







TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs
Neurips 24
推荐指数:#paper/⭐⭐⭐#(数据集)
动机
原有的数据集,其缺乏textual信息
- TEG-DB是第一个专门为文本边图设计的开放数据集和基准
- 我们进行了广泛的基准测试实验,并对基于TEK的方法进行了全面分析,深入研究了各个方面,例如不同模型和不同规模的PLM生成的嵌入的影响、GNN中不同嵌入方法(包括分离和纠缠嵌入)的后果、边缘文本的影响和不同领域数据集的影响。通过应对关键挑战并强调有希望的机会,我们的研究刺激并指导了TEK勘探和开发的未来方向。(一会重写)
数据集
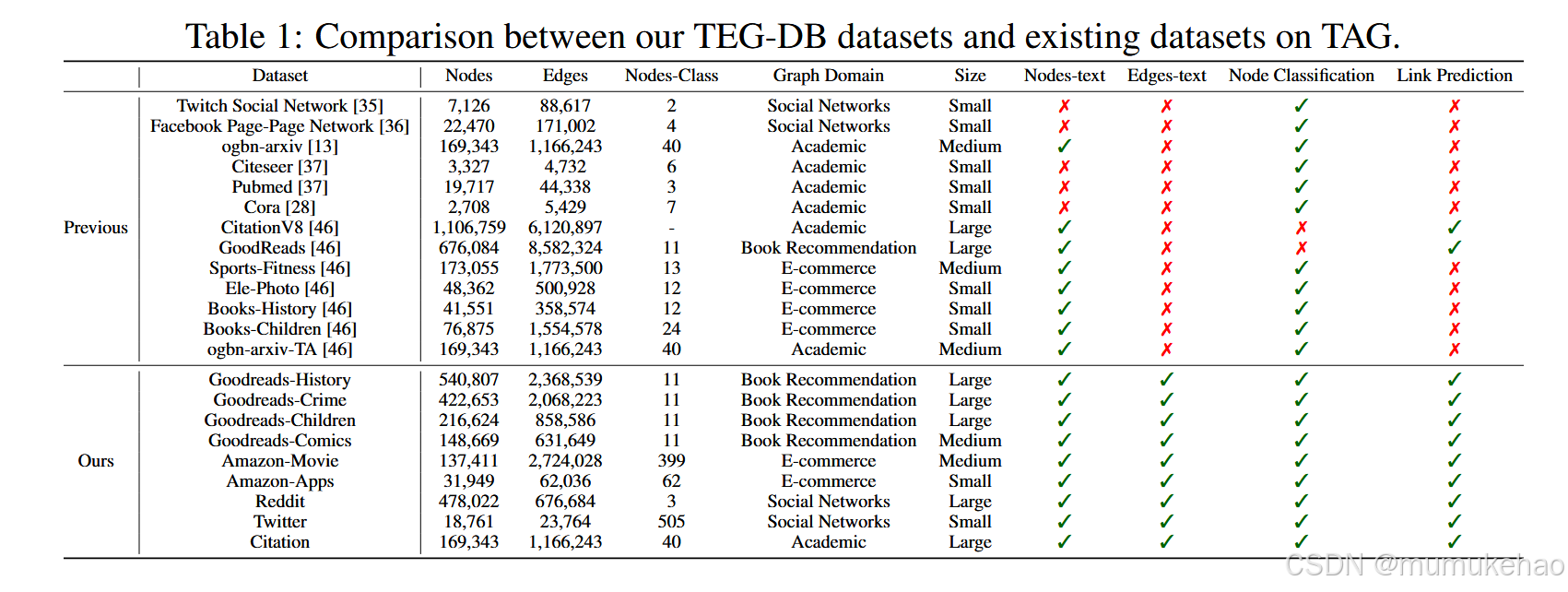
已存在方法的实施:
基于PLM的方法
h u ( k + 1 ) = M L P ψ ( k ) ( h u ( k ) ) h u ( 0 ) = P L M ( T u ) + ∑ v ∈ N ( u ) P L M ( T e v , u ) \begin{aligned}h_{u}^{(k+1)}&=\mathrm{MLP}_{\boldsymbol{\psi}}^{(k)}\left(h_u^{(k)}\right)\\h_{u}^{(0)}&=\mathrm{PLM}(T_{u})+\sum_{v\in\mathcal{N}(u)}\mathrm{PLM}(T_{e_{v,u}})\end{aligned} hu(k+1)hu(0)=MLPψ(k)(hu(k))=PLM(Tu)+v∈N(u)∑PLM(Tev,u)
