







Pod生命周期
一般将pod对象从创建至终止的这段时间范围称为pod的生命周期,它主要包含下面的过程:
- pod创建过程
- 运行初始化容器(init container)过程
- 运行主容器(main container)过程
- 容器启动后钩子(post start),容器终止前钩子(pre stop)
- 容器的存活性探测(liveness probe),就绪性探测(readness probe)
- pod终止过程

在整个声明周期中,Pod会出现5种状态(相位),如下:
- 挂起(Pending):挨批server已经创建了pod资源对象,但它尚未被调度完成或者仍处于下载镜像的过程中
- 运行中(Running):pod已经被调度至某节点,并且所有容器都已经被kubectl创建完成
- 成功(Succeed):pod中的所有容器都已经成功终止并且不会被重启
- 失败(Failed):所有容器都已经停止,但至少有一个容器终止失败,即容器返回了非0的退出状态
- 未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败所致
二、Pod的创建过程
- 用户通过kubectl或其他api客户端提交需要创建的pod信息给apiServer
- apiServer开始生成pod对象的信息,并将信息存入etcd,然后返回确认信息至客户端
- apiServer开始反映etcd中的pod对象的变化,其他组件使用watch机制来跟踪检查apiServer上的变动
- scheduler发现有新的pod对象要创建,开始为pod分配足迹并将结果更新只apiServer
- node节点上的kubectl发现有pod调度过来,尝试调用docker启动容器,并将结果回送至apiServer
- apiServer将接收到的pod状态信息存入etcd中

三、Pod的终止过程
- 1、用户向apiServer发送删除pod对象的命令
- 2、apiServer中的pod对象信息随着时间的退役而更新,在宽限期内(默认30秒),pod被视为dead
- 3、将pod标记为terminating状态
- 4、kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程
- 5、端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点列表中移除
- 6、如果当前pod对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行
- 7、pod对象的容器进程收到停止信号
- 8、宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到吉利终止的信号
- 9、kubelet请求apiServer将此pod资源的款限制设置为0从而完成删除操作,此时pod对于用户已不可见
pod重启策略和状态解释
一、重启策略:Pod在遇到故障之后重启的动作
1:Always:当容器终止退出后,总是重启容器,默认策略
2:OnFailure:当容器异常退出(退出状态码非0)时,重启容器
3:Never:当容器终止退出,从不重启容器。
(注意:k8s中不支持重启Pod资源,只有删除重建,重建)
1、always
vim always.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 30; exit 3

