




 文章介绍了B树和B+树在MySQL数据库查询优化中的作用,强调了B+树在减少IO次数、提高查询效率和空间利用率上的优势,以及注意事项,如索引类型限制和实际数据库实现可能的差异。
文章介绍了B树和B+树在MySQL数据库查询优化中的作用,强调了B+树在减少IO次数、提高查询效率和空间利用率上的优势,以及注意事项,如索引类型限制和实际数据库实现可能的差异。
目录
1.为什么要引用B树和B+树这种数据结构?
在操作mysql数据库中,查询是不可或缺的一项.而查询往往看的不仅仅是查询数据的准确性还有查旭的速度.因为在日常工作中我们处理的数据往往很庞大的,所以我们需要实现一种辅助工具来帮助我们加快查询的速度,这时索引就被引用到mysql数据库查询的操作中来了.
2.什么是B树?
而索引之所以能够来帮助我们提升查询的速度,主要依赖于它的数据结构->B+树,那在提到B+树之前就得说一下我们的B树了.
B树的本质上就是一个N叉搜索树
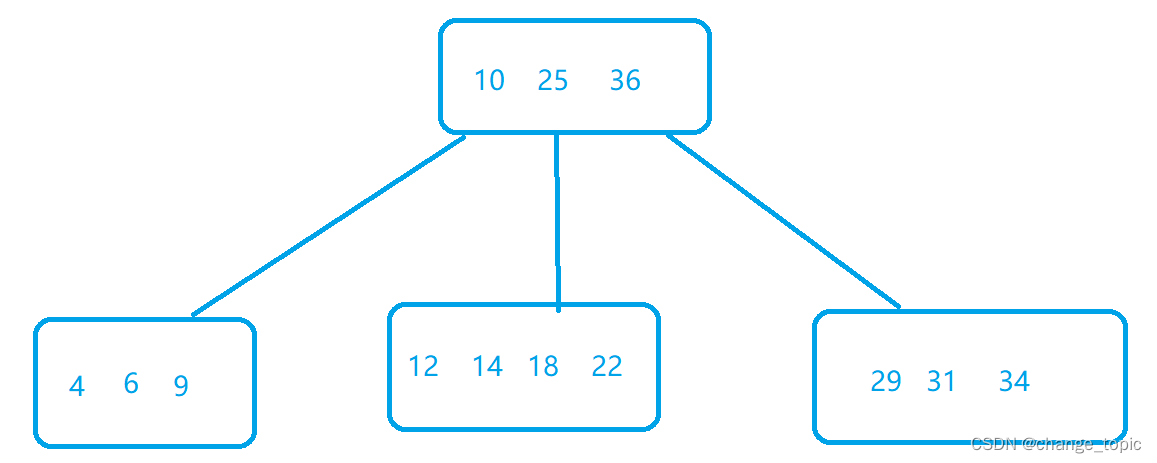
与二叉树搜索树不同的是一个节点上可以保存很多的值(数据),根据这些值可以分叉出很多子节点,子节点的值都比节点的值要小,这个时候查询的速度就比其他数据结构快很多.(这里说明一下为什么不用哈希表,虽然说哈希表查询的速度很快但是它不能进行范围的查询,就比如说我想要查询100-200之间的数据,这个时候哈希表就做不到这样的查询了)但是随着数据越来越多,树的高度变得很高,这个时候我们进行IO操作(访问硬盘)的次数就变多了,那么整体的效率就变慢了.这个时候我们就在原有的B树基础上稍加改进,就出现了B+树.
3.什么是B+树?
