




 本文详细介绍了Spring框架中,如何从XML配置文件解析到BeanDefinition的过程。从registerBeanDefinitions方法开始,逐步解析Document,创建BeanDefinitionDocumentReader和XmlReaderContext。接着,通过BeanDefinitionParserDelegate解析Document,处理bean定义,包括id、name、属性、依赖等信息,并最终将BeanDefinition注册到DefaultListableBeanFactory容器中。
本文详细介绍了Spring框架中,如何从XML配置文件解析到BeanDefinition的过程。从registerBeanDefinitions方法开始,逐步解析Document,创建BeanDefinitionDocumentReader和XmlReaderContext。接着,通过BeanDefinitionParserDelegate解析Document,处理bean定义,包括id、name、属性、依赖等信息,并最终将BeanDefinition注册到DefaultListableBeanFactory容器中。
在上篇Spring源码分析之IOC (一)中,我们分析到了将配置文件spring-application.xml解析转换为Document对象,并开始解析Document这里。
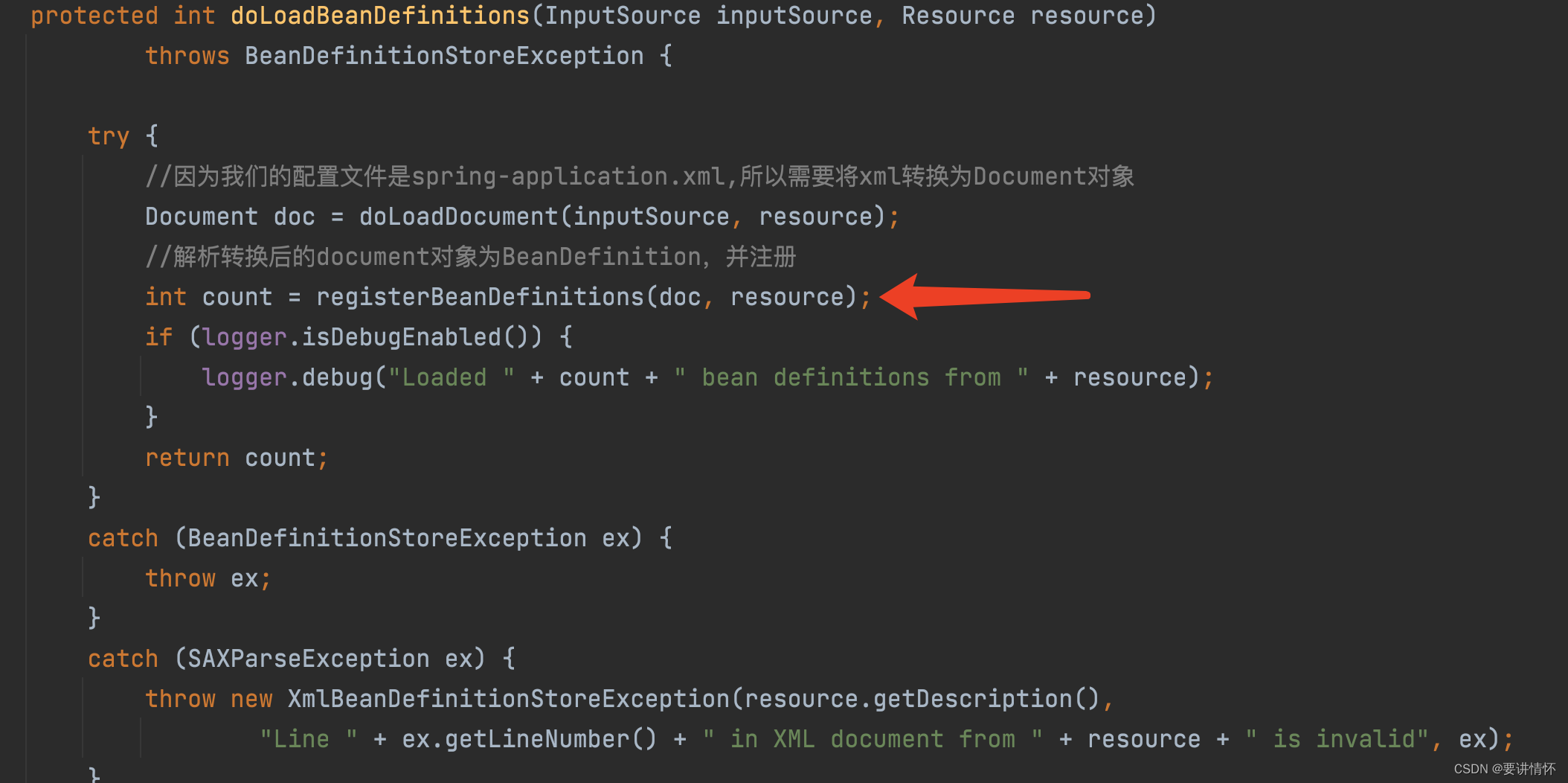
我们进入org.springframework.beans.factory.xml.XmlBeanDefinitionReader#registerBeanDefinitions方法。
先是创建BeanDefinitionDocumentReader类,然后通过该类去解析已经从Xml转换成Document对象的配置文件。
其中createReaderContext(resource)方法返回XmlReaderContext对象,XmlReaderContext主要是将Documet解析器传递给BeanDefinitionDocumentReader,因为真正解析Document类的是由BeanDefinitionDocumentReader类的成员变量BeanDefinitionParserDelegate类来解析的,而BeanDefinitionParserDelegate类是通过XmlReaderContext来创建的。
XmlReaderContext包含了解析各种命名空间的解析类,如果在解析中解析到spring意外的命名空间,比如dubbo这种<dubbo:service>标签,都可以通过XmlReaderContext来找到对应的解析类去解析:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//创建Document解析类
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
//开始解析注册bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}继续进入registerBeanDefinitions查看,看到了do开头的方法,那么核心的逻辑就在这里面了:

继续进入doRegisterBeanDefinitions方法,主要的逻辑在parseBeanDefinitions中,其他的代码可以看下注释:
protected void doRegisterBeanDefinitions(Element root) {
//因为有嵌套bean标签<beans>,该方法会被递归回调,所以将当前解析delegate付给parent对象,在新建一个delegate去解析
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
/**
* 主要校验<beans>标签的profile属性,profile主要用于环境隔离,可以有多个环境,多套配置
* 通过ClassPathXmlApplicationContext.getEnvironment().setActiveProfiles("test")
* 决定使用那一套配置,如果没有设置则不解析
* <beans profile="test">
* <bean id="dataSource" ...></bean>
*</beans>
*/
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// We cannot use Profiles.of(...) since profile expressions are not supported
// in XML config. See SPR-12458 for details.
