




 本文详细介绍了ZooKeeper的底层数据结构,包括数据、ACL、元数据和子节点引用。还讨论了其通知机制(Watch),服务注册与发现功能,以及如何实现分布式锁。此外,阐述了ZooKeeper集群搭建的好处,如读写分离、容错和扩展性,并描述了Zookeeper的选举原理。
本文详细介绍了ZooKeeper的底层数据结构,包括数据、ACL、元数据和子节点引用。还讨论了其通知机制(Watch),服务注册与发现功能,以及如何实现分布式锁。此外,阐述了ZooKeeper集群搭建的好处,如读写分离、容错和扩展性,并描述了Zookeeper的选举原理。
一,底层数据结构
ZooKeeper维护类似一个文件系统的数据结构:
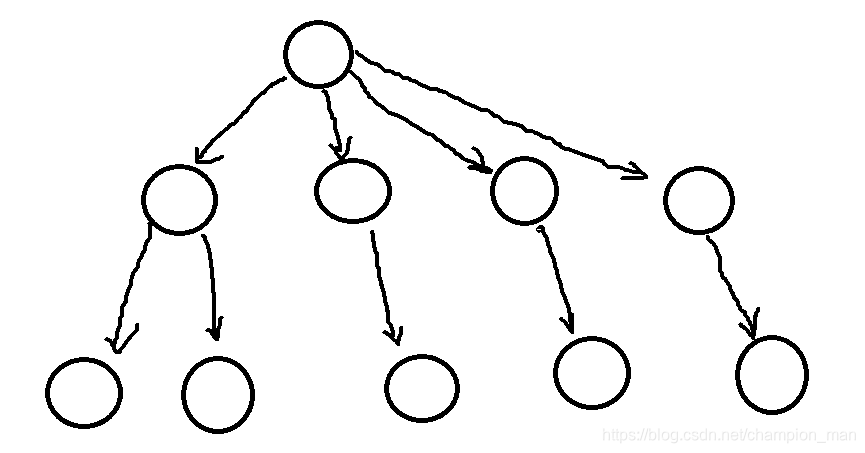
树结构的文件系统。
每个节点有四部分组成:
- data: Znode存储的数据信息
- ACL:记录Znode的访问权限
- stat:Znode的各种元数据,比如事务ID,版本号。
- child: 当前节点的子节点引用
二,通知机制(Watch)
我们可以把Watch理解成是注册在特定的Znode上的触发器,当这个Znode发生改变,也就是调用create,delete,setData方法的时候,将会触发Znode上注册的对应事件。请求Watch的客户端会接收到异步通知。见下图:
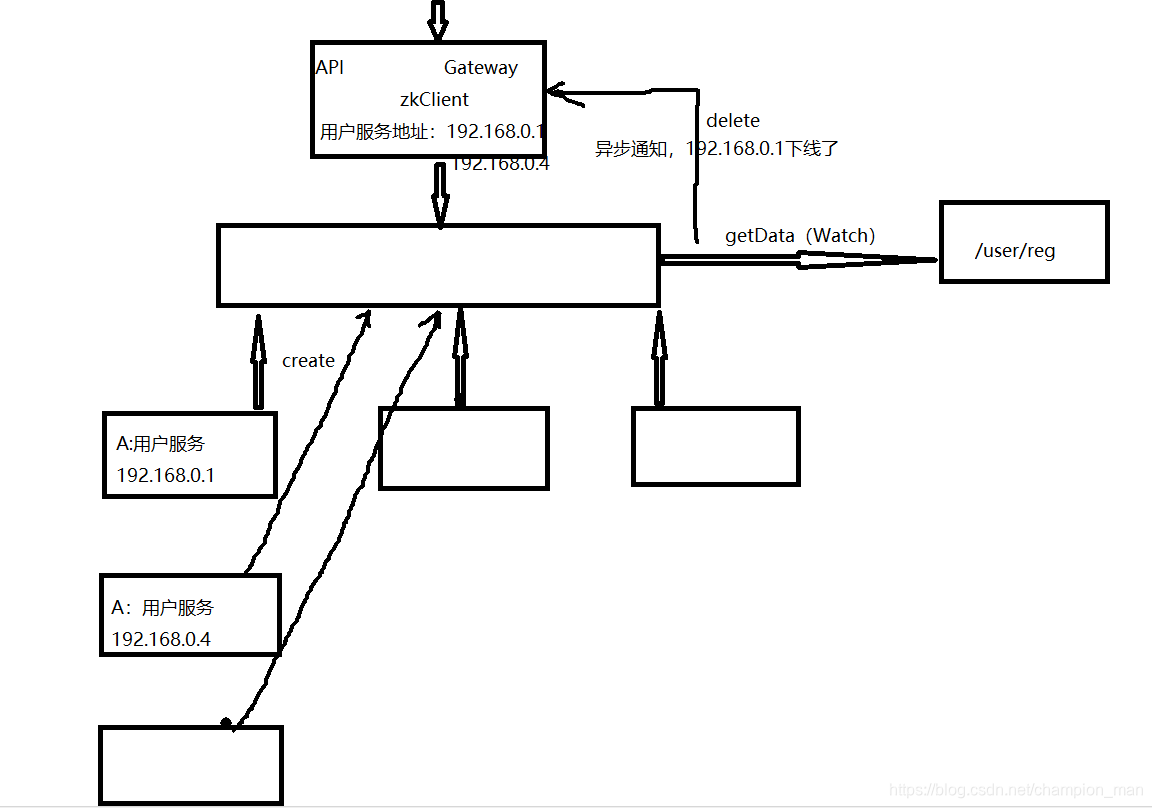
三,服务注册与发现
四:分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。厕所有言:来也冲冲,去也冲冲,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









