



 本文介绍了如何使用Python和相关库(如BeautifulSoup和PDFKit)抓取TensorFlow官方文档的中文页面,并将其转换为PDF格式。方法包括获取网页内容、处理图片和下载链接,适用于学习者进行技术资料整理。
本文介绍了如何使用Python和相关库(如BeautifulSoup和PDFKit)抓取TensorFlow官方文档的中文页面,并将其转换为PDF格式。方法包括获取网页内容、处理图片和下载链接,适用于学习者进行技术资料整理。
大家好,小编来为大家解答以下问题,python中文下载安装教程,python documentation中文版,今天让我们一起来看看吧!
Source code download: 本文相关源码
Note:
如果涉及侵权等问题,求留言通知
Requirements:
- beautifulsoup4
- requests
- pdfkit (wkhtmltopdf官网下载,windows添加路径到环境变量,Linux下载安装也需要设置环境变量)
参考网页:
代码中的“自己的class"需要自己去替换, 也可留言交流。
# coding=utf-8
import pdfkit
import requests
from bs4 import BeautifulSoup
import os,re
from urllib.parse import urljoin
#获取网页所有的标题以及对应的地址
def parse_url_to_html(url,name):
heads = {'accept-language': 'zh-CN,zh;q=0.9', #以中文的形式访问
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
response=requests.get(url,headers = heads)
print(response.status_code) # 测试是否能链接到目标网站
soup=BeautifulSoup(response.content,"html.parser")
mainpages = []
maintitles= []
tag_main = soup.find_all(class_ = "devsite-section-nav devsite-nav nocontent")[0]#获取第一个class 为"devsite-section-nav devsite-nav nocontent"的标签,这个里面包含了网址和标题
#www.tensorflow.org 中的标题访问
for i in tag_main.find_all(class_ = "devsite-nav-item devsite-nav-item-section-expandable devsite-nav-accordion"): #按照需要进行选择
if i == None:
continue
else:
mainpages.append(i.span.get('href')) #获取1级标题 注意html中#为一部分,如果出现www.abc.html/#id, 需要访问前面的主网址即可
maintitles.append(i.span.get_text())
# 从Li的标签中获取2级标题
for j in i.find_all('li'):
mainpages.append(j.a.get('href'))
maintitles.append(j.a.get_text())
#将tag以文本的形式写入到目标文件中
htmls = "<html><head><meta charset='UTF-8'></head><body>"+str(tag_main)
with open(name+".html",'w',encoding='utf-8') as f:
f.write(htmls)
return mainpages, maintitles
def downlaodImage(url):
heads = {'accept-language': 'zh-CN,zh;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
response=requests.get(url,headers = heads)
soup=BeautifulSoup(response.content,"html.parser")
tag=soup.find_all(class_='自己查询正文对应的class') # www.tensorflow.org 中的文本访问
if tag == []: # github中的*.md(markdown)文件访问
tag=soup.find_all(class_='自己查询正文对应的class')
if tag == []:
tag=soup.find_all(class_='自己查询正文对应的class') # github中的.ipynb(jupynote notebook) 文件访问
flag = False
#为image添加相对路径,并下载图片
