




✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或扫描文章底部二维码。
(1)基于工作流引擎的选煤工艺流程计算方法与可视化设计
选煤工艺流程的计算是整个生产管理体系中的核心环节,传统的计算方法往往依赖于固定的流程模板和人工干预,缺乏灵活性和通用性。为了解决这一问题,本研究将工作流引擎技术引入选煤工艺流程计算领域,通过对选煤生产过程的深入分析,建立了一套完整的工艺流程建模与计算框架。在实际选煤生产中,不同选煤厂的工艺流程存在较大差异,这种差异主要体现在设备配置、工艺参数设置以及产品结构要求等方面。因此,构建一个能够适应不同工艺流程需求的通用计算平台显得尤为重要。
在工艺流程建模方面,本研究首先对选煤生产过程进行了系统化的分解与归纳。通过对国内外数十家大中型选煤厂的实地调研和工艺流程分析,将复杂多样的选煤工艺操作归纳为筛分作业、破碎作业和分选作业三大基本类型。筛分作业主要包括原煤准备筛分、分级筛分、脱水脱介筛分等环节,这些环节在不同粒级煤炭的分离和准备过程中发挥着关键作用。破碎作业则涉及颚式破碎机、锤式破碎机、齿辊破碎机等多种设备类型,用于将大块煤炭破碎至符合后续加工要求的粒度范围。分选作业是选煤工艺的核心环节,包括跳汰分选、重介质分选、浮选等多种工艺方法,每种方法都有其特定的适用条件和技术参数。
在完成工艺分类的基础上,本研究进一步将每类作业细化为具体的设备模块单元。以重介质分选为例,将其细分为重介旋流器模块、重介浅槽模块、重介立轮分选机模块等,每个模块对应一种或一类具有相似工作原理的选煤设备。为了实现这些模块在计算系统中的标准化表示,设计了一套图形化的元素符号体系,使得工艺人员能够通过直观的拖拽操作完成流程设计。这种图形化设计方式不仅降低了系统使用门槛,也使得工艺流程的修改和调整变得更加便捷。每个设备模块都包含了完整的模型定义,明确规定了输入物料的数量、质量特性参数,输出产品的种类、产率和质量指标,以及设备运行所需的关键工艺参数如分选密度、介质消耗、处理能力等。
工作流引擎在选煤工艺流程计算中的应用是本研究的创新点之一。传统的流程计算往往采用顺序执行的方式,当流程结构复杂、存在多个分支和合并节点时,计算逻辑的实现变得异常复杂。工作流引擎技术通过定义节点和连接的执行规则,能够自动处理流程中的并行、分支、循环等复杂逻辑关系。在本研究中,将每个选煤设备模块视为工作流中的一个节点,物料流向则对应节点之间的连接关系。通过定义节点的激活条件、执行动作和输出规则,实现了选煤工艺流程计算的自动化推进。当某个节点的所有输入物料都到达并满足质量要求时,该节点自动激活并执行相应的数学模型计算,计算完成后将结果传递给下游节点,如此循环直至整个流程计算完成。
为了保证工艺流程设计的合理性和计算结果的准确性,本研究建立了一套完整的流程逻辑检验机制。这套机制分为必验规则检验和数据检验规则两个层次。必验规则主要检查流程的结构完整性,包括是否存在孤立节点、是否所有输入端口都有物料来源、是否存在闭环回路导致的死锁等问题。数据检验规则则关注物料特性和设备能力的匹配性,例如检查输入物料的粒度是否在设备处理范围内、分选密度设置是否合理、处理能力是否满足生产需求等。这些检验规则的实施能够在流程计算执行前发现潜在问题,避免因流程设计缺陷导致的计算错误或生产事故。在实际应用中,系统会自动执行这些检验规则,并以可视化的方式向用户反馈检验结果,对于不符合规则的设计给出明确的错误提示和修改建议。
在工作流节点排序算法的研究中,针对选煤工艺流程中常见的顺序流、并行流和分支合并流等结构特点,开发了一种基于拓扑排序的节点执行顺序确定方法。该算法首先构建工艺流程的有向图模型,以设备模块为节点,以物料流向为有向边,然后通过分析节点的入度和出度关系,确定各节点的依赖关系和执行优先级。对于并行分支的处理,算法能够识别出可以同时执行的节点集合,从而提高计算效率。对于分支合并节点,算法会等待所有上游分支的计算结果都到达后再执行合并计算,确保物料平衡和质量指标计算的准确性。这种基于拓扑排序的方法能够自动适应不同复杂度的工艺流程结构,无需人工干预即可生成正确的计算执行序列。
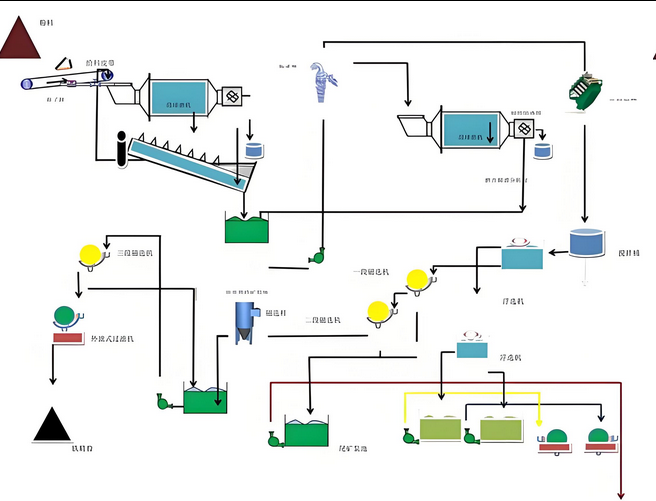
(2)选煤工艺数学模型的模块化开发与混合编程实现
选煤工艺流程计算的核心是各类选煤作业的数学模型,这些模型的准确性直接决定了流程计算结果的可靠性。本研究针对选煤生产中的主要工艺环节,系统地研究开发了一系列数学模型,并通过模块化封装的方式实现了模型的标准化和可重用性。在筛分作业建模方面,综合考虑了筛分效率、物料粒度分布、水分含量等多个影响因素,建立了基于概率筛分理论的数学模型。该模型能够根据入料的粒度组成和筛孔尺寸,计算筛上物和筛下物的产率及粒度分布,同时考虑了难筛颗粒和细粒级夹带等实际生产中的常见现象。通过引入筛分效率曲线的概念,模型能够更准确地反映不同粒级颗粒的筛分行为差异。
跳汰分选是重力选煤的重要方法之一,其数学模型的建立需要深入理解物料在脉动介质中的分层机理。本研究基于跳汰分选的理论基础,结合大量生产实践数据,建立了跳汰分选的产品预测模型。该模型以入料的密度组成曲线为基础,通过引入分选精度指标和可能偏差参数,计算不同密度级的物料在精煤、中煤和矸石中的分配比例。为了提高模型的实用性,还考虑了跳汰机的操作参数如冲程、冲次、水流量等对分选效果的影响,建立了参数与分选精度之间的关联关系。这种关联关系的建立基于对多个选煤厂跳汰分选数据的统计分析和机器学习算法的应用,使得模型能够根据实际生产条件进行动态调整。