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
//空实现,模版方法模式,留给子类扩展
preProcessXml(root);
//解析
parseBeanDefinitions(root, this.delegate);
//空实现,模版方法模式,留给子类扩展
postProcessXml(root);
//解析完成重新将原来的delegate赋值回来去解析
this.delegate = parent;
}我们继续进入parseBeanDefinitions方法中,首先会去判断是否是spring自己定义的标签,是的话就用默认解析器去解析,如果不是就去找对应的标签解析器去解析,这个我们后面再说,先分析默认标签:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//判断是否是默认的命名空间标签,比如<beans>,<bean>等spring自带的标签,
// 如果不是就进入else标签中,比如dubbo的<dubbo:service>,由dubbo自己去解析
if (delegate.isDefaultNamespace(root)) {
//获取所有子结点,去遍历解析
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
//如果是spring标签,就直接处理
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
//如果不是spring的标签,则找对应的标签解析器去解析
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
//如果不是spring默认标签,则找对应的标签解析器去解析
delegate.parseCustomElement(root);
}
}进入解析默认标签的parseDefaultElement方法中,spring分别对import、alias、bean、beans标签一一区别处理,这里我们重点关注bean标签的解析:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
//如果是import标签,如<import>...</import>;会继续调用loadBeanDefinitions方法,
// 也就是最终还是调用doRegisterBeanDefinitions方法
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
//如果是alias标签的话,如<alias name="person" alias="person2"/>,
//会解析出name和alias最终以alias为key,name为value注册到容器的aliasMap中
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
//如果是bean标签的话,如<bean>...</bean>就去解析bean
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
//如果是嵌套bean标签,如<beans>...</beans>则直接递归doRegisterBeanDefinitions继续解析
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}进入解析bean标签的代码processBeanDefinition,可以看到整个解析过程放到了delegate.parseBeanDefinitionElement(ele)方法中,解析完成后会对解析到的对象进行二次处理:
//处理bean节点,解析beanDefinition并注册
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//解析,并返回BeanDefinitionHolder,BeanDefinitionHolder是BeanDefinition的封装类,持有BeanDefinition。
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
//对bean标签进行进一步的处理,主要用于bean标签中使用了自定义标签的场景
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 注册最终生成的bdHolder
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 发送当前bdHolder注册完成事件
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}继续进入delegate.parseBeanDefinitionElement(ele)方法中:

是一个重载方法,那我们进入parseBeanDefinitionElement(ele, null)进行继续深入分析,可以看到外层就是解析id和name属性和生成唯一的beanName,并最终返回beanDefinition的包装对象BeanDefinitionHolder,真正解析还是留给了重载方法:parseBeanDefinitionElement(ele, beanName, containingBean):
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
//解析id,name属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//name属性可以有多个,通过分隔符(,; )截取为数组,分隔符为逗号,冒号,空格
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
//默认id作为beanName,如果没有id,就取aliases数组中的第一个作为beanName
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isTraceEnabled()) {
logger.trace("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
//校验beanName是不是唯一,如果不是就打印一行日志,没有其他的处理,后面会再生成全局唯一的beanName
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
//真正解析的方法
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
//生成全局唯一的beanName
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isTraceEnabled()) {
logger.trace("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
//返回beanDefinition的包装对象BeanDefinitionHolder
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}继续进入parseBeanDefinitionElement的重载方法,可以看到里面全是解析各种标签的方法,具体就是先创建一个AbstractBeanDefinition对象,然后将解析道的bean信息全部设置到AbstractBeanDefinition对象的属性中:
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
//底层是ArrayDeque,主要用来打印日志
this.parseState.push(new BeanEntry(beanName));
String className = null;
//拿到class属性值:<bean id="person" class="whf.easy.boot.service.Person"/>
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
String parent = null;
//拿到parent属性值
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
//创建AbstractBeanDefinition对象,主要设置了parentName,beanClass或者beanClassName属性
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//解析attribute属性,如scope,lazy-init,autowire,init-method等等
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
//解析description属性
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
/**
* 解析元数据<meta>标签
* <bean id="person" class="whf.easy.boot.service.Person" >
* <meta key="id" value="1"/>
* <property name="name" value="二郎神"/>
* <property name="age" value="1000000"/>
* </bean>
*/
parseMetaElements(ele, bd);
//解析lookup-method
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//解析replaced-method
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析constructor-arg
parseConstructorArgElements(ele, bd);
//解析property
parsePropertyElements(ele, bd);
//解析qualifier
parseQualifierElements(ele, bd);
//设置配置文件信息
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}我们先可以看下bean标签上属性的解析,在parseBeanDefinitionAttributes方法中:
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
@Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {
//老版本有singleton属性可以忽略
if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
}
//解析scope属性:<bean id="person" class="whf.easy.boot.service.Person" scope="singleton" />
else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
}
else if (containingBean != null) {
// Take default from containing bean in case of an inner bean definition.
