




 博客围绕数据仓库的数据量对比与质量管理展开。指出大数据做数据仓库底层时数据量常出现问题,如将MySQL数据同步到数据仓库。数据质量管理包括数据量比对和内容比对,多数公司仅比对数据量,全量内容比对代价大,部分公司采用抽查比对。还提及了比对数据的时机及复盘。
博客围绕数据仓库的数据量对比与质量管理展开。指出大数据做数据仓库底层时数据量常出现问题,如将MySQL数据同步到数据仓库。数据质量管理包括数据量比对和内容比对,多数公司仅比对数据量,全量内容比对代价大,部分公司采用抽查比对。还提及了比对数据的时机及复盘。
数据量对比
大数据很多都是做数据仓库.底层,但是数据仓库数据量往往会有问题。比如需要把MySQL数据同步到数据仓库:
中间有可能丢数据 100条 90条
也有可能不丢数据 200条 200条
也有可能多数据 90条 100条
可能多数据的原由:原始是作100条数据,先做insert插入,但是由于业务或者维护的关系,有十条MySQL作了delete,delete有问题,过不来没有执行,数据仓库还停留在100条。
数据质量管理
1.数据量的比对 select count(1代表字段) 计数
90%公司比对数据量,但光比对数据量不行,因为不代表数据内容一致,比如dac.das.数据量一样,但是字段内容不一样。
2.数据内容比对,比对的不是一个组件,而是全字段,很难比对,全量比对代价很大,效率低,几乎没有公司做。 但是少部分公司是依据数据量的比对做:抽查比对,两边的规则抽十条到20条,比对这10-20条数据
不相等:补数据 或 删数据
生产上:spark ==full join
咱这里:Linux MySQL == union
补数据: select * from t where bid is null 拿到a表字段的数据 拼接sql插入数据仓库
删数据::select * from t where aid is null --> bid --delete 语句
如若如以下案例,a表是MySQL数据库,b表是数据仓库,作数据质量,则最终结果是:b表缺5补id5数据一条,删除id 7-10
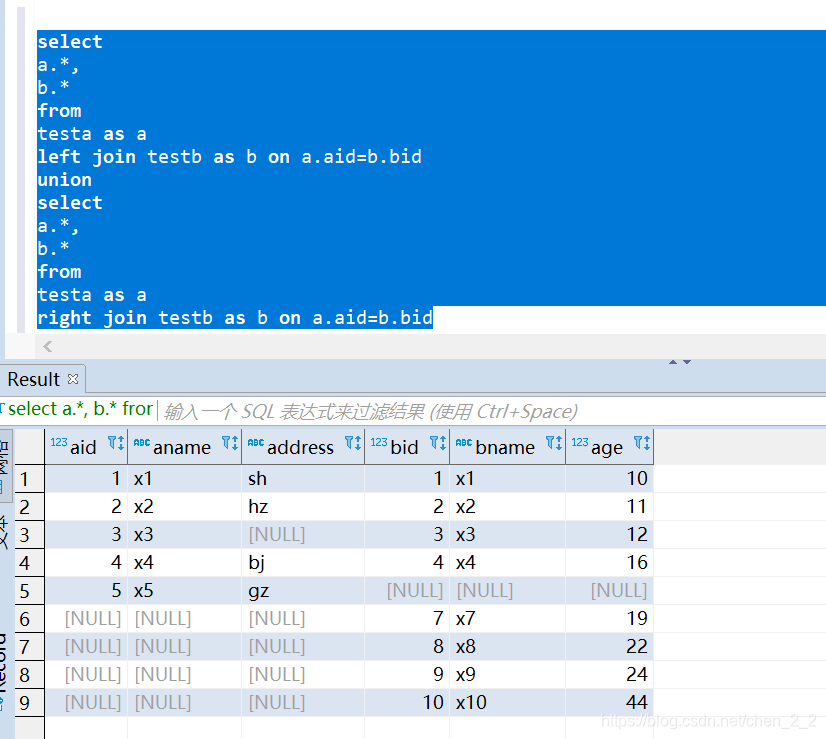
什么时候做比对数据?
假设 2019-06-29
<2019-06-01 00:00:00 全量
select count(1) from a where cretime<'2019-06-01 00:00:00'
select count(1) from b where cretime<'2019-06-01 00:00:00'
根据业务周期决定花大量时间做全量的修复
增量:每天调度 crontab xxx.sh
2019-06-29 01:00:00 启动作28号数据
select count(1) from a where
cretime>='2019-06-14 00:00:00' and cretime<'2019-06-29 00:00:00' ; 根据业务周期,这里是15天
复盘
再有变动怎么办,复盘。
每月做1次全量,当前时间-1个月。

















 1448
1448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