三产品重介旋流器是现代选煤工艺中应用最为广泛的分选设备之一,其分选过程涉及复杂的流体力学和颗粒分离机理。本研究针对三产品重介旋流器的工作特点,建立了基于密度分配曲线的分选模型。该模型将旋流器的分选过程分解为粗粒级分选和细粒级分选两个子过程,每个子过程都有独立的分选密度和分选精度参数。通过对入料进行密度级划分,逐个密度级地计算其在精煤、中煤和矸石中的分配率,最终汇总得到三种产品的产率和质量指标。为了准确描述分选过程的不完善性,模型中引入了可能偏差的概念,该参数能够反映设备的分选精度水平,可能偏差越小表示分选效果越好。在模型参数的确定方面,采用了基于历史生产数据的参数辨识方法,通过对实际生产记录的统计分析,确定不同工况下的最优模型参数。
浮选作业是细粒级煤炭分选的主要手段,其数学模型的建立相对复杂。浮选过程不仅涉及煤炭颗粒的密度差异,还与颗粒表面性质、矿浆化学环境、药剂添加量等多种因素密切相关。本研究在充分考虑这些影响因素的基础上,建立了基于浮选动力学的数学模型。该模型将浮选过程视为一个动态的质量传递过程,通过建立微分方程组描述不同时刻精煤和尾煤的产率变化规律。模型中的关键参数包括浮选速度常数、最大可浮率等,这些参数的确定需要通过实验室浮选试验或现场工业试验获得。为了提高模型的通用性,研究中还建立了模型参数与煤质特性、药剂制度之间的经验关系式,使得模型能够应用于不同煤种和工艺条件。
在数学模型的实现技术方面,本研究采用了C#与MATLAB混合编程的策略。C#作为.NET平台的主要开发语言,具有良好的界面开发能力和系统集成能力,适合用于构建工艺流程设计界面和数据管理功能。而MATLAB在数值计算和矩阵运算方面具有显著优势,特别适合用于实现复杂的数学模型算法。通过混合编程,将MATLAB实现的数学模型编译为COM组件或.NET程序集,然后在C#程序中进行调用,既保证了数值计算的效率和精度,又实现了友好的用户交互界面。在具体实现过程中,对每个数学模型都进行了标准化的接口设计,明确定义了输入参数的数据类型、取值范围和物理意义,以及输出结果的格式和精度要求。这种标准化的接口设计使得不同模块之间能够无缝连接,为工艺流程的灵活组合奠定了基础。
为了验证数学模型的准确性和可靠性,本研究进行了大量的模型验证工作。验证方法主要包括与选煤厂实际生产数据的对比和与传统计算方法结果的对比。选取了多个典型选煤厂的生产数据,包括不同煤种、不同工艺流程、不同设备配置的案例,将模型计算结果与实际生产记录进行对比分析。统计结果表明,主要产品的产率预测误差控制在百分之三以内,灰分、硫分等质量指标的预测误差控制在百分之五以内,达到了工程应用的精度要求。同时,还将本研究开发的模型与国内外现有的选煤计算软件进行了对比测试,结果显示本研究的模型在计算精度和适用范围方面都具有一定优势。这些验证工作不仅证明了模型的有效性,也为模型的进一步改进和完善提供了数据支持。
(3)基于遗传算法的选煤产品结构优化方法
选煤产品结构优化是提高选煤厂经济效益的重要途径,其本质是在满足市场需求和生产约束条件下,通过调整工艺参数来优化产品产率和质量,从而实现经济效益最大化。传统的优化方法如穷举法虽然能够保证找到全局最优解,但当优化变量较多时,计算量呈指数级增长,实际应用受到很大限制。本研究采用遗传算法作为优化工具,有效解决了多参数优化的计算效率问题。遗传算法是一种模拟自然界生物进化过程的优化算法,通过选择、交叉和变异等遗传操作,在解空间中进行全局搜索,能够在合理的计算时间内找到接近最优的解。
在构建经济效益数学模型时,本研究综合考虑了影响选煤厂经济效益的各种因素。首先是产品价格体系,不同质量等级的煤炭产品在市场上的价格存在显著差异,通常情况下精煤价格最高,中煤次之,煤泥和矸石价格较低甚至需要支付处理费用。价格体系的建立需要考虑市场供需关系、运输距离、用户要求等多种因素,在模型中以灰分和硫分为主要定价指标,建立了价格与质量指标的函数关系。其次是生产成本,包括原煤成本、洗选加工成本、介质消耗、电力消耗、人工成本等多个组成部分。其中洗选加工成本与处理量和工艺复杂度密切相关,通过对多个选煤厂成本数据的分析,建立了单位产品加工成本的计算模型。介质消耗是重介质选煤厂的重要成本项,与产品产量和介质回收效率有关,在模型中根据不同产品的介质携带量和回收系统效率进行计算。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Data;
namespace CoalProcessOptimization
{
public class WorkflowEngine
{
private List<ProcessNode> nodes;
private List<MaterialFlow> flows;
private Dictionary<string, object> globalParams;
public WorkflowEngine()
{
nodes = new List<ProcessNode>();
flows = new List<MaterialFlow>();
globalParams = new Dictionary<string, object>();
}
public void AddNode(ProcessNode node)
{
if (node != null && !nodes.Contains(node))
