





你说的“司南”指的是 OpenCompass 司南大模型评测平台,由 上海人工智能实验室(Shanghai AI Lab) 推出,是一个面向大语言模型(LLM)和多模态模型的 权威评测与对比平台,核心功能包括:
✅ 核心定位
“大模型的竞技场” —— 让模型匿名对战,用户投票选出更优回答,最终形成 动态更新的 leaderboard(排行榜),解决“谁更强”这个终极问题。
✅ 主要功能模块
模块 说明
LLM Arena 匿名双盲对战,用户提问后两个模型同时回答,投票选出更好的一方,防止“刷分”或“品牌偏见”。
多模态 Arena 支持图文混合输入,评测多模态模型(如 Qwen-VL、InternVL、GPT-4V 等)。
任务模式 提供专项任务评测(如数学、代码、逻辑推理、中文理解等),可定向测试模型能力。
Compass Rank 基于真实用户投票+客观指标,定期发布排行榜,是目前中文社区最可信的模型榜单之一。
模型身份揭晓 投票结束后可查看模型真身,帮助开发者了解“到底谁输给了谁”。
---
✅ 技术亮点
- 匿名机制:防止“品牌光环”干扰判断,确保投票真实反映模型能力。
- 中文优化:大量中文主观题、文化题、时政题,弥补英文 benchmark 的盲区。
- 用户参与:任何人都能来“当裁判”,投票数据实时回流,榜单动态更新。
- 开源开放:评测框架 OpenCompass 已开源,支持开发者自定义数据集和任务。
适合谁用?
用户类型 用途
普通用户 想直观感受不同模型谁更“聪明”,比如 GPT-4o、Kimi、Qwen、Claude 到底差在哪。
开发者/企业 选型前先来“打擂台”,避免“宣传文案”误导,用真实表现说话。