bd.setScope(containingBean.getScope());
}
//解析是否是抽象类属性:<bean id="person" class="whf.easy.boot.service.Person" abstract="false" />
if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
}
//解析是否是懒加载属性:<bean id="person" class="whf.easy.boot.service.Person" lazy-init="false" />
String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
if (isDefaultValue(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit(TRUE_VALUE.equals(lazyInit));
//解析autowire属性:<bean id="person" class="whf.easy.boot.service.Person" autowire="byName" />
String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
bd.setAutowireMode(getAutowireMode(autowire));
//解析depends-on属性
if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
}
//解析autowire-candidate属性
String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
if (isDefaultValue(autowireCandidate)) {
String candidatePattern = this.defaults.getAutowireCandidates();
if (candidatePattern != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
}
else {
bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
}
//解析primary属性
if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
}
//解析init-method属性
if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {
String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);
bd.setInitMethodName(initMethodName);
}
else if (this.defaults.getInitMethod() != null) {
bd.setInitMethodName(this.defaults.getInitMethod());
bd.setEnforceInitMethod(false);
}
//解析destroy-method属性
if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {
String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);
bd.setDestroyMethodName(destroyMethodName);
}
else if (this.defaults.getDestroyMethod() != null) {
bd.setDestroyMethodName(this.defaults.getDestroyMethod());
bd.setEnforceDestroyMethod(false);
}
//解析factory-method属性
if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {
bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));
}
//解析factory-bean属性
if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {
bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));
}
return bd;
}解析都比较简单,我们再看一个对类里面所持有属性的解析处理parsePropertyElements,其他的有兴趣可以仔细的研究,进入parsePropertyElements(ele, bd)方法中,可以看到首先是获取所有的子标签,如果是property标签,就进入parsePropertyElement方法解析:
public void parsePropertyElements(Element beanEle, BeanDefinition bd) {
NodeList nl = beanEle.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
//是默认标签,并且是property标签
if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {
//解析property标签
parsePropertyElement((Element) node, bd);
}
}
}跟踪parsePropertyElement方法,先获取name,可以跟踪打印日志,接着就是调用parsePropertyValue方法解析value、ref等标签,并设置到BeanDefinition中:
/**
* Parse a property element.
* <bean id="dog" name="dog2" class="whf.easy.boot.service.Dog">
* <property name="age" value="1"/>
* <property name="name" value="啸天犬"/>
* <property name="master" ref="person"/>
* <property name="numbers" >
* <list>
* <value>1</value>
* <value>2</value>
* </list>
* </property>
* </bean>
*/
public void parsePropertyElement(Element ele, BeanDefinition bd) {
//先获取name属性
String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
if (!StringUtils.hasLength(propertyName)) {
error("Tag 'property' must have a 'name' attribute", ele);
return;
}
//打印日志使用
this.parseState.push(new PropertyEntry(propertyName));
try {
if (bd.getPropertyValues().contains(propertyName)) {
error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
return;
}
//解析对应的属性,value、ref等等
Object val = parsePropertyValue(ele, bd, propertyName);
PropertyValue pv = new PropertyValue(propertyName, val);
//解析property子为mete的子元素
parseMetaElements(ele, pv);
pv.setSource(extractSource(ele));
bd.getPropertyValues().addPropertyValue(pv);
}
finally {
this.parseState.pop();
}
}进入parsePropertyValue方法中,方法也很简单明了,就是获取对应的属性值并返回:
public Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {
String elementName = (propertyName != null ?
"<property> element for property '" + propertyName + "'" :
"<constructor-arg> element");
//先获取下property的子元素,子元素跟ref和value都是只能有一个,如果存在子元素就进行校验
//只能有一个子元素,因为一个属性只能是一种类型,比如不能既是list还是map.
