







Unifying Homophily and Heterophily for Spectral Graph Neural Networks via Triple Filter Ensembles
Neurips24
#paper/⭐⭐# #paper/异配图#
给二的原因是更早的polygcl(ICLR24)已经在对比学习上使用了
动机:
在图神经网络的特征提取过程中,混合使用单一滤波器同时处理不同频率的特征,容易造成信号成分间的相互干扰。
我的理解:这类似于白光中不同波长光波的杂糅效应。受光学三原色原理的启发,我们将图信号解耦为低频特征和高频特征进行独立处理——如同将白光分解为红、绿、蓝三种基础色光。这种基于特征解耦的建模方式,通过分解和重组独立的特征分量,能够更精准地拟合复杂的信号特征,其原理类似于通过调节三原色光强来精确复现目标光谱
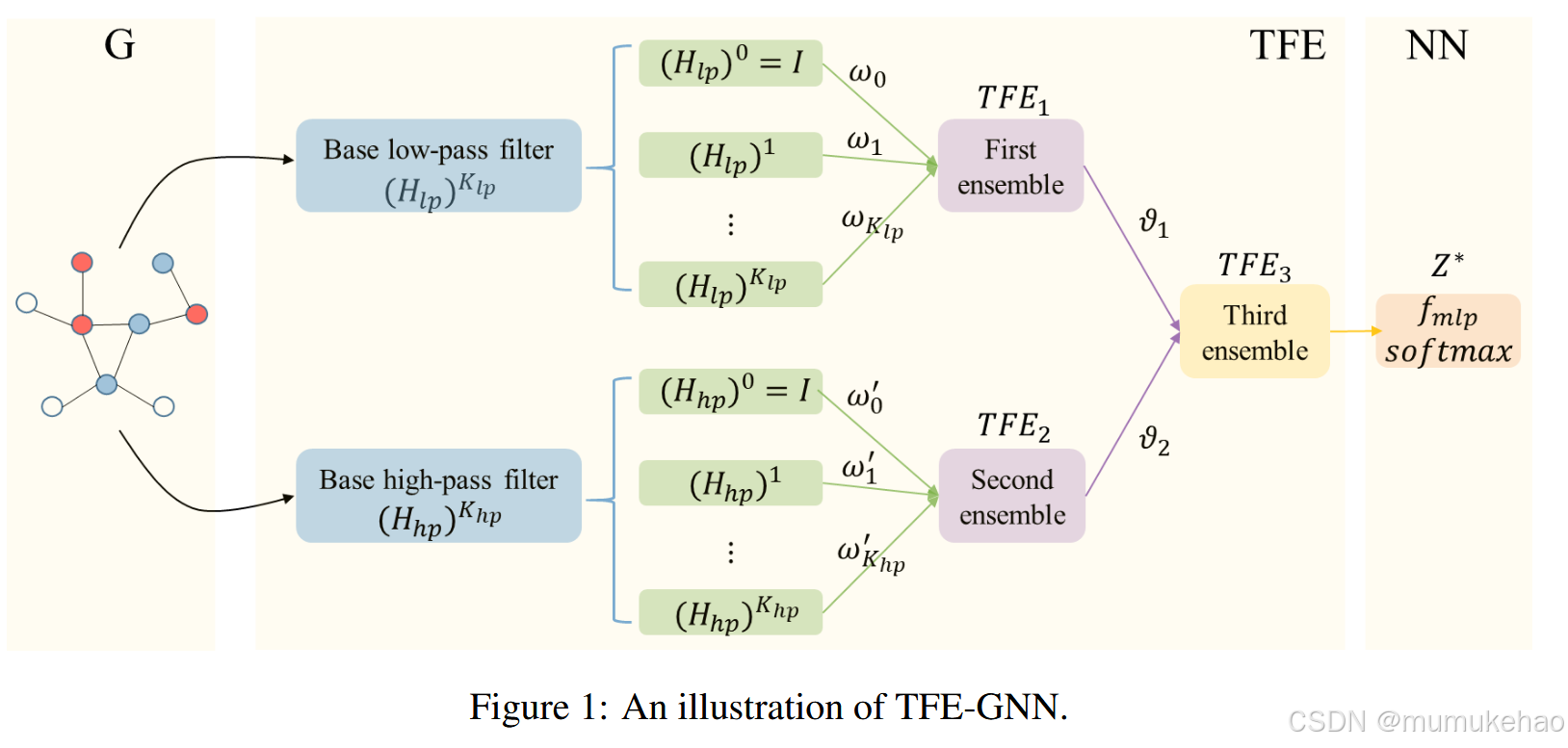
方法
基滤波器
H l p H_{lp} Hlp--> L s u m a = I − L s u m = D − 1 / 2 A D − 1 / 2 L_{sum}^{a}=I-L_{sum}=D^{-1/2}AD^{-1/2} Lsuma=I−Lsum=D−1/2AD−1/2
H h p H_{hp} Hhp--> L r w a = I − L r w = D − 1 A . L_{rw}^{a}=I-L_{rw}=D^{-1}A. Lrwa=I−Lrw=D−1A.
