




目录
3. data augmentation by backtranslation
1. 简要介绍
模型创新点:
(一)移除了RNN,核心就是卷积 + self-attention。这样使得训练更快,相应地模型能使用更多的训练数据。Convolution capture the local structure of context(local interactions), self-attention models global interactions。两者相辅相成,不可替代。
(二)使用了辅助的数据增强技术来提高训练数据,数据来自MT模型的back-translation。
QANet首先达到又快又精确,并且首先把self-attention和convolution结合起来。
QANet结构广泛使用convolutions和self-attentions作为encoders的building blocks,然后分别encode query和context,然后使用standard attentions学习到context和question之间的interactions,结果的representation再次被encode,然后最后decode出起始位置的probability。
组件分析:
- convolution: local structure
- self-attention:global interaction
- additional context-query attention:
它是standard module,从而建立query-aware context vector
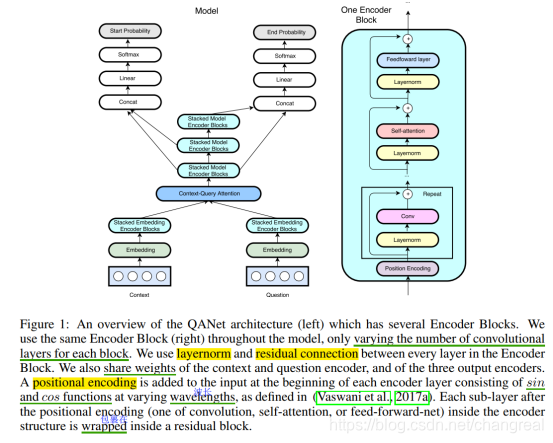
QANet结构
主要包括5个组件:input embedding layer,a embedding encoder layer, context-query attention layer, a model encoder layer, an output layer.
与其他MRC模型不同的是:所有embedding和model encoders只使用conv和sefl-attention;
创新的辅助的data augmentation技术:从原始英文翻译为法语后,再翻译回英语,这样不仅提高了训练实例的数量,更提高了措辞多样化。英语翻译为法语后,通过beam decoder,生成k句法语翻译,然后法语翻译再通过beam decoder变回英语就获得了k^2句paraphrases。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