for img in tag[0].find_all('img'):
if img == []:
continue
flag = True
# 图片访问,注意urljoin的用法
im = requests.get(urljoin(url, img.get('src')))
filename = os.path.split(img['src'])[1] #从最后一个/分割成两部分
if '?' in filename: #
filename = filename.split('?')[0]
# 将图片写入image文件夹中
with open('image/' + filename, 'wb') as f:
f.write(im.content)
# 更改html文件中的图片源
img['src']='image/'+filename
return flag, response, soup, tag
#获取正文,并写入html
def get_htmls(url, mainpages,maintitles, name):
istart = 0 #方便从不同的标题测试
for i in range(istart,len(mainpages), 1): #len(allpages)):
urll = mainpages[i]
if urll == None:
h = "<div><h1>"+maintitles[i]+"</h1></div>" #大标题为一级
htmls = ''
htmls= h + htmls #str(tag[0])
with open(name+".html",'a',encoding='utf-8') as f:
f.write(htmls)
continue
flag, response, soup, tag = downlaodImage(urll) #下载图片
h =""
htmls = str(tag[0])
# 更改标题的级别,方便生成目录
pat = re.compile(r'<h3(.*?)</h3>',re.S) #re.S 贪婪匹配包含换行
htmls = re.sub(pat,r'<h4\1</h4>',htmls)
pat = re.compile(r'<h2(.*?)</h2>',re.S)
htmls = re.sub(pat,r'<h3\1</h3>',htmls)
pat = re.compile(r'<h1(.*?)</h1>',re.S)
htmls = re.sub(pat,r'<h2\1</h2>',htmls)
#写入正文
htmls= h + htmls
with open(name+".html",'a',encoding='utf-8') as f:
f.write(htmls)
print(" (%s) [%s] download end"%(i,mainpages[i]))
# 闭合parse_url_to_html中的标签
htmls="</body></html>"
with open(name+".html",'a',encoding='utf-8') as f:
f.write(htmls)
def save_pdf(html,name):
"""
把生成的html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
],
'cookie': [
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'outline-depth': 10,
'footer-font-name':'Times New Roman',
'header-font-name':'Times New Roman',
'minimum-font-size':24, #字体大小的控制
}
pdfkit.from_file(html, name+".pdf", options=options)
if __name__ == '__main__':
url = 'https://www.tensorflow.org/tutorials/'
name = 'Python TensorFlow'
if os.path.exists(name+'.html'):
os.remove(name+'.html')
if os.path.exists(name+'.pdf'):
os.remove(name+'.pdf')
mainpages, maintitles = parse_url_to_html(url,name)
get_htmls(url,mainpages, maintitles, name)
save_pdf(name+".html",name)
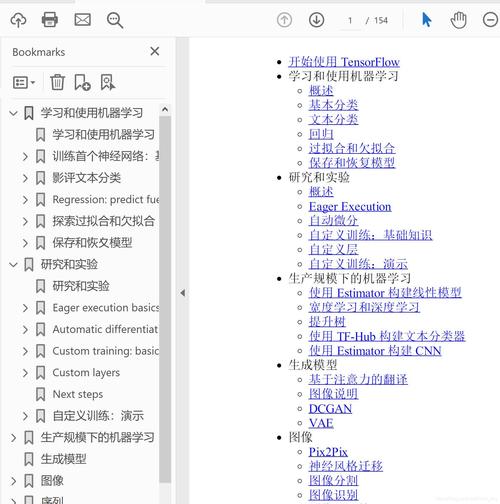
效果图如下: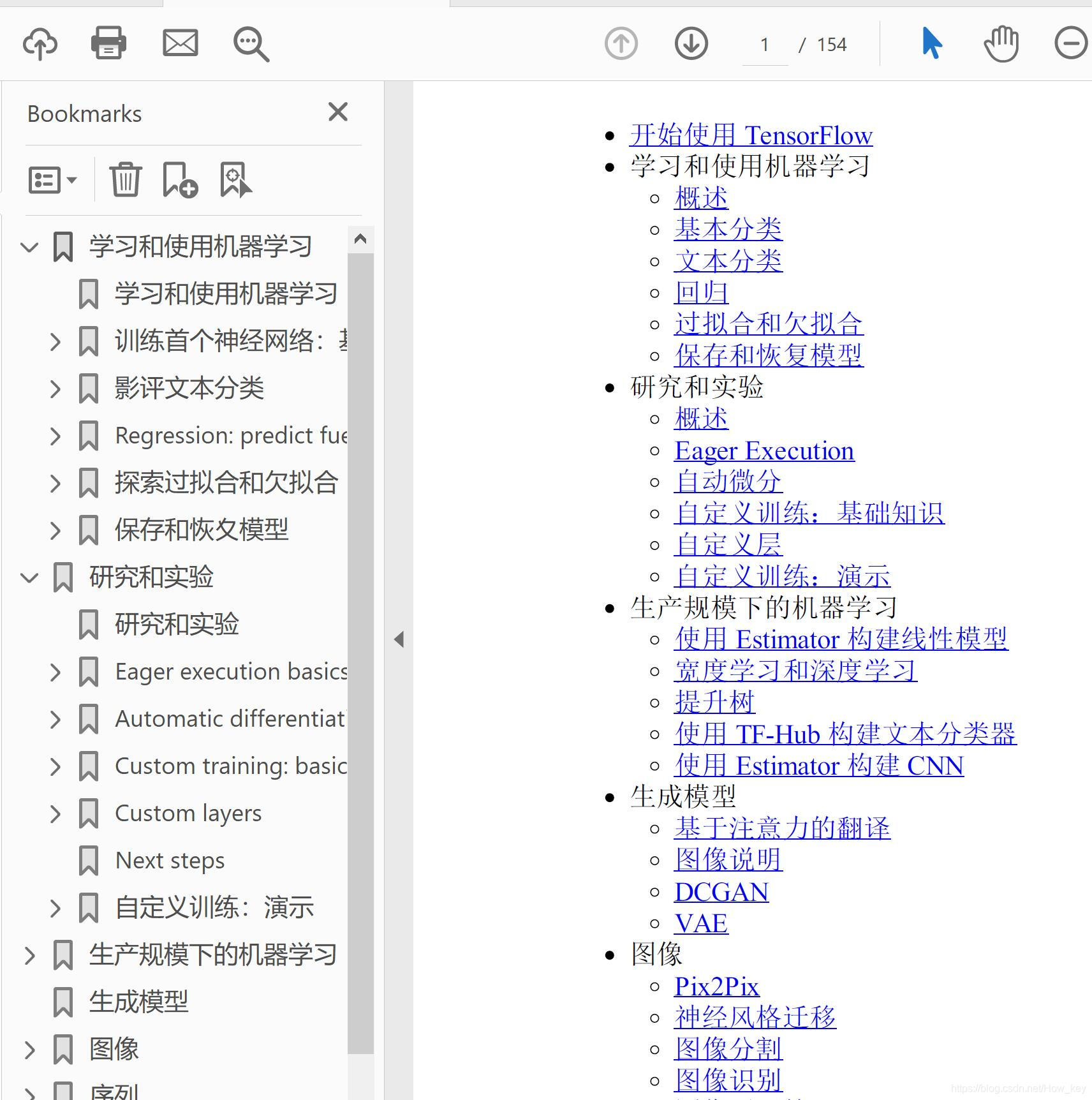

我的个人中心页上传了样本,如果有需要,请自行下载python含金量高的证书。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









