



今天收到一个朋友的来信:说我的网站的字太小了。我去Analytics上看了一下,其中的WEB设计参数中,有一个屏幕分辨率的指标。目前我的网站上使用analytics的统计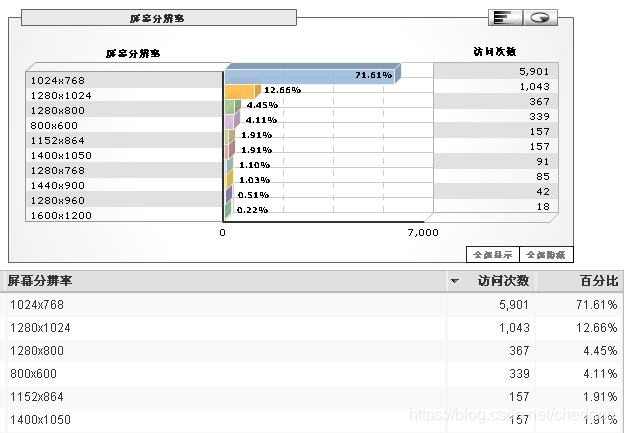
来访者有95%以上的用户是使用1024分辨率以上(包括我自己看),为什么还要用那么小的字体呢?修改了一下style,把首页上所有 12px的字体都改成了14px(其实应该尽量避免使用固定象素大小字体,使用相对大小更好一些),之所以选择14px象素,因为我的网站有1/6左右是Firefox用户,单数大小字体对他们不适合。
如果你看到的首页还是小字体,请按F5强制刷新一下。
如果不满意还可以投上一票:
后记:
感谢各位的留言,最后发现遵循数字变成尊重自己了,改字体要考虑的东西太多了。
1 屏幕的分辨率;
2 屏幕物理大小:14寸屏幕/15寸屏幕/17寸以上屏幕,还真的没有办法拿到用户的屏幕硬件尺寸数据,但是目前主流屏幕应该是14/15寸吧,我就是用14寸的显示屏的,字体大点我觉得还能接受;
3 IE浏览器:是否启用了自动圆润字体;
无论如何,只能说明这方面我的确不专业啊……
网站设计:需要尊重数字,更重要的是看到数字,需要做出改变。
更新 2006-12-14
1 首页内容范围的生成策略也修改了,由原来的40个小时内的内容变成了36个小时以内的。
2 字体之间的行距增加了 50%: line-hight: 150%
版权声明:可以转载,转载时请务必以超链接形式标明文章 首页的字体改大了 的原始出处和作者信息及 本版权声明。
http://www.chedong.com/blog/archives/001253.html
« FAN: FeedBurner Ads Network 先批准后发布的feed广告发布 | (回到Blog入口)|(回到首页) | 豆瓣在全世界的长尾用户群 » [再编辑]


















 3275
3275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