{
nodes.Add(node);
}
}
public void AddFlow(MaterialFlow flow)
{
if (flow != null && !flows.Contains(flow))
{
flows.Add(flow);
}
}
public List<ProcessNode> TopologicalSort()
{
Dictionary<ProcessNode, int> inDegree = new Dictionary<ProcessNode, int>();
Dictionary<ProcessNode, List<ProcessNode>> adjList = new Dictionary<ProcessNode, List<ProcessNode>>();
foreach (var node in nodes)
{
inDegree[node] = 0;
adjList[node] = new List<ProcessNode>();
}
foreach (var flow in flows)
{
adjList[flow.SourceNode].Add(flow.TargetNode);
inDegree[flow.TargetNode]++;
}
Queue<ProcessNode> queue = new Queue<ProcessNode>();
foreach (var node in nodes)
{
if (inDegree[node] == 0)
{
queue.Enqueue(node);
}
}
List<ProcessNode> sortedNodes = new List<ProcessNode>();
while (queue.Count > 0)
{
ProcessNode current = queue.Dequeue();
sortedNodes.Add(current);
foreach (var neighbor in adjList[current])
{
inDegree[neighbor]--;
if (inDegree[neighbor] == 0)
{
queue.Enqueue(neighbor);
}
}
}
return sortedNodes;
}
public bool ValidateWorkflow()
{
if (nodes.Count == 0) return false;
foreach (var node in nodes)
{
if (node.RequiredInputs > 0)
{
int inputCount = flows.Count(f => f.TargetNode == node);
if (inputCount != node.RequiredInputs)
{
return false;
}
}
}
List<ProcessNode> sorted = TopologicalSort();
return sorted.Count == nodes.Count;
}
public void ExecuteWorkflow()
{
List<ProcessNode> executionOrder = TopologicalSort();
foreach (var node in executionOrder)
{
node.Execute();
}
}
}
public class ProcessNode
{
public string NodeId { get; set; }
public string NodeName { get; set; }
public NodeType Type { get; set; }
public int RequiredInputs { get; set; }
public Dictionary<string, double> Parameters { get; set; }
public List<MaterialStream> InputStreams { get; set; }
public List<MaterialStream> OutputStreams { get; set; }
public ProcessNode()
{
Parameters = new Dictionary<string, double>();
InputStreams = new List<MaterialStream>();
OutputStreams = new List<MaterialStream>();
}
public virtual void Execute()
{
switch (Type)
{
case NodeType.Screening:
ExecuteScreening();
break;
case NodeType.Crushing:
ExecuteCrushing();
break;
case NodeType.Jigging:
ExecuteJigging();
break;
case NodeType.HeavyMedium:
ExecuteHeavyMedium();
break;
case NodeType.Flotation:
ExecuteFlotation();
break;
}
}
private void ExecuteScreening()