研究机构 用匿名投票数据做主观评测研究,补充传统客观指标的不足。
---
✅ 一句话总结
OpenCompass 司南 是中文社区最活跃、最公正的大模型“实战擂台”,让模型在匿名状态下真刀真枪地比拼,用用户投票告诉你:
> 别信广告,信对战。
---
如果你想亲自体验,直接访问:
司南![]() https://opencompass.org.cn/arena大语言模型对战10个问题:
https://opencompass.org.cn/arena大语言模型对战10个问题:
进去随便问个问题,就能开始“当裁判”了。
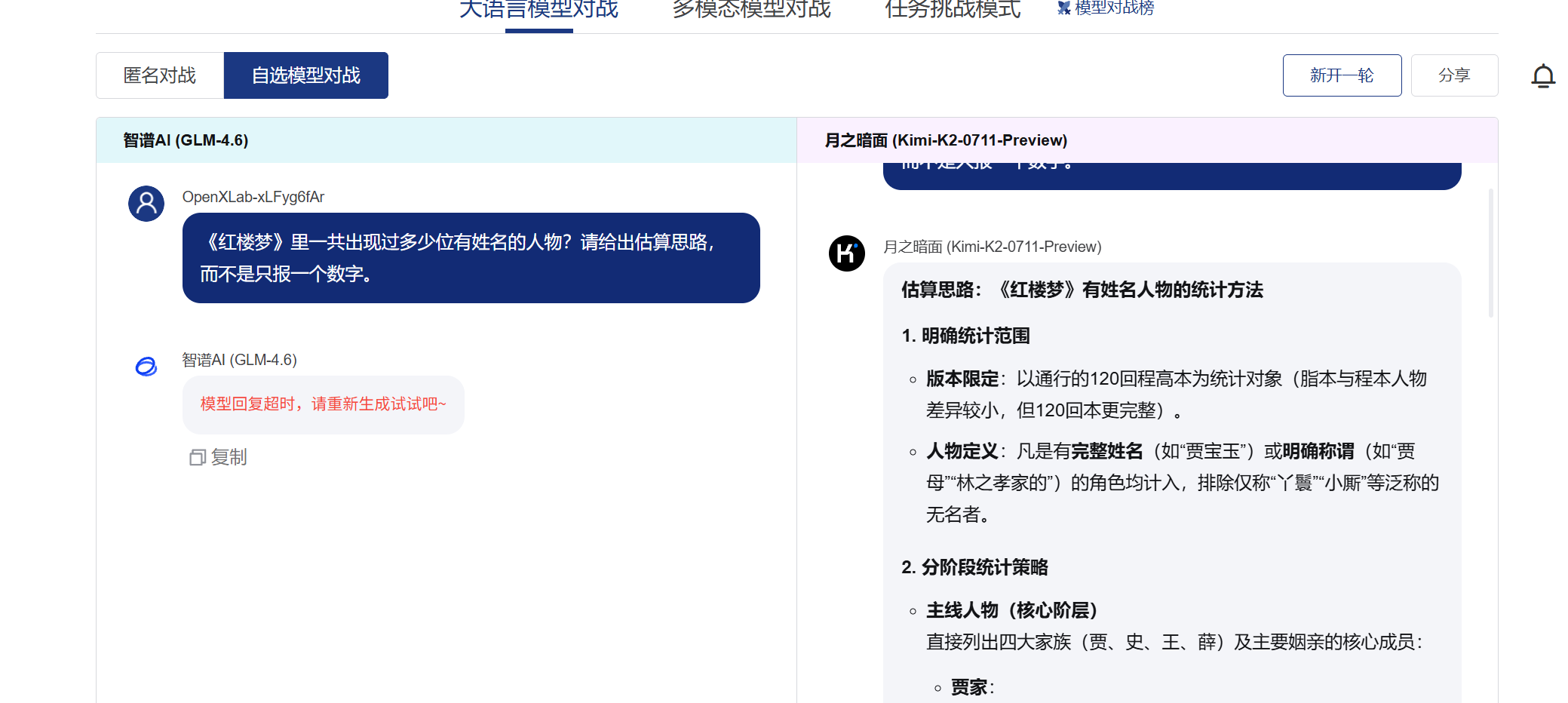
问题1:《红楼梦》里一共出现过多少位有姓名的人物?请给出估算思路,而不是只报一个数字。
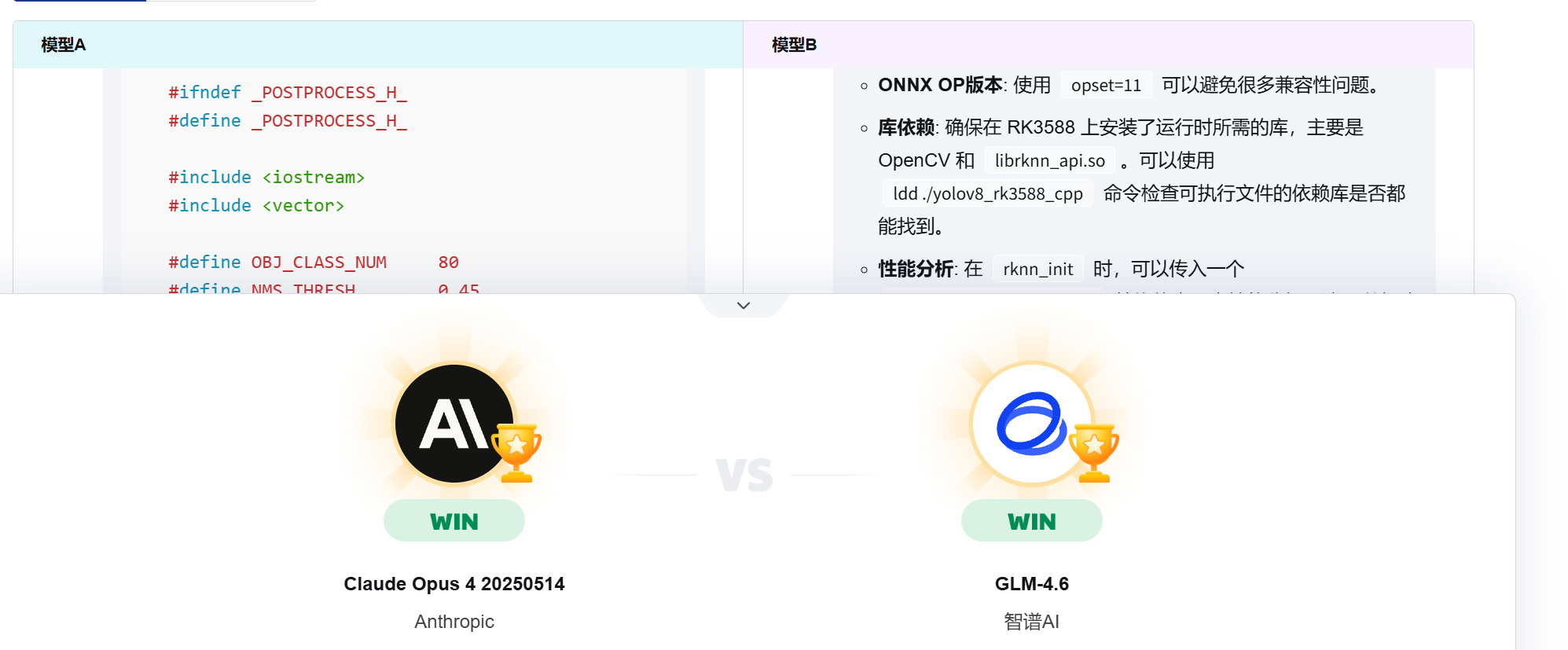
问题2:请帮我写一份将yolov8部署到rk3588开发板上的推理代码,用c++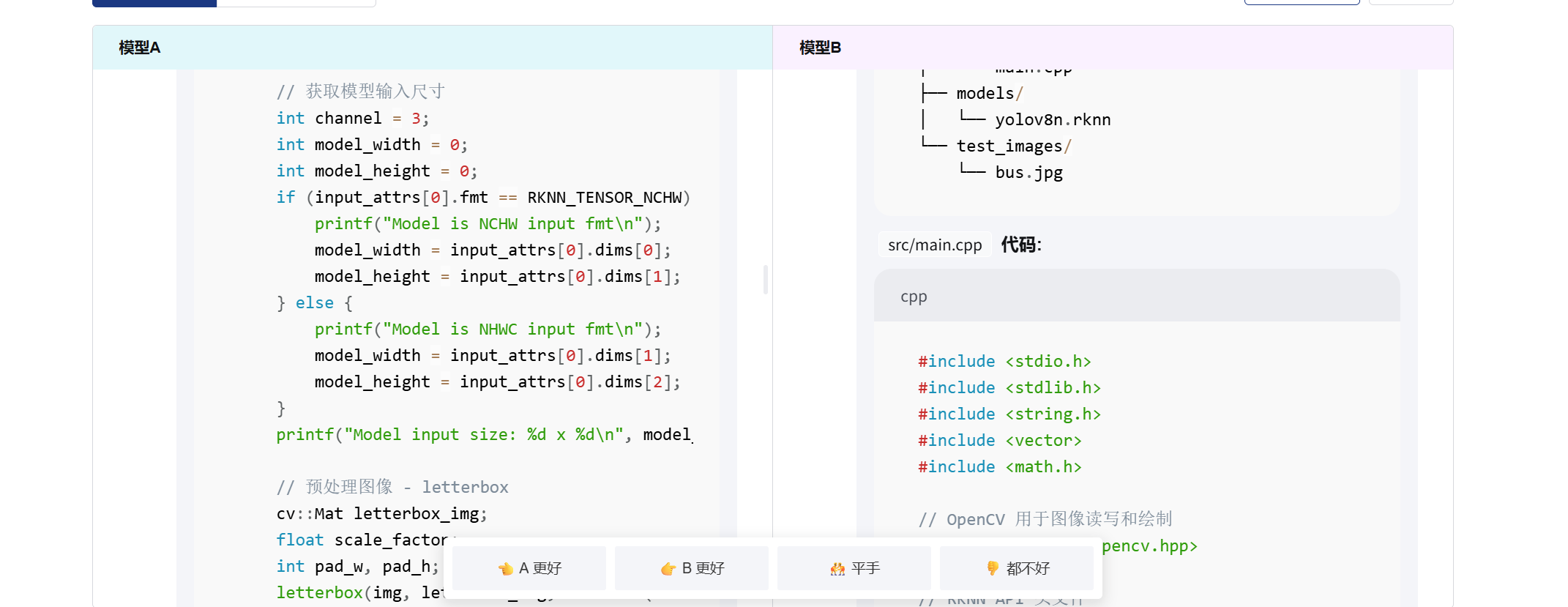
问题3:用一句话解释‘量子隧穿’,再用一个日常类比让初一学生听懂;最后指出类比在哪个点上其实不严谨。

