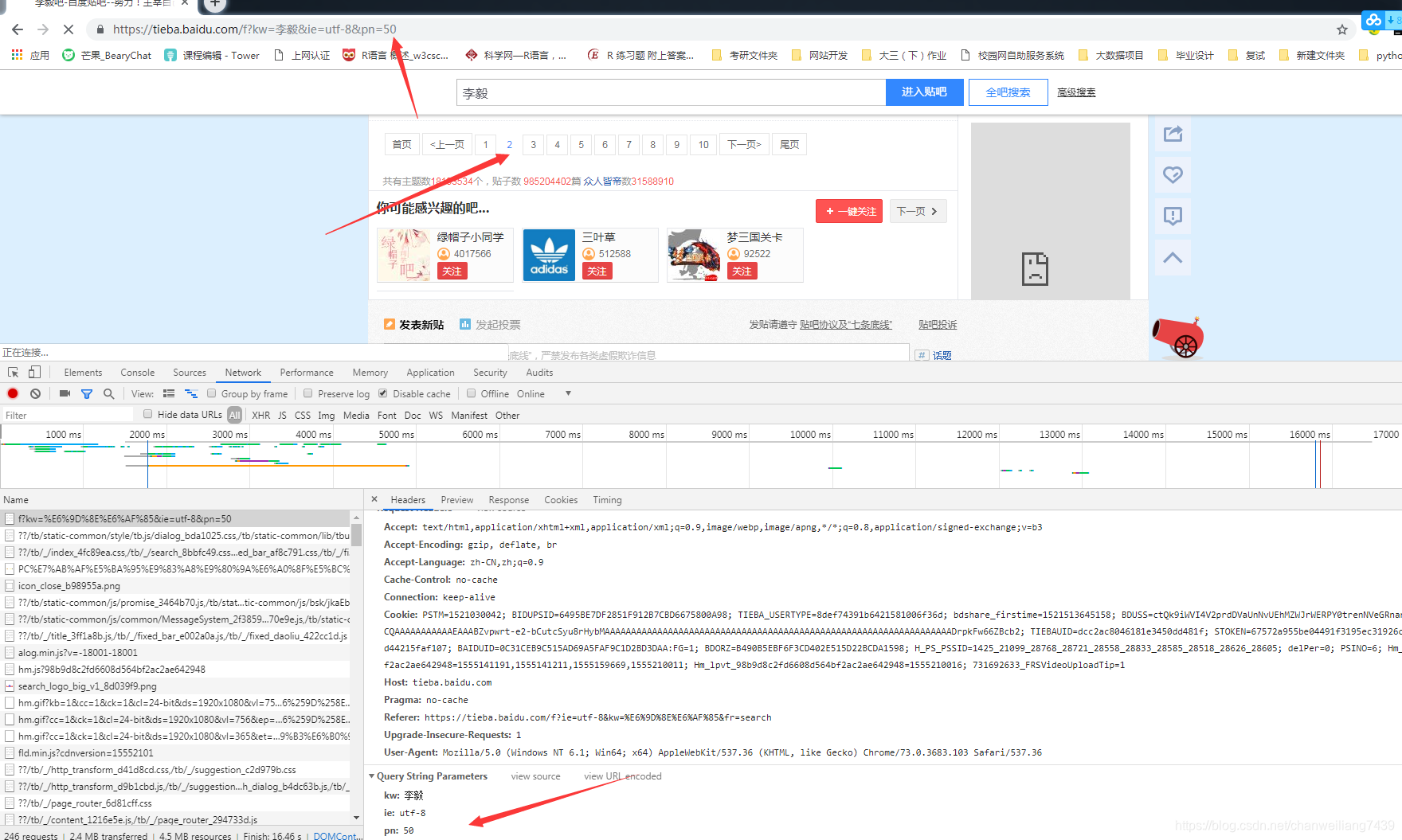
李毅贴吧,点击下一页时,对应的url地址的pn会增加50,但不确定李毅吧的总数是多少,故需要准备start_url
start_url = https://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}
使用 start_url.format 对{}进行替换,实现动态更换页码
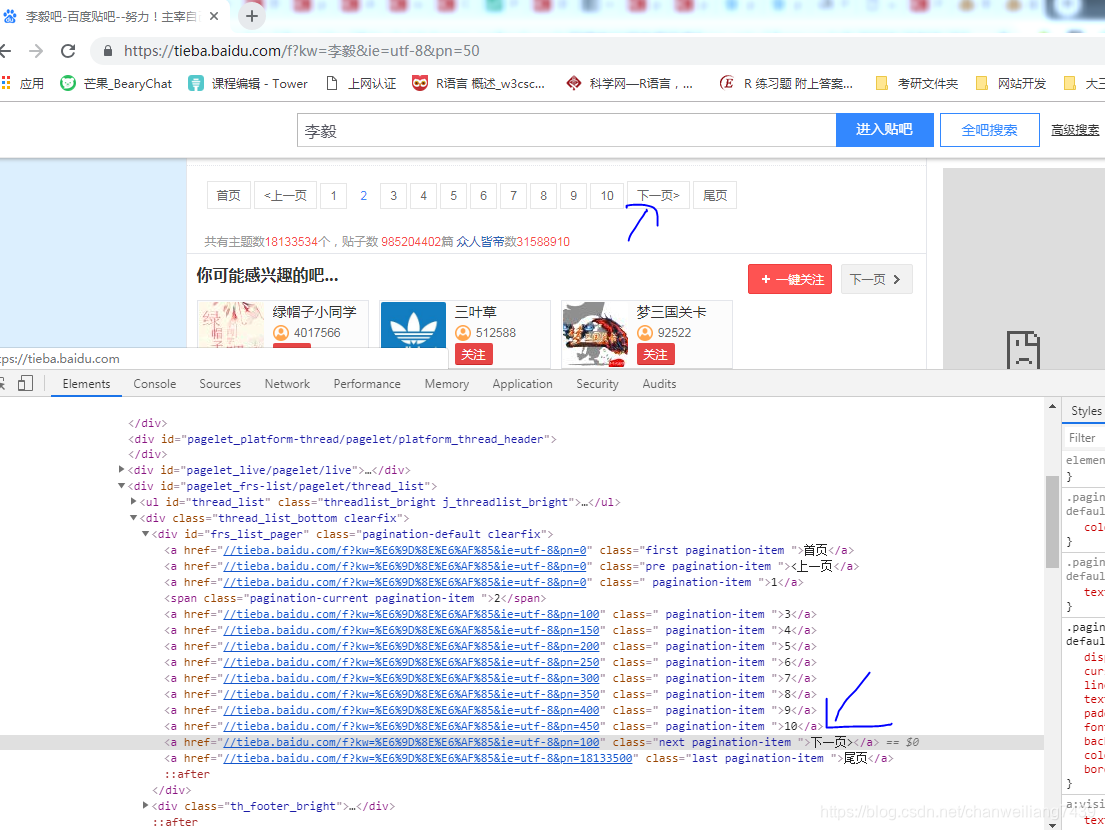
xpath("//a[text()='下一页']/@href") 直接获取到下一页的url地址
图中可以看到下一页的url地址对应的pn=100,即第三页
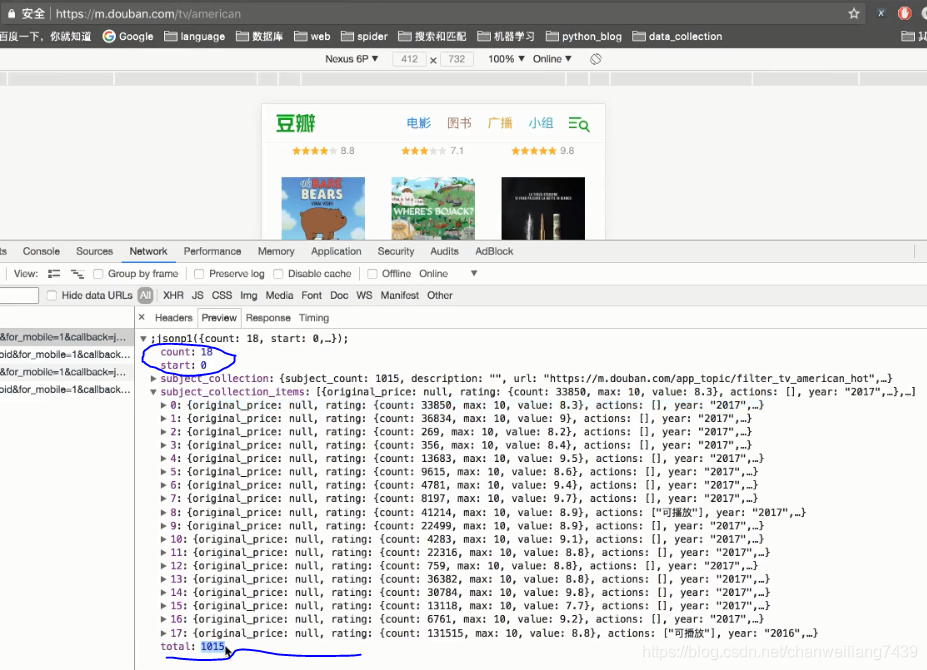
可以看到每次请求的数量为count=18 总数total=1015
故代码中 需要获取total,然后用一个num来记录一共请求的数量(num+=18)