NodeList nl = ele.getChildNodes();
Element subElement = null;
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
!nodeNameEquals(node, META_ELEMENT)) {
// 如果已经解析了一个的话就抛出异常
if (subElement != null) {
error(elementName + " must not contain more than one sub-element", ele);
}
else {
subElement = (Element) node;
}
}
}
//再获取ref和value,该属性不能同时出现,所以先判断校验,后解析
boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
if ((hasRefAttribute && hasValueAttribute) ||
((hasRefAttribute || hasValueAttribute) && subElement != null)) {
error(elementName +
" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
}
//如果是ref就封装到RuntimeBeanReference中
if (hasRefAttribute) {
String refName = ele.getAttribute(REF_ATTRIBUTE);
if (!StringUtils.hasText(refName)) {
error(elementName + " contains empty 'ref' attribute", ele);
}
RuntimeBeanReference ref = new RuntimeBeanReference(refName);
ref.setSource(extractSource(ele));
return ref;
}
//如果是value就封装到TypedStringValue中
else if (hasValueAttribute) {
TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
valueHolder.setSource(extractSource(ele));
return valueHolder;
}
//如果既没有ref,也没有value,但是子元素不为null,就解析子元素
else if (subElement != null) {
return parsePropertySubElement(subElement, bd);
}
else {
// Neither child element nor "ref" or "value" attribute found.