{
if (InputStreams.Count == 0) return;
MaterialStream input = InputStreams[0];
double screenSize = Parameters["ScreenSize"];
double efficiency = Parameters["Efficiency"];
MaterialStream oversize = new MaterialStream();
MaterialStream undersize = new MaterialStream();
oversize.FlowRate = input.FlowRate * CalculateOversizeYield(input, screenSize, efficiency);
undersize.FlowRate = input.FlowRate - oversize.FlowRate;
oversize.Ash = CalculateOversizeAsh(input, screenSize);
undersize.Ash = CalculateUndersizeAsh(input, screenSize);
OutputStreams.Add(oversize);
OutputStreams.Add(undersize);
}
private void ExecuteCrushing()
{
if (InputStreams.Count == 0) return;
MaterialStream input = InputStreams[0];
double targetSize = Parameters["TargetSize"];
MaterialStream output = new MaterialStream();
output.FlowRate = input.FlowRate;
output.Ash = input.Ash;
output.Sulfur = input.Sulfur;
output.AverageSize = targetSize;
OutputStreams.Add(output);
}
private void ExecuteJigging()
{
if (InputStreams.Count == 0) return;
MaterialStream input = InputStreams[0];
double separationDensity = Parameters["SeparationDensity"];
double probableError = Parameters["ProbableError"];
List<MaterialStream> products = PerformDensitySeparation(input, separationDensity, probableError, 3);
OutputStreams.AddRange(products);
}
private void ExecuteHeavyMedium()
{
if (InputStreams.Count == 0) return;
MaterialStream input = InputStreams[0];
double density1 = Parameters["Density1"];
double density2 = Parameters["Density2"];
double ep1 = Parameters["EP1"];
double ep2 = Parameters["EP2"];
MaterialStream clean = new MaterialStream();
MaterialStream middling = new MaterialStream();
MaterialStream refuse = new MaterialStream();
double[] yields = CalculateThreeProductYields(input, density1, density2, ep1, ep2);
clean.FlowRate = input.FlowRate * yields[0];
middling.FlowRate = input.FlowRate * yields[1];
refuse.FlowRate = input.FlowRate * yields[2];
clean.Ash = CalculateProductAsh(input, 0, density1, ep1);
middling.Ash = CalculateProductAsh(input, density1, density2, ep2);
refuse.Ash = CalculateProductAsh(input, density2, 999, ep2);
OutputStreams.Add(clean);
OutputStreams.
如有问题,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇


















 1644
1644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