kubectl apply -f always.yaml
1
创建中

运行中

出错了

立即重启

证明重启策略默认是always,总是自动拉取
2、never
vim never.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo01
namespace: zy
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 30; exit 3
restartPolicy: Never
kubectl apply -f never.yaml
这时pod故障后就不一直重启了
3、onfailure
3.1 非0状态
vim onfailure.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo02
namespace: zy
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 20; exit 3
restartPolicy: OnFailure
kubectl apply -f onfailure.yaml
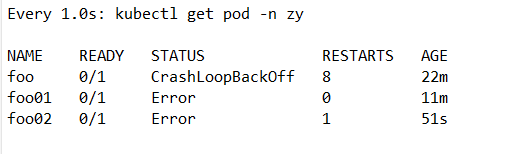
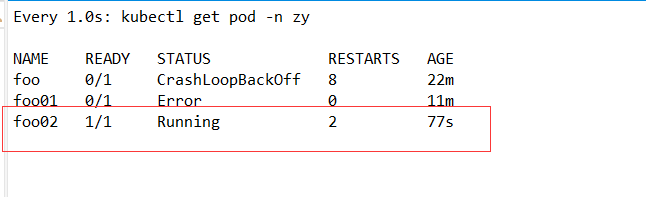
3.2 为0状态
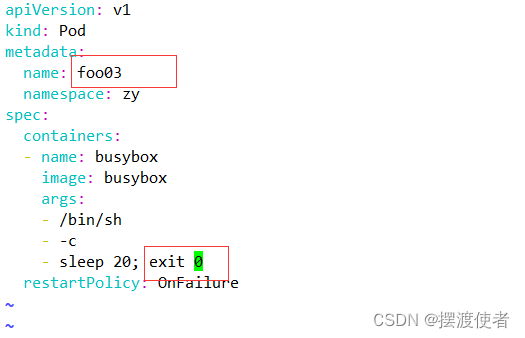
mv onfailure.yaml onfailure0.yaml
vim onfailure0.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo03
namespace: zy
spec:
containers:
- name: busybox
image: busybox
args:
- /bin/sh
- -c
- sleep 20; exit 0
restartPolicy: OnFailure
kubectl apply -f onfailure0.yaml
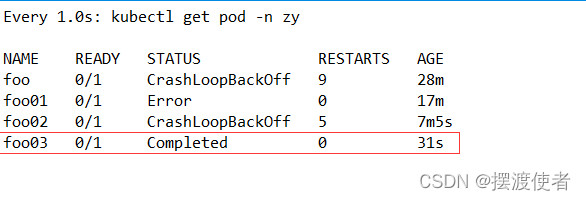
退出后显示的完成,说明正常退出,只是完成了这个动作,并不是错误。
[root@master test]# kubectl delete -f .
pod "foo" deleted
pod "foo01" deleted
pod "foo03" deleted
二、探针
健康检查:又称为探针(Probe)
(注意:)规则可以同时定义
livenessProbe(存活性探针) 如果检查失败,将杀死容器,根据Pod的restartPolicy来操作。
ReadinessProbe(就绪性探针) 如果检查失败,kubernetes会把Pod的IP:port信息从service endpoints中剔除。
Probe支持三种检查方法:
httpGet发送http(的GET)请求,返回200-400范围状态码为成功。
exec执行 shell命令返回状态码是0为成功(例如:/bin/sh -c cat /var/run/nginx.pid)。
tcpSocket 发起TCP Socket建立成功(三次握手的方式建立连接,建立成功,则为健康、否则,则为失败)
1、exec
vim exec.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
namespace: zy
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
在配置文件中,您可以看到/Pod具有单个Container ,该period9econds 字段指定Kucaeet应该每5秒执行一次活动性探测。该initialle1sy$conda字股告诉知cbee在执行第一个保影之前应等待5秒。为了执行探测,kubet cat /try/heolthy在容器中执行命令。如果命令成功执行,则返回,并且lubelet认l为Container仍然健康。如果命令返回非零值,则妙火ubelet将杀死Container并重新启动它。
附:pod各种状态解释:
1、Pod一直处于Pending状态
Pending状态意味着Pod的YAML文件已经提交给Kubernetes,API对象已经被创建并保存在Etcd当中。但是,这个Pod里有些容器因为某种原因而不能被顺利创建。比如,调度不成功(可以通过kubectl describe pod命令查看到当前Pod的事件,进而判断为什么没有调度)。可能原因:资源不足(集群内所有的Node都不满足该Pod请求的CPU、内存、GPU等资源);HostPort.已被占用(通常推荐使用Service对外开放服务端口)。
2、Pod一直处于Waiting 或 ContainerCreating状态
首先还是通过 kubectl describe pod命令查看当前Pod的事件。可能的原因有:
1、镜像拉取失败,比如镜像地址配置错误、拉取不了国外镜像源(gcr.io)、私有镜像密钥配置错误、镜像太大导致拉取超E(可以适当调整kubelet的-image-pull-progress-deadline和-runtime-request-timeout选项)等。
2、CNI网络错误,一般需要检查CNI网络插件的配置,比如:无法配置Pod 网络、无法分配IP地址。
3、容器无法启动,需要检查是否打包了正确的镜像或者是否配置了正确的容器参数
4、Failed create pod sandbox,查看kubelet日志,原因可能是磁盘坏道(input/output error)。
Pod 一直处于ImagePullBackOff状态
通常是镜像名称配置错误或者私有镜像的密钥配置错误导致。
3、Pod 一直处于CrashLoopBackOff状态
此状态说明容器曾经启动了,但又异常退出。这时可以先查看一下容器的日志。
通过命令kubectl logs 和kubectl logs --previous 可以发下一些容器退出的原因,比如:容器进程退出、健康检查失败退出;此时如果还未发现线索,还而已到容器内执行命令(kubectl exec cassandra - cat /var.log/cassandra/system.loq)来进一步查看退出原因;如果还是没有线索,那就需要SSH登录该Pod所在的Node上,查看Kubelet或者Docker的日志进一步排查。
4、Pod处于Error状态
通常处于Error状态说明Pod启动过程中发生了错误。常见的原因:依赖的ConfigMap、Secret或PV等不存在;请求的资源超过了管理员设置的限制,比如超过了LimitRange等;违反集群的安全策略,比如违反了PodSecurityPolicy.等;容器无法操作集群内的资源,比如开启RDAC后,需要为ServiceAccount配置角色绑定。
5、Pod 处于Terminating或 Unknown状态
从v1.5开始,Kubernetes,不会因为Node失联而删除其上正在运行的Pod,而是将其标记为Terminating或 Unknown 状态。想要删除这些状态的Pod有三种方法:
1、从集群中删除Node。使用公有云时,kube-controller-manager会在VM删除后自动删除对应的Node
而在物理机部署的集群中,需要管理员手动删除Node (kubectl delete node)。
2、Node恢复正常。,kubelet会重新跟kube-apiserver通信确认这些Pod的期待状态,进而再决定删除或者继续运行这些Pod,用户强制删除,用户可以执行(kubectl delete pods pod-name --grace-period=0 --force)强制删除Pod。除非明确知道pod的确处于停止状态)比如node所在VM或物理机已经关机,否则不建议使用该方法,特别时statefulset管理的POD
————————————————
版权声明:本文为优快云博主「摆渡使者」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/yan_0916/article/details/123190845
kubectl get pod
查看所有命名空间中的Pod或者deployment:
kubectl get pods -A
过滤掉系统的:
kubectl get pod -A |grep -v kube-system
看所有Pod都在哪些节点上运行:
kubectl get pod -A -o yaml |grep '^ n'|grep -v nodeSelector|awk 'NR%3==1{print ++n"\n"$0;next}1'
过滤掉系统中的Pod
kubectl get pod -A -o yaml |grep '^ n'|grep -v nodeSelector|sed 'N;N;s/\n/ /g'|grep -v kube-system
查看所有namespace中的Deployment:
kubectl get deploy -A
查看命名空间:kube-system:是 namespace 名称
查看命名空间:kube-system,kubectl get all -n kube-system
查询 jenkins 命名空间下的 pod, kubectl get pod -n jenkins:
查询 jenkins 命名空间下的 deployment,kubectl get deployment -n jenkins
删除deployment(先删除deployment,删除后replicaset.apps 和 pod 自动就被删除了)
kubectl delete deployment.apps/nginx-1596365264-controller -n kube-system
kubectl delete deployment.apps/nginx-1596365264-default-backend -n kube-system
kubectl delete deployment jenkins2 -n jenkins :删除 jenkins 命名空间下的 jenkins2 的 deployment ,删除deployment 之后 pod 自动删除
删除 service
kubectl delete service/nginx-1596365264-controller -n kube-system
kubectl delete service/nginx-1596365264-default-backend -n kube-system
问题排查:pod一直处于Pending状态