error(elementName + " must specify a ref or value", ele);
return null;
}
}bean标签解析完后,我们在回到最初调用parseBeanDefinitionElement的地方
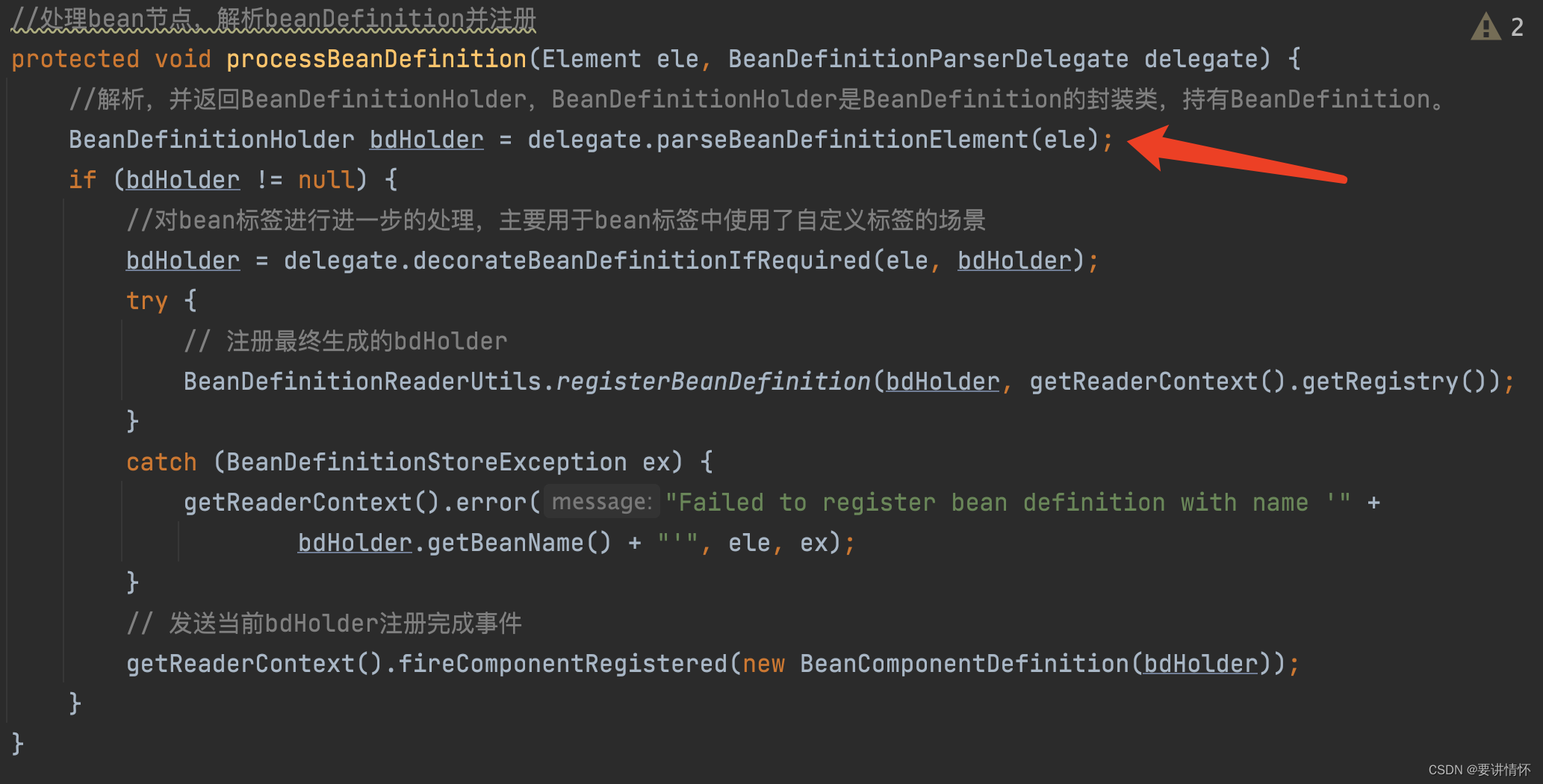
接着就是对解析返回的BeanDefitionHolder对象进行第二次处理,主要是对bean标签中有自定义标签的解析,一般项目中很少用到,可以忽略,想要二次开发的话可以进行深入了解。最终执行BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
将通过xml配置文件解析到的bean信息统一注册到registry中,registry是最初创建的DefaultListableBeanFactory容器
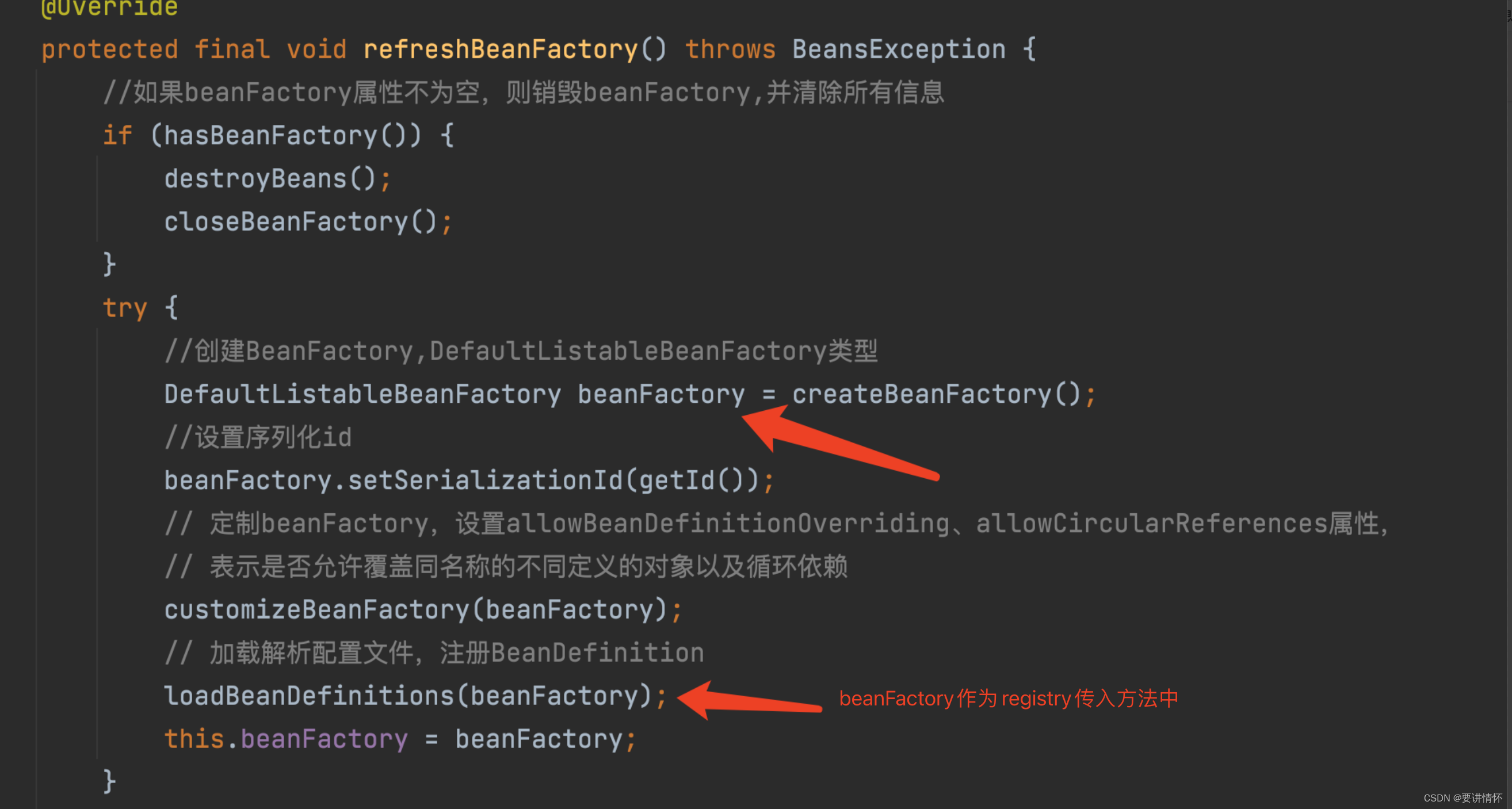
好了,进入registerBeanDefinition一探究竟,先获取beanName,然后调用registry的注册beanDefinition方法,存在aliases的话也注册进去,建立beanName-alias之间的关系:
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
//根据beanName注册beanDefinition
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 如果存在aliases,将aliases也根据beanName进行注册,后面也可以根据alias找到bean。
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}我们主要看registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition())方法,可以直接根据注释看这一部分的逻辑,所谓的注册就是把以key-value的形式(beanName-beanDefinition)将解析的beanDefinition对象放进beanDefinitionMap中,后面在创建bean的时候需要什么bean信息都可以直接从beanDefinitionMap中获取到:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
//beanDefinition校验
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
//先从注册容器beanDefinitionMap中根据beanName进行获取
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
