




 本文提出了一种基于动作驱动的3D室内场景演化框架,利用标注照片学习动作模型,包括物体摆放、空间配置及人与物的关系,实现场景的动态变化和物体的重新定位。此方法能生成更真实、复杂的场景,与手动创建或数据驱动的方法相比,具有更高的自然性和真实性。
本文提出了一种基于动作驱动的3D室内场景演化框架,利用标注照片学习动作模型,包括物体摆放、空间配置及人与物的关系,实现场景的动态变化和物体的重新定位。此方法能生成更真实、复杂的场景,与手动创建或数据驱动的方法相比,具有更高的自然性和真实性。
论文主页
标题:Action-Driven 3D Indoor Scene Evolution
作者:Rui Ma, Honghua Li, Changqing Zou, Zicheng Liao, Xin Tong, Hao Zhang
来源:SIGGRAPH Asia 2016
翻译:change_things
摘要
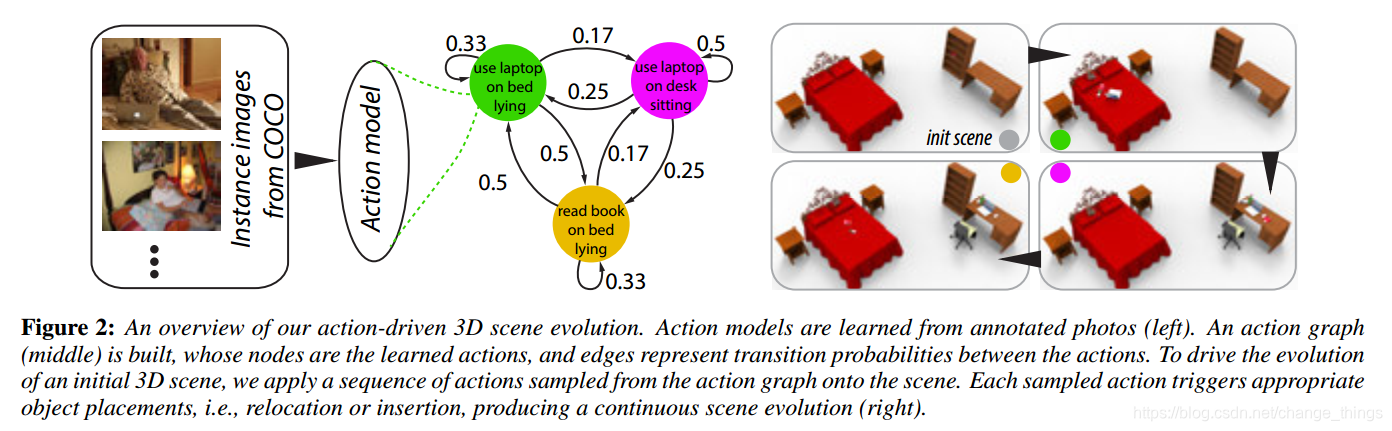
这篇文章目的是介绍一个3D室内场景的动作驱动的演化框架,目标是模拟场景如何被人类的行为改变的过程,特指实现某个动作必要的物体摆放位置。最后,本文开发了一个动作模型,每类动作结合一个或多个人类姿势,一类或多类物体以及物体的空间配置,这些物体属于为某个动作的物-物和物-人关系总结出的物体种类(这一段很长很绕口)。重要的是,所有的信息都是从标注的图片中学到的。通过分析学到的动作之间的关系,可以指导动作图的构建。从初始的三维场景开始,本文根据概率从动作图中采样出一个动作序列用于驱使渐进式的场景演化。每个动作会触发适当的物体放置,这种放置是基于从动作模型中学到的物体共现和空间配置。本文展示了通过这种演化得到的真实且混乱的场景,以及通过用户进行的定量评估,就场景的真实性和自然性而言,与手动制造场景以及数据驱动的方法进行了比较。
主要贡献
1)一种逐步生成场景的方法,一个演变和颗粒的3D场景,和之前的工作相比,在不牺牲可信性和自然性的前提下,本文展示了一个更高复杂性和混乱程度的场景 。
2)从带注释的照片而不是像以前工作一样从3D场景的范例中学习动作。这使我们能够把更丰富的数据源用于动作驱动的场景处理。
3)一个更完整的动作模型,该模型考虑了一组动作,以及多个物体的同时发生和联合放置,允许物体重新定位和插入。
概览
本文首先介绍动作模型和动作图的概念,展示了两阶段学习的概况和场景合成框架,如图所示:

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