kubectl describe pod jenkins-0
排查结果:意思是内存和CPU不足
解决办法第一步:修改内存和CPU后报错如何:
kubectl apply -f jenkins-statefulset.yaml
#输出提示:
The StatefulSet "jenkins" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'template', and 'updateStrategy' are forbidden
意思是除了 'replicas', 'template', 'updateStrategy' 其他部分都是不可以改的。
二、解决办法第二步:备份一下当前 statefulset 的配置文件 把当前的 statefulset删掉 重新apply新的文件。
cp jenkins-statefulset.yaml jenkins-statefulset-new.yaml
#jenkins为name
kubectl delete statefulsets.apps jenkins
#或基于配置文件来删除
kubectl delete -f jenkins-statefulset.yaml
重新apply新的文件。
kubectl apply -f jenkins-statefulset-new.yaml
————————————————
版权声明:本文为优快云博主「远航灯塔」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
问题排查:k8s的pod删除方法
背景:
有个环境中是想删除某个pod,但不删除其他4个pod,5个pod都是有一个deploy.yaml生成的,拉起策略为always
尝试,删除指定pod,但会被迅速拉起:
kubectl delete pod nginx-66bbc9fdc5-smzsc
然后看了网上的文章说是要连同deployment一起删除,先解决掉容灾策略才能删除。
尝试了之后发现,deployment删除之后会连同所有pod一起删除,因为所有pod都是在同一个deploy.yaml创建的,所以只能缩容了,修改副本的数量,当缩容时,会随机关掉两个pod,但是其他的pod不会受影响。
kubectl edit deploy nginx
还有一个缩容的语句,也可以完成类似的效果
kubectl scale --replicas=3 deploy nginx
经过尝试在statefulSet中可以通过非级联删除先把statefulSet删除,使pod没有依赖,即可删除指定pod
kubectl delete sts web --cascade=false
--cascade=false 不添加这个参数就是级联删除
但是statefulSet删除后,删除某一个pod会导致一个可以忽略报错说:
Error from server (AlreadyExists): error when creating “stat.yaml”: services “nginx” already exists
会恢复之前删除的pod
————————————————
版权声明:本文为优快云博主「贮藏的仓鼠」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/qq_42391153/article/details/121029169

















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