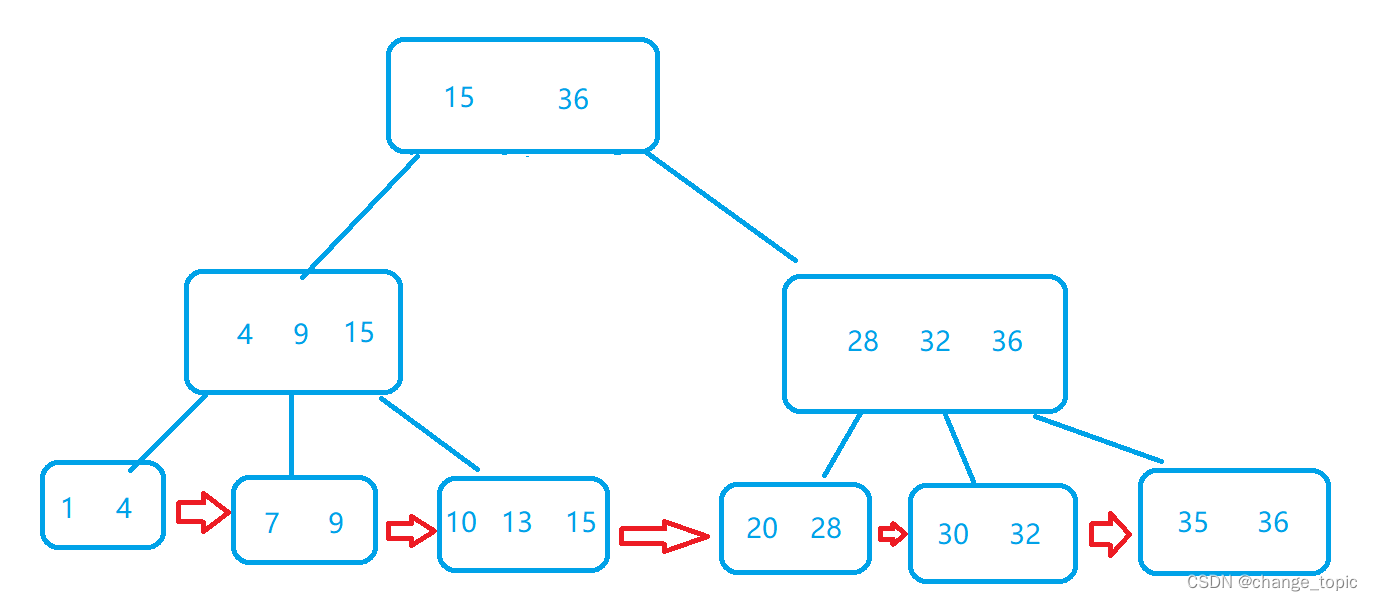
B+树在B树上面的改进是
1.在节点中的N个key(值)会被分为N的区间
2.节点中的key会在子节点中出现,并且是在子节点中最大的key
3.B+树的叶子节点(最下面一排节点),是首尾相连的,类型于链表形式
4.由于以上特点,我们所有的key最终都会在叶子结点中出现,所以我们非叶子节点只存储值,不存储值所对应的数据,值所对应的数据存储在最后的叶子节点当中.
所以通过以上描述我们可以很明确的知道B+的优势:
1.此时节点中不止存储一个key,这就导致了树的高度大大降低,IO的访问次数变少,效率会更高.
2.因为节点会在子节点中出现,所以我们的B+树的平衡性高,查到数据时IO次数相同.(在程序猿操作计算机时肯定是希望自己的操作是稳定的,这样能够对程序的执行效率能够进行一定的评估)
3.因为只有叶子节点才会存储数据,非叶子节点只存储了key,占用的空间变小了,此外还减少了IO的次数.
4.因为最后叶子节点会构成一个链表,可以更方便的进行查询
(看到这里的兄弟有福了,这里是额外补充知识点)
一个表建立索引没说只能建立一个索引,所以可能会碰到多个索引的情况,这里举个栗子
比如说一个表按照id作为主键建立了索引然后又用了name作为索引.这时候跟上述介绍B+树一样,mysql数据库会根据id建立一个B+树,同时它也会为name建立一个B+树.但是name建立的B+树中叶子节点存储的不是完整的数据了,而是主键id.当利用name作为索引去查询的时候,最后会查询到一个主键id,然后再去根据主键id建立的B+中查询完整的数据.
上述过程称为"回表",mysql自主完成,用户感知不到.
4.注意事项
注意!注意!注意!
上述的树形结构不代表数据库就是按照这样实现的,它还可能是一张表.但具体是树还是表要看数据库中的存储引擎和其他因素.
建立索引的前提是能够进行类型的比较,mysql数据库的类型是不能自定义的,所以是只能按照给定能够进行比较的类型来建立.
(以上内容纯属自我学习所得,至于真假请翻阅其他网路资料进行甄别.
知识有风险,学习需谨慎!!!)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









