







一、前言说明:
strings /usr/lib64/libstdc++.so.6 | grep CXXABI
strings /lib64/libc.so.6 | grep GLIBC_2.27
查看所需的库版本是否存在


这是正常需要的,系统版本低的情况下默认的这个版本都是比较低导致服务无法启动
如果单独升级/usr/lib64/libstdc++.so.6是可以的,但是 /lib64/libc.so.6是底层基础库
都是需要升级的,这样会误升级 /lib64/libc.so.6 再删除备份libc.so.6导致系统故障,
注意:如果出现这种情况需要使用静态软连接sln 来恢复!
sln libc-2.17.so libc.so.6
所以最终我们还是需要来升级gcc和GLIBC来满足需求!
二、升级GLIBC
先升级gcc这个不用讲了,我用的gcc-9.3.0,本来想安装GLIBC-2.31但是这个需要python3.4以上,centos7默认是2.7,为了安全起见还是升级到GLIBC-2.28
1、先下载glibc包
wget https://ftp.gnu.org/gnu/glibc/glibc-2.28.tar.gz 解压完找到INSTALL文件cat下看看所需的对应环境包版本依赖
主要是gcc make bison(yum安装即可)
- 先打包下系统文件:tar -czvf /home/soft/glibc_backup.tar.gz /lib64/libc.so* /usr/include/*以防万一
- 升级make
wget https://mirrors.aliyun.com/gnu/make/make-4.3.tar.gz
tar zxvf make-4.3.tar.gz
cd make-4.3
mkdir build && cd build
../configure --prefix=/usr/local/make4.3
make && make install
whereis make
cd /usr/bin/
mv make make.bak
ln -s /usr/local/make4.3/bin/make /usr/bin/make
然后看下版本可以了 make -v
- 升级glibc,已下载
tar zxvf glibc-2.28.tar.gz
cd glibc-2.28
mkdir build && cd build
../configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin --disable-sanity-checks --disable-werror
注意:--prefix=/usr 指定其他目录的话会导致make install报错:
/home/soft/glibc-2.28/build/elf/ldconfig: Warning: ignoring configuration file that cannot be opened: /usr/local/glibc-2.28/etc/ld.so.conf: No such file or directory 再调整麻烦
make -j4
make install
查看下是否成功ldd --version
至此完成!
三、出现的问题处理:
不过发现升级完出现yum无法使用的情况

主要可能有两个原因:一是没有安装对应的语言包,二是环境变量配置不正确。
到glibc的build下执行:make localedata/install-locales
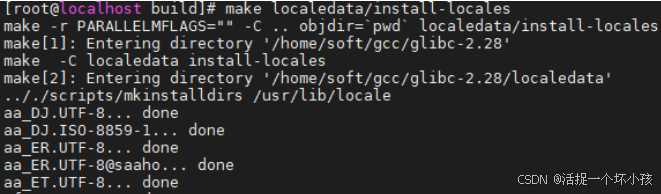
然后发现虽然不报错了但是yum卡住如下:
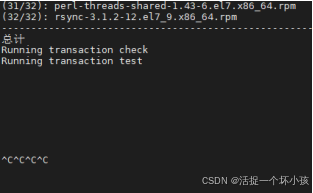
发现/usr/lib/cc没了还有就是/usr/lib64/libstdc++.so.6也被还原了
直接删掉/usr/lib/cc 会默认链接到gcc,/usr/lib64/libstdc++.so.6软链接再设置下然后重启下机器就可以了
注:centos7的gcc升级到10版本及glibc升级到2.28以上,因版本问题会导致yum无法使用很难恢复,谨慎升级!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