问题4:2024 年 7 月 11 日央行下调常备借贷便利(SLF)利率 10 bp,请推链条:这一步如何影响中小银行负债成本→LPR→居民房贷?给出每环节大致传导时滞。

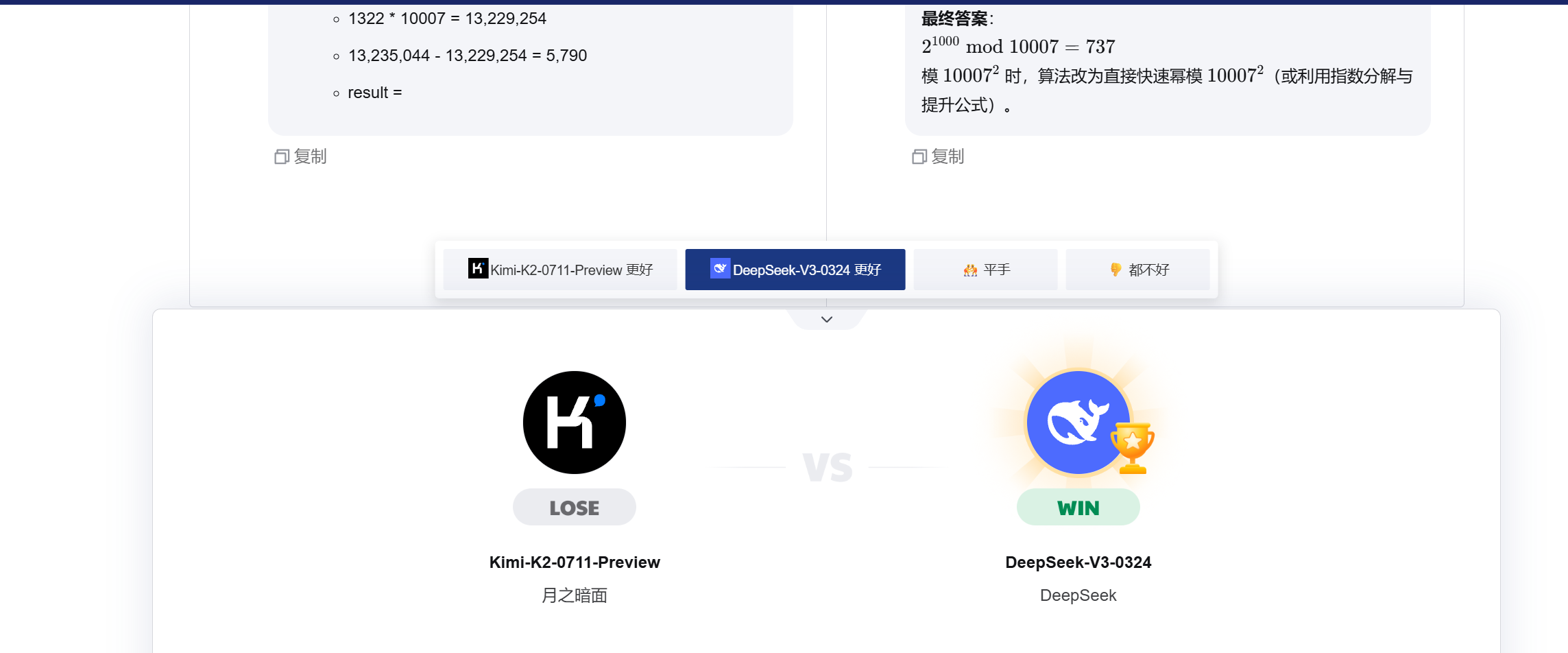
问题5:求 2¹⁰⁰⁰ mod 10007 的精确值,并说明如果模数换成 10007²,你的算法要怎么升级。
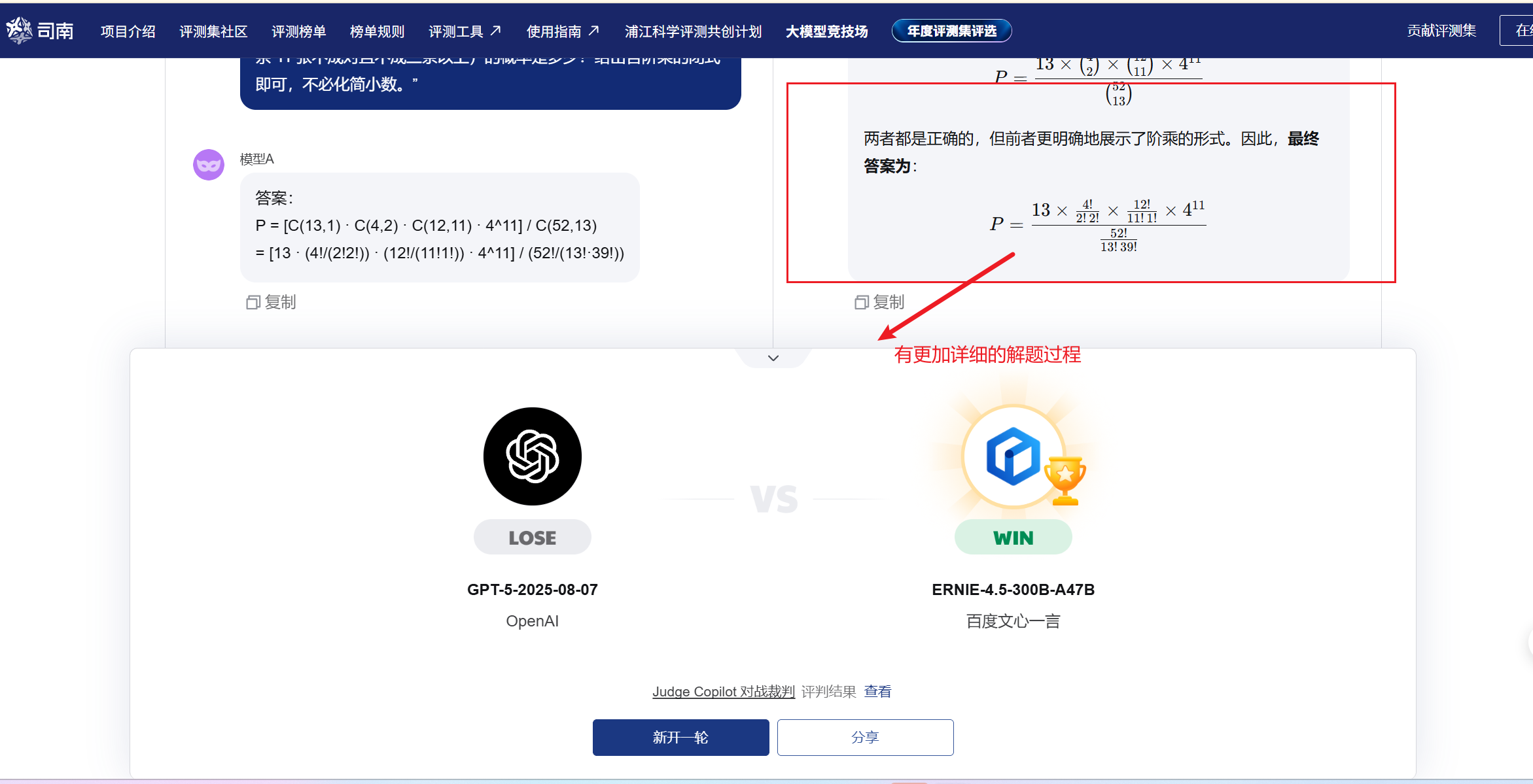
