index] = NewNode;
++_n;
return true;
}
开散列的insert非常简单,只需要头插就可以了。
其扩容我们使用创建一个新的vector,然后遍历节点将其链接到新的vector。
此处为什么不能像上文一样创建一个新的表然后复用插入呢?因为在这个地方每一个节点并非开好的而是new出来的,若采用上面的方法就要对所有节点进行深拷贝,然后插入到新表中还要释放旧表的节点。严重影响效率,不如改变节点的链接方式,将其直接插入到新的哈希桶上
Find()模拟实现:
template<class K, class V, class Hash>
HashNode<K, V>* HashTable<K, V, Hash>::Find(const K& key)
{
if (_tables.empty())
return nullptr;
Hash hs;
size_t index = hs(key) % _tables.size();
Node* start = _tables[index];
while (start && start->_kv.first != key)
{
start = start->_next;
}
return start;
}
Erase()模拟实现:
template<class K, class V, class Hash>
bool HashTable<K, V, Hash>::Erase(const K& key)
{
Hash hs;
size_t index = hs(key) % _tables.size();
Node* cur = _tables[index];
Node* prev = nullptr;
while (cur && cur->_kv.first != key)
{
prev = cur;
cur = cur->_next;
}
if (cur == nullptr)
return false;
else if (prev == nullptr)
{
Node* next = cur->_next;
_tables[index] = next;
delete cur;
cur = nullptr;
return true;
}
else
{
prev->_next = cur->_next;
delete cur;
cur = nullptr;
return true;
}
}
可以观察到Erase并没有复用Find函数,这是因为单链表的删除需要保存其前一个结点,单纯一个结点是不够的。而删除也有几种情况
1.输入的key结点不存在
2.指定的结点在哈希桶的头部/中部/尾部
具体实现还是比较简单的,若有疑问看代码就好了,就不展开说了

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









