





一:大模型语言原理
大模型语言的发展不是一蹴而就的,它也需要一个类似人的成长过程。大概就是以下的五个阶段:
第一阶段:幼儿阶段:大脑逐渐发育,构建基本认知能力,理解更复杂的语言逻辑关系
- 神经网络 & 注意力
- Transformer架构
- 架构设计与初始化
第二阶段:基础教育阶段:中小学阶段是知识获取的基础阶段,广泛阅读和通识教育,学习语言、逻辑和常识等。
- 预训练
- 下一个词预测
- 大规模预科训练
第三阶段:选择性教育阶段:进入专业方向的选择期,开始发展特定领域的思维能力。同时,建立成熟的世界观和价值观。
- 指令微调&对齐
- 掌握具体任务
- 对齐人类意图和价值观
第四阶段:高等教育阶段:开始专业化学习,强调深度学习、研究能力、批判性思维。
- 领域微调
- 推理能力增强
第五阶段:职业发展阶段:熟练掌握行业经验与工具,解决实际应用问题,创造真实的社会价值。
- 多智能体协作
- 工具调用
- 检索增强生成
二:提示词工程
提示设计的六大原则:
- 指令清晰
- 提供参考内容
- 复杂的任务拆分为子任务
- 给InternLM“思考”时间(给出过程)
- 使用外部工具
- 系统性测试变化
提示词技巧:
- 描述清晰
- 扮演角色
- 提供示例
- 复杂任务分解:思维链CoT
- 使用格式符区分语义
- 情感和物质激励
- 提示词框架CRISPE框架和CO-START框架
上述的实践案例:如下方链接可进行查看:
InterLM-S1提示词实践案例![]() https://ai.feishu.cn/wiki/KOJtwLTZViwDmjkSLtocVpfPnTc?from=from_copylink
https://ai.feishu.cn/wiki/KOJtwLTZViwDmjkSLtocVpfPnTc?from=from_copylink
- 推理模型时代的提示工程
- 人格化的提示词框架LangGPT:心理学对于提示设计的启示、深度“催眠” LLM、LangGPT结构化提示词
三:工具调用与MCP探索
工具调用是指通过生成与用户定义模式相匹配的输出,使模型能够响应特定提示调用外部功能的过程。实际上模型本身并不执行操作,而是生成工具所需的参数,真正运行工具的是外部系统或服务。
MCP(Model Context Protocol)是一种为AI模型提供标准化接口的协议,用于在应用程序和AI模型之间交换上下文信息。
四:Intern-S1 技术报告阅后总结
Intern-S1是上海人工智能实验室发布的一项里程碑式的研究成果。这是一款专为科学领域设计的多模态基础模型。它在通用推理任务中展现了卓越的能力,更在化学、物理、材料科学等专业领域实现了对闭源模型的超越。这一突破标志着开源模型在科学智能领域的重大进展,推动了人工智能向通用人工智能(AGI)迈进提供了全新的路径。
为何需要Intern-S1?
科学研究对AI提出高要求:需理解低资源科学模态(如分子、时序)并完成长链严谨推理,但开源模型在科学领域远落后于闭源模型。根本障碍是“数据困境”:科学数据稀缺、模态多样、推理复杂。Intern-S1为此而生:280B激活/241B总参数的MoE,用5T token预训练(半数为科学数据),并创新混合奖励后训练,目标成为加速科学发现的通用工具,已在科学推理上反超闭源模型。
它的技术突破在哪里呢?下面一起来看看
1. 模态架构--多模态专家协作
它的核心架构由四部分组成:
- 语言模型(LLM):基于Qwen3-235B MoE模型,负责文本理解和生成。
- 视觉编码器(InternViT):采用InternViT-6B,支持高分辨率图像处理。
- 动态分词器:针对科学数据优化的分词策略,压缩率提升70%(图4)。
- 时间序列编码器:处理地震波、脑电图等连续数值数据。
下面是它的架构图:
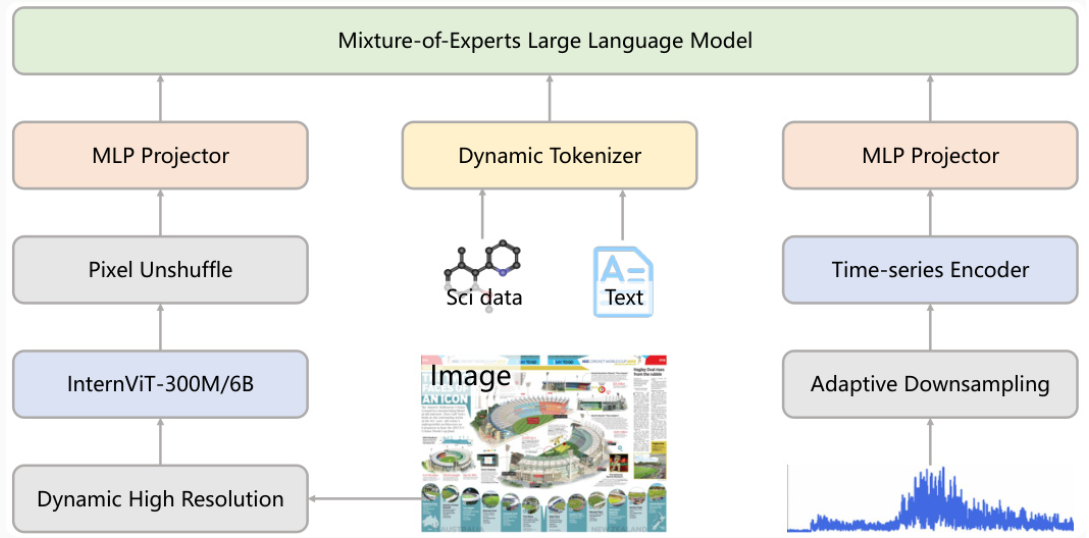
图1 Intern-S1架构图
2. 动态分词器:科学数据的高效处理
科学数据与自然语言存在显著差异。传统分词器对两者采用相同的策略,导致科学数据压缩率低。而Intern-S1的动态分词器通过了以下的方式优化:
- 模态识别:自动检测输入中的科学数据类型(如分子式、蛋白质序列)。
- 差异化分词:对科学数据采用专用分词策略,提升压缩效率。
- 正交嵌入:不同模态使用独立嵌入空间,避免语义干扰。
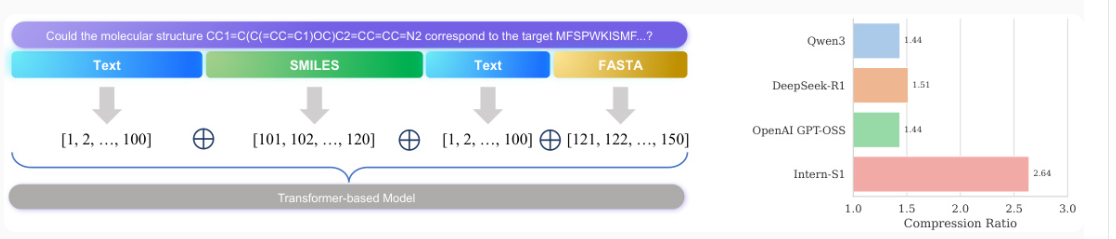
图2-动态分词器工作流程与压缩率对比
3.训练基础设施:从预训练到强化学习
它的训练分为四个阶段:
- 纯文本预训练:使用5万亿token数据,其中2.5万亿来自科学领域。
- 多模态联合训练:整合图像-文本对和科学数据,优化跨模态对齐。
- 离线强化学习:基于指令数据进行监督微调(SFT)。
- 在线强化学习:在InternBootCamp环境中进行多任务学习。