根据 num<total 进入循环,当num>=total时,则循环结束,所有的页面都被抓取下来。
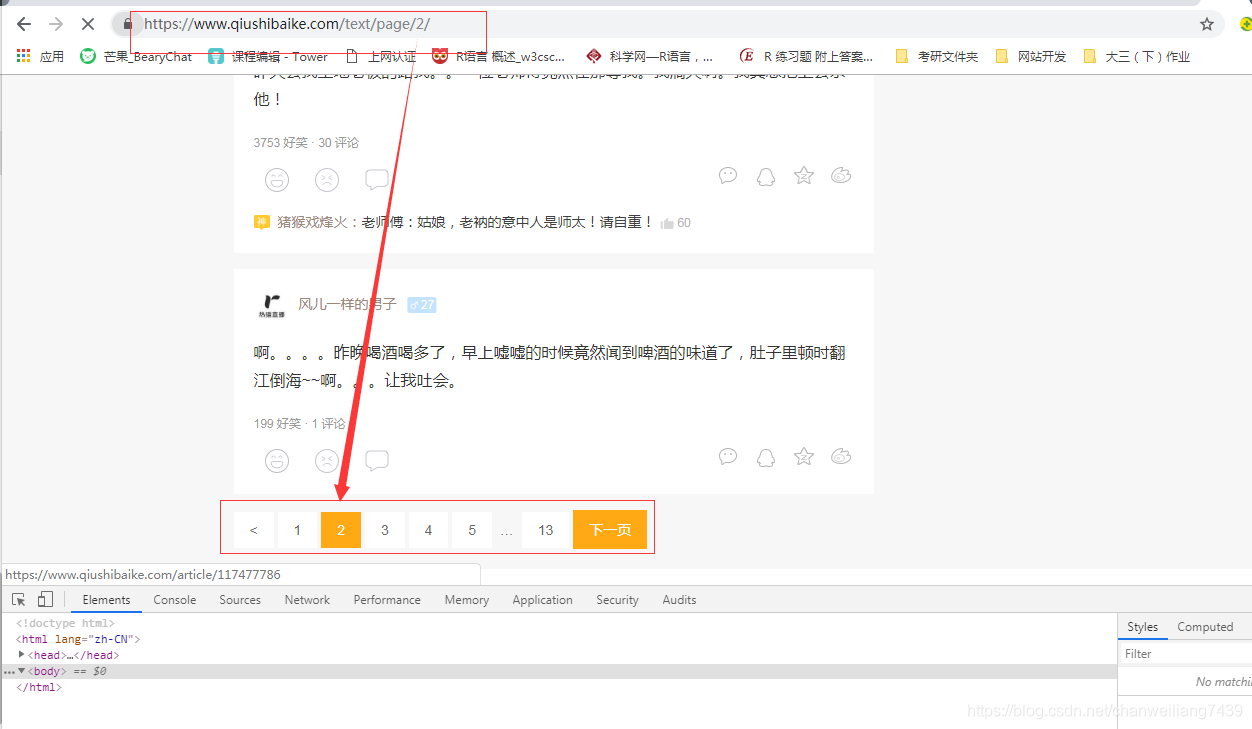
举一个栗子 糗事百科
url_temp = https://www.qiushibaike.com/text/page/{}/
url_list = url.temp.format(i) for i in range(1,14)
这样可以拿到糗事百科所有的链接组成的列表
for url in url_list 就可以拿到每一个url地址
1.requests.get(url,headers,params,proxies,auth,,cookie..)
params : 将参数放在url中传递,可以使用params
比如 kw = {'wd':'长城'} requests.get("https://www.baidu.com/s?",headers= headers,params=kw) 相当于请求https://www.baidu.com/s?wd='长城'
proxies :添加代理ip
比如:proxies={'http':"http://12.34.56.79:9527",
"https":"https://12.34.56.79:9527"}
requests.get(url,headers=headers,proxies=proxies)
auth:账户密码登录
比如:auth={"test","123465"}
requests.get(url,headers=headers,auth=auth)
cookie:添加cookie
比如:
test.txt 里面直接放有
__cur_art_index=1600; _ga=GA1.2.97777798.1555168736; _gid=GA1.2.607144467.1555168736





 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