低通,高通与拟合的滤波器:
T F E 1 = E M 1 { ω 0 I , ω 1 H l p , ω 2 ( H l p ) 2 , ⋯ , ω K l n ( H l p ) K l p } TFE_{1}=EM_{1}\{\omega_{0}I,\omega_{1}H_{l\boldsymbol{p}},\omega_{2}(H_{l\boldsymbol{p}})^{2},\cdots,\omega_{K_{l\boldsymbol{n}}}(H_{l\boldsymbol{p}})^{K_{l\boldsymbol{p}}}\} TFE1=EM1{ω0I,ω1Hlp,ω2(Hlp)2,⋯,ωKln(Hlp)Klp}
T F E 2 = E M 2 { ω 0 ′ I , ω 1 ′ H h p , ω 2 ′ ( H h p ) 2 , ⋯ , ω K h p ′ ( H h p ) K h p } TFE_2=EM_2\{\omega_0^{\prime}I,\omega_1^{\prime}H_{\boldsymbol{h}p},\omega_2^{\prime}(H_{\boldsymbol{h}p})^2,\cdots,\omega_{K_{\boldsymbol{h}\boldsymbol{p}}}^{\prime}(H_{\boldsymbol{h}p})^{K_{\boldsymbol{h}\boldsymbol{p}}}\} TFE2=EM2{ω0′I,ω1′Hhp,ω2′(Hhp)2,⋯,ωKhp′(Hhp)Khp}
T F E 3 = E M 3 { ϑ 1 T F E 1 , ϑ 2 T F E 2 } TFE_3=EM_3\{\vartheta_1TFE_1,\vartheta_2TFE_2\} TFE3=EM3{ϑ1TFE1,ϑ2TFE2}
EM代表combination操作,w是可学习的系数, ϑ \vartheta ϑ也是可学习的系数
TFE-GNN
构造好光谱基后,接下来就是完整的模型了:
Z = T F E 3 ⋅ X = E M 3 { ϑ 1 T F E 1 , ϑ 2 T F E 2 } ⋅ X = E M 3 { ϑ 1 T F E 1 ⋅ X , ϑ 2 T F E 2 ⋅ X } Z=TFE_3\cdot X=EM_3\{\vartheta_1TFE_1,\vartheta_2TFE_2\}\cdot X=EM_3\{\vartheta_1TFE_1\cdot X,\vartheta_2TFE_2\cdot X\} Z=TFE3⋅X=EM3{ϑ1TFE1,ϑ2TFE2}⋅X=EM3{ϑ1TFE1⋅X,ϑ2TFE2⋅X}
由于最右侧的第一项代表低通特征,第二项代表高通特征,因此:
Z = E M 3 { ϑ 1 Z l p , ϑ 2 Z h p } Z=EM_3\{\vartheta_1Z_{lp},\vartheta_2Z_{hp}\} Z=EM3{ϑ1Zlp,ϑ2Zhp}
分类损失:
Z ~ = f m l p ( Z ) Z ∗ = s o f t m a x ( Z ~ ) L = − ∑ r ∈ Y L Y r ⊤ l o g ( Z r ∗ ) , \begin{aligned}&\tilde{Z}=f_{mlp}(Z)\\&Z^*=softmax(\tilde{Z})\\&\mathscr{L}=-\sum_{r\in\mathbb{Y}_\mathrm{L}}Y_r^\top log(Z_r^*),\end{aligned} Z~=fmlp(Z)Z∗=softmax(Z~)L=−r∈YL∑Yr⊤log(Zr∗),
注:Z具体的可以写为:
Z = { ϑ 1 Z l p + ϑ 2 Z h p = ( ϑ 1 T F E 1 + ϑ 2 T F E 2 ) ⋅ X = ( ϑ 1 ∑ i = 0 K l p ω i ( H l p ) i + ϑ 2 ∑ j = 0 K h p ω j ′ ( H h p ) j ) ⋅ X ϑ 1 Z l p ∥ ϑ 2 Z h p = ( ϑ 1 T F E 1 ∥ ϑ 2 T F E 2 ) ⋅ X = ( ϑ 1 ∑ i = 0 K l p ω i ( H l p ) i ∥ ϑ 2 ∑ j = 0 K h p ω j ′ ( H h p ) j ) ⋅ X , \left.Z=\left\{\begin{array}{c}\vartheta_1Z_{lp}+\vartheta_2Z_{hp}=(\vartheta_1TFE_1+\vartheta_2TFE_2)\cdot X=(\vartheta_1\sum_{i=0}^{K_{lp}}\omega_i(H_{lp})^i+\vartheta_2\sum_{j=0}^{K_{hp}}\omega_j^{\prime}(H_{hp})^j)\cdot X\\\\\vartheta_1Z_{lp}\|\vartheta_2Z_{hp}=(\vartheta_1TFE_1\|\vartheta_2TFE_2)\cdot X=(\vartheta_1\sum_{i=0}^{K_{lp}}\omega_i(H_{lp})^i\|\vartheta_2\sum_{j=0}^{K_{hp}}\omega_j^{\prime}(H_{hp})^j)\cdot X,\end{array}\right.\right. Z=⎩ ⎨ ⎧ϑ1Zlp+ϑ2Zhp=(ϑ1TFE1+ϑ2TFE2)⋅X=(ϑ1∑i=0Klpωi(Hlp)i+ϑ2∑j=0Khpωj′(Hhp)j)⋅Xϑ1Zlp∥ϑ2Zhp=(ϑ1TFE1∥ϑ2TFE2)⋅X=(ϑ1∑i=0Klpωi(Hlp)i∥ϑ2∑j=0Khpωj′(Hhp)j)⋅X,
结果:
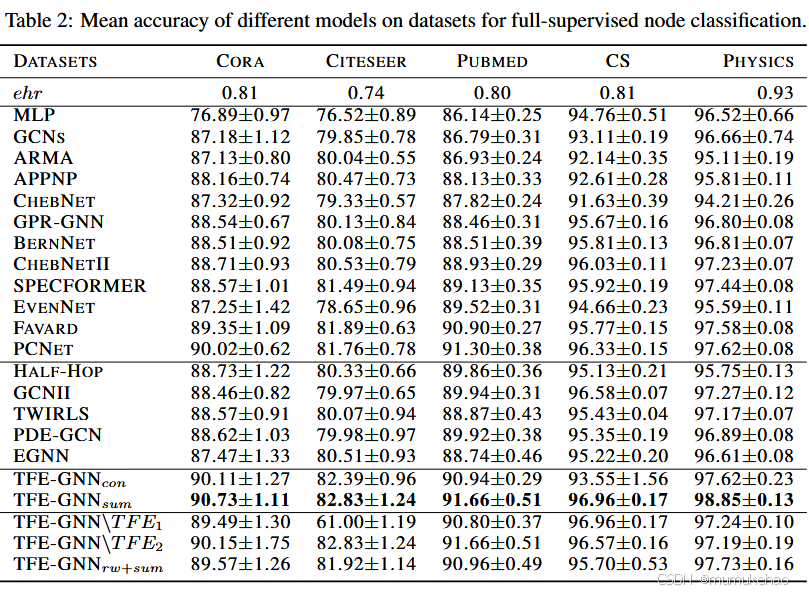
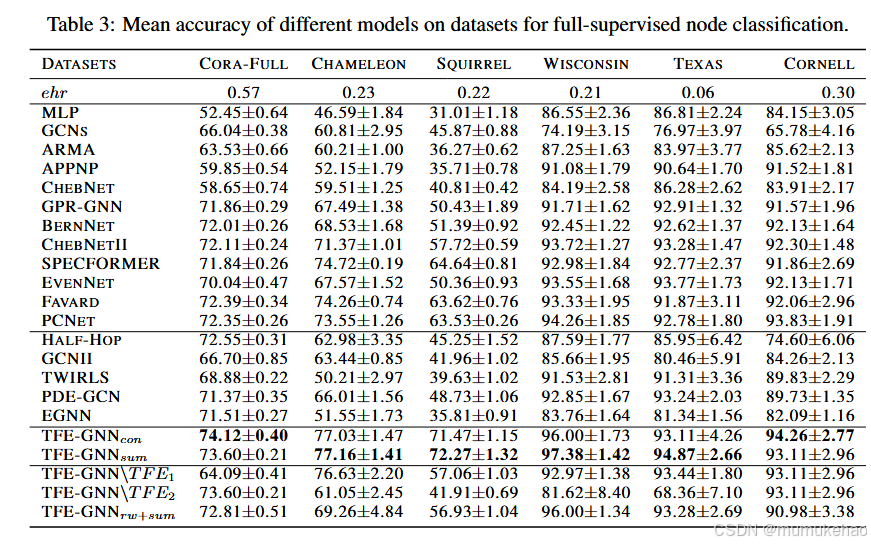


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