//如果不为空,判断是否允许被覆盖,通过字段属性allowBeanDefinitionOverriding控制
//spring中默认为true,springboot默认为false
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
//打印日志
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (logger.isInfoEnabled()) {
logger.info("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]");
}
}
//打印日志
else if (!beanDefinition.equals(existingDefinition)) {
if (logger.isDebugEnabled()) {
logger.debug("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
//覆盖
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
//如果已经有bean开始创建了,就不能直接对集合进行增删改查的操作,会触发fail-fast机制,解决方法就是copyOnWrite
//感兴趣的话可以参考下线程安全的集合为了避免并发修改问题是如何操作的
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
//删除手工注册的单例名称
removeManualSingletonName(beanName);
}
}
else {
//还在启动注册阶段,直接放入beanDefinitionMap中
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
//如果existingDefinition不为空,且容器中存在新的beanDefinition,说明已经覆盖了老的existingDefinition
//这时需要重新设置下缓存,底层主要是清除mergedBeanDefinitions对应的缓存,已创建bean对应的缓存,都是Map结构
//在下次流程中重新创建并缓存起来
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
//如果已冻结,就清除所有的allBeanNamesByType,singletonBeanNamesByType
//这两个是什么作用,我们后期再说
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}好了,beanDefiniton解析及注册就到这里结束了,下期我们讲一下spring解析自定义命名空间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