问题6:一副 52 张扑克洗匀后,前 13 张里‘恰有两条’(exactly one pair,其余 11 张不成对且不成三条以上)的概率是多少?给出含阶乘的闭式即可,不必化简小数。”
问题7:
问题8:
问题9:
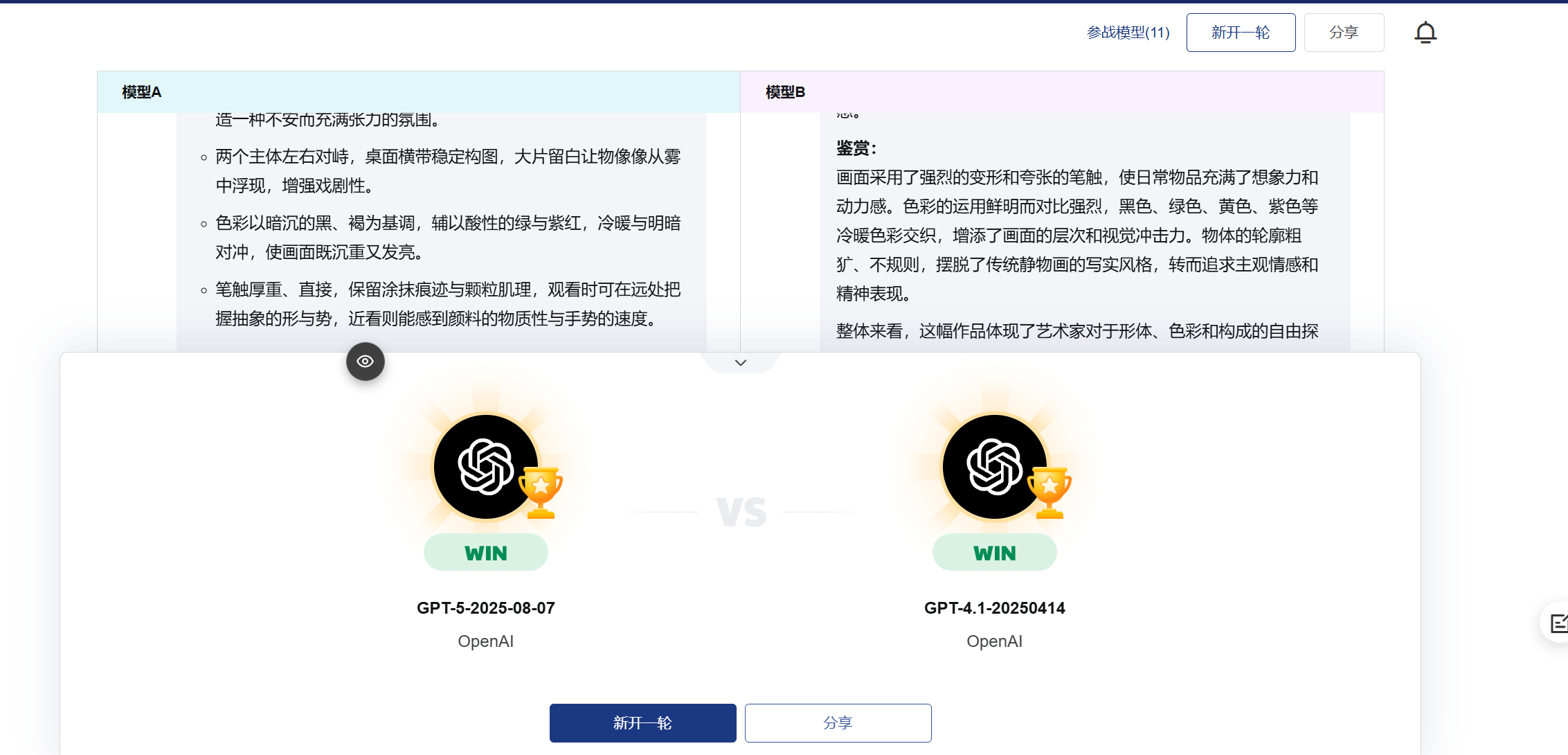
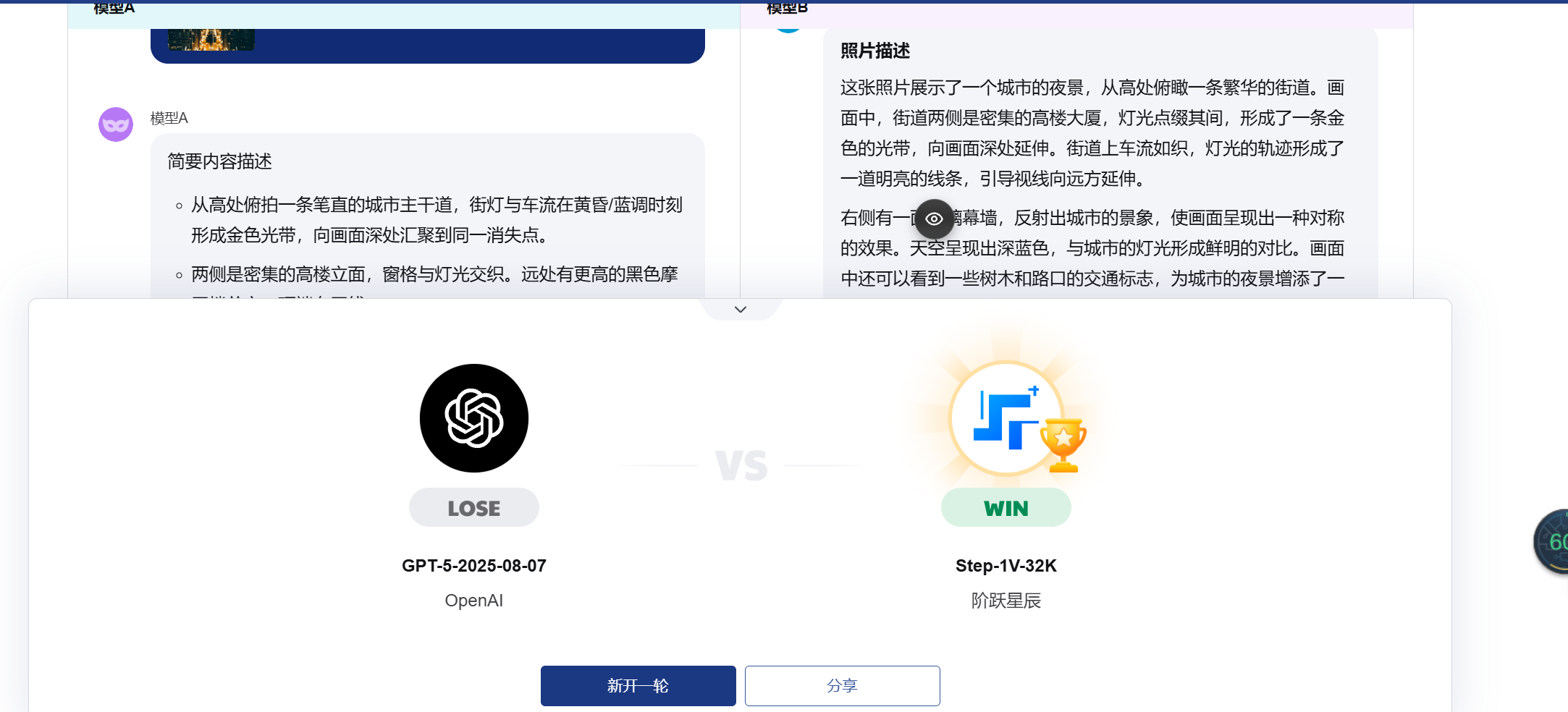
问题10:

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