T u T_{\boldsymbol{u}} Tu与 T e v , u T_{e_{v,u}} Tev,u分别代表节点u的原始文本以及边 e u , v e_{u,v} eu,v的文本。
Edge-aware的基于GNN的范式
h u ( k + 1 ) = U P D A T E ω ( k ) ( h u ( k ) , A G G R E G A T E ω ( k ) ( { h v ( k ) , e v , u , v ∈ N ( u ) } ) ) \boldsymbol{h}_u^{(k+1)}=\mathrm{UPDATE}_{\boldsymbol{\omega}}^{(k)}\left(\boldsymbol{h}_u^{(k)},\mathrm{AGGREGATE}_{\boldsymbol{\omega}}^{(k)}\left(\left\{\boldsymbol{h}_v^{(k)},\boldsymbol{e}_{v,\boldsymbol{u}},v\in\mathcal{N}(u)\right\}\right)\right) hu(k+1)=UPDATEω(k)(hu(k),AGGREGATEω(k)({hv(k),ev,u,v∈N(u)}))
但是,其有如下两个问题:
- 在TEG中,节点与边文本通常具有语义强耦合性(例如社交网络中用户节点的描述与评论边内容互为补充)。传统GNN将二者独立编码为分离的嵌入向量,导致交互依存关系丢失。
- GNN的静态嵌入机制难以捕捉文本边中动态语境信息(如多义词在不同边中的语义差异、长文本的篇章逻辑)。
纠缠的GNN范式
现有方法通常独立编码节点与边文本(先提取边文本嵌入,再输入GNN),忽略了二者在TEG中的强语义耦合性(如节点内容与边文本的逻辑关联)。这种分离式嵌入会破坏交互依赖信息。
因此,作者提出的这种范式,在嵌入生成前,将相连节点与边的文本进行联合编码(如拼接或交叉注意力),捕获其交互语义后再生成联合嵌入。
h u ( k + 1 ) = U P D A T E ω ( k ) ( h u ( k ) , A G G R E G A T E ω ( k ) ( { h v ( k ) , v ∈ N ( u ) } ) ) h u 0 = P L M ( T u , { T v , T e v , u , v ∈ N ( u ) } ) \begin{aligned} h_{u}^{(k+1)} & =\mathrm{UPDATE}_{\boldsymbol{\omega}}^{(k)}\left(h_{u}^{(k)},\mathrm{AGGREGATE}_{\boldsymbol{\omega}}^{(k)}\left(\left\{\boldsymbol{h}_{v}^{(k)},v\in\mathcal{N}(u)\right\}\right)\right) \\ h_{u}^{0} & =\mathrm{PLM}(T_{u},\{T_{v},T_{e_{v,u}},v\in\mathcal{N}(u)\}) \end{aligned} hu(k+1)hu0=UPDATEω(k)(hu(k),AGGREGATEω(k)({hv(k),v∈N(u)}))=PLM(Tu,{Tv,Tev,u,v∈N(u)})
结果及分析
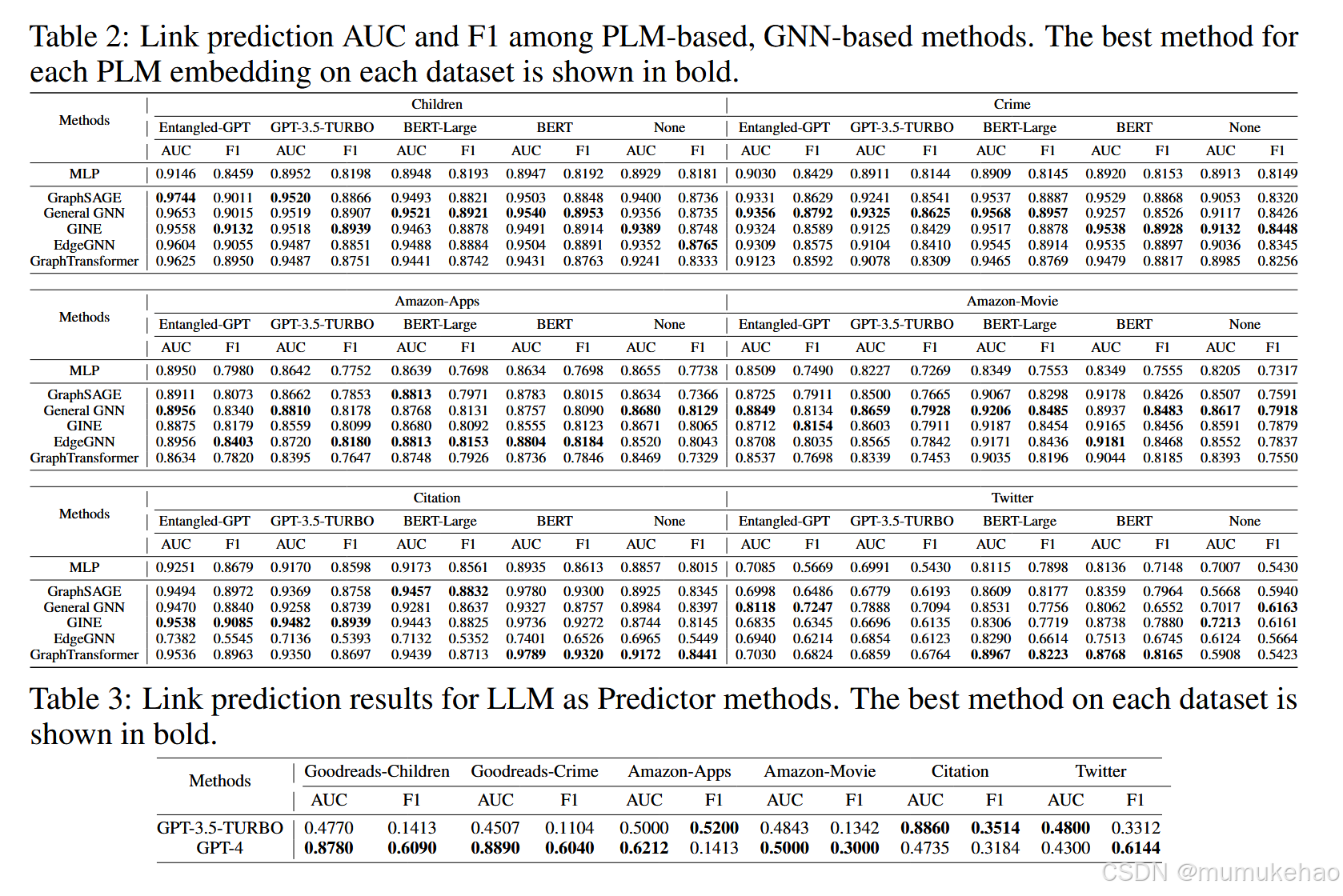
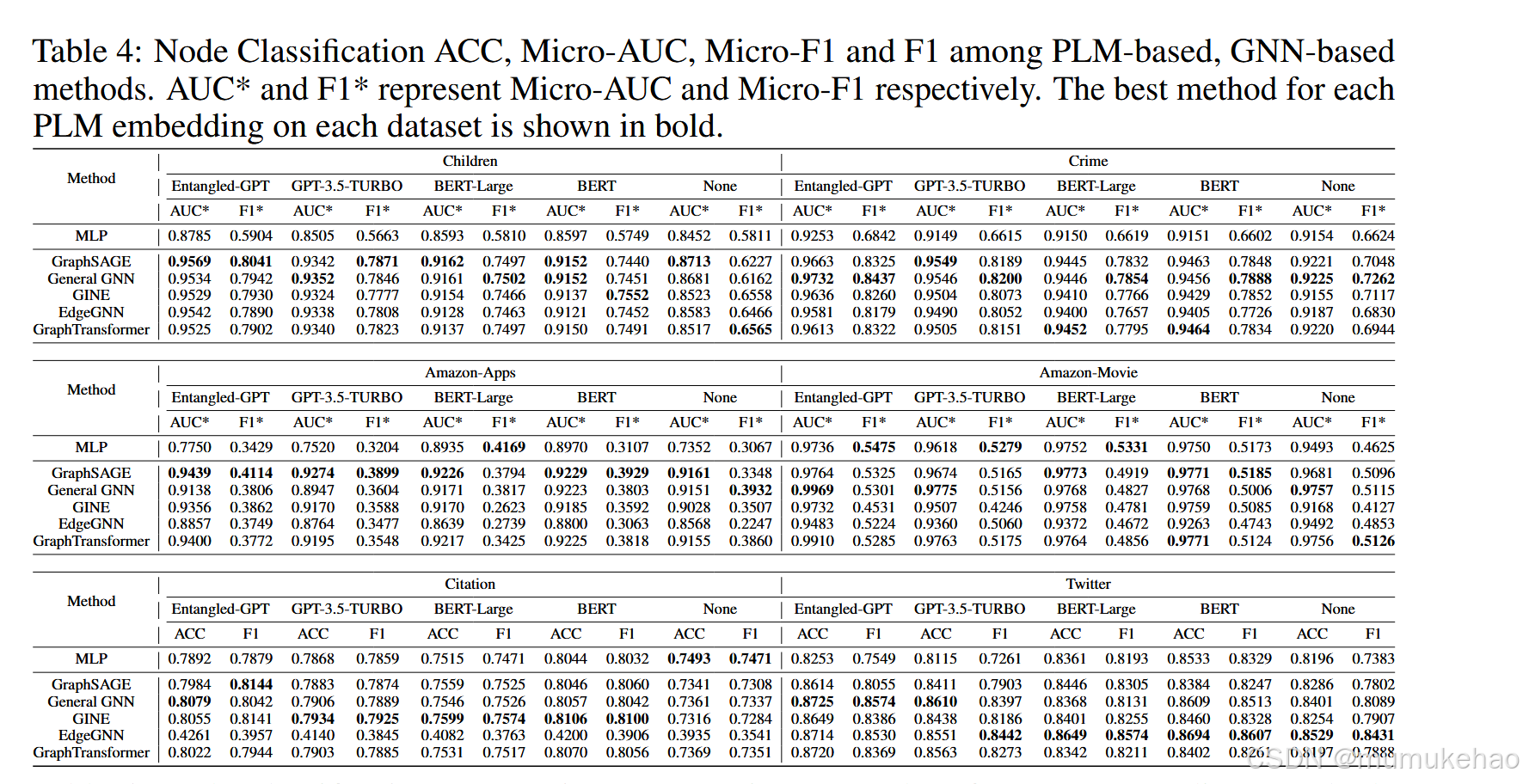
注意:如下的Entangled-GPT采用的是纠缠的GNN范式。GPT-3.5-TURBO则直接讲文本输入到GPT中预测。
链路预测
节点分类
总结:
- 模型选择与数据特性强相关最优模型因数据集而异
- 边文本的不可替代性
- 纠缠式编码可以提升模型性能
- PLM规模与性能正相关
- LLM直接预测的局限性(对图结构的理解能力不足)。改进方向是需要结合图神经网络或涉及图感知的LLM微调策略,来融合文本语意
总结:TEG任务的成功依赖于语义与结构的联合建模。未来方向包括:
- 设计更高效的纠缠式编码架构;
- 探索轻量化PLM与GNN的融合方法;
- 开发图结构感知的LLM微调技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