图3-Intern-S1训练过程
五:数据工程:科学领域的“数据炼金术”
-
科学数据的挑战
- 科学领域数据具有低资源、高价值的特点,传统通用模型难以有效处理。
- 数据形式多样:分子结构(SMILES格式)、蛋白序列(FASTA)、时间序列(地震波、天文数据)等非自然语言模态。
-
数据采集与清洗
- 多源数据整合:从Web数据、PDF文献、专业数据库(如PubChem、PDB)中提取科学数据。
- 动态分词器(Dynamic Tokenizer)
- 针对科学数据设计专用分词策略,提升压缩效率(如SMILES格式压缩率提升70%)。
- 不同模态使用独立嵌入空间,避免语义混淆(如字符"C"在分子式与文本中的不同含义)。
-
数据增强与标注
- 利用规则引擎和领域工具(如RDKit)自动标注分子结构数据。
- 人工校验关键数据集,确保科学准确性。
强化学习框架:Mixture-of-Rewards (MoR)
-
训练目标
- 通过离线+在线强化学习(RL)提升模型在1000+科学任务中的推理能力。
-
Mixture-of-Rewards (MoR) 算法
- 统一奖励标量:将多任务、多形式反馈(如验证模型输出、环境交互结果)转化为单一奖励信号。
- 任务分类处理:
- 易验证任务(如数学计算):使用验证模型+规则生成精确奖励。
- 难验证任务(如创意写作):采用POLAR算法评估与目标分布的距离。
- 高效训练:结合PPO、DPO等算法,减少RL训练时间(10倍加速)。
-
基础设施优化
- FP8精度训练:动态缩放的FP8矩阵乘法降低计算开销。
- 混合并行策略:FSDP(完全分片数据并行)与流水线并行结合,支持28B激活参数的MoE模型。
六:实验结果与分析
-
基准测试表现
- 通用推理任务:在MMLU-Pro、GPQA等基准上接近或超越主流开源模型(如Llama-3-70B)。
- 科学领域任务:
- 分子合成规划:超越闭源模型(如OpenAI o3)。
- 晶体热力学稳定性预测:准确率提升15%。
- 反应条件预测:F1分数达0.82,领先现有模型。
-
消融实验
- 动态分词器使科学任务性能提升12%。
- MoR框架减少RL训练样本需求至1/10。
-
局限性
- 对超长序列(>8k tokens)的处理效率仍待优化。
- 部分跨模态推理任务(如图文结合的实验设计)表现不稳定。
七、讨论与未来方向
-
模型意义
- 推动开源模型在科学领域的应用,缩小与闭源模型差距。
- 验证“通用+专业”混合架构的可行性,为AGI探索提供新路径。
-
未来工作
- 扩展模态支持(如3D分子结构、实验视频)。
- 强化因果推理能力,支持复杂实验设计。
- 开放工具链(如科学数据处理库、RL训练框架)。
关键创新点
- 动态分词器:解决科学数据低效编码问题。
- MoR框架:统一多任务强化学习的奖励机制。
- 科学数据工程体系:从Web/PDF中高效提取2.5T tokens科学数据。
模型资源
- 开源地址:HuggingFace InternLM组织页(https://huggingface.co/internlm)
- 应用场景:材料科学、药物研发、天文数据分析等科研领域。

















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









