



 本文介绍了Appium中元素定位的多种方式,如ID、accessibility_id和XPath,并强调了隐式等待的作用。通过日志分析,展示了Appium在元素查找失败后的智能等待机制。
本文介绍了Appium中元素定位的多种方式,如ID、accessibility_id和XPath,并强调了隐式等待的作用。通过日志分析,展示了Appium在元素查找失败后的智能等待机制。
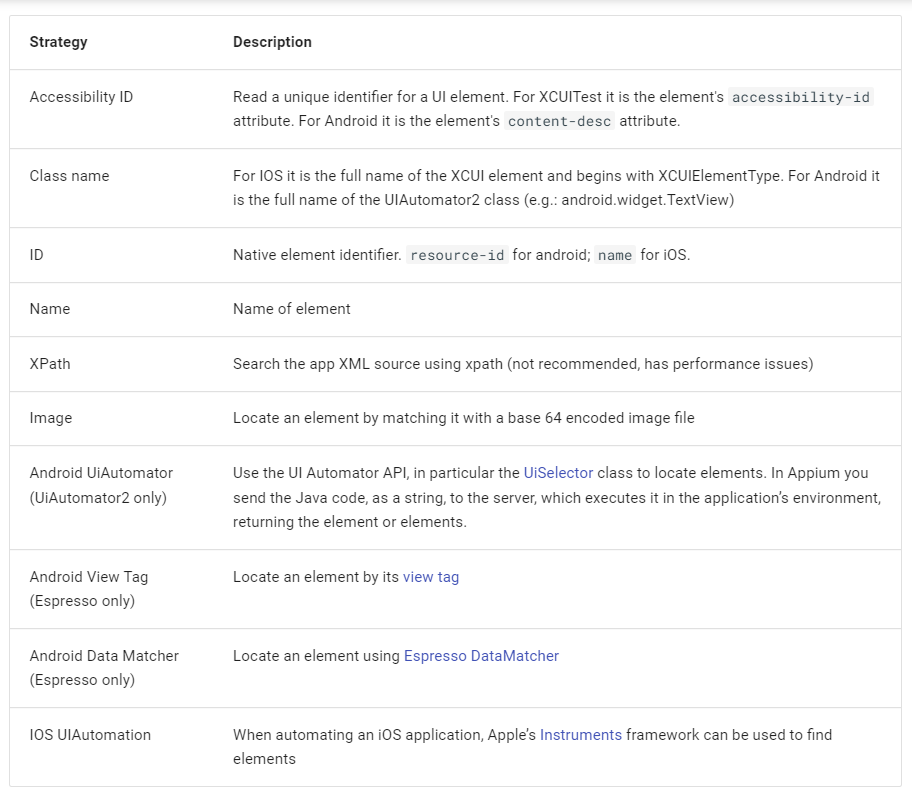
元素定位是 UI 自动化测试中最关键的一步,假如没有定位到元素,也就无法完成对页面的操作。那么在页面中如何定位到想要的元素,本小节讨论 Appium 元素定位方式。
Appium的元素定位方式
定位页面的元素有很多方式,比如可以通过 ID、accessibility_id、XPath 等方式进行元素定位,还可以使用 Android、iOS 工作引擎里面提供的定位方式。

隐式等待
设置隐式等待后可以在规定的时间之内去动态的等待元素出现。
假如设置了隐式等待时长为 10 秒,会在 10 秒之内不停的查找元素,如果第 2 秒就找到了元素,就继续执行后面的测试代码,如果超出了设置时间则抛出异常。
一旦设置了隐式等待,则它会存在整个 WebDriver 对象实例的生命周期中,比如:每次调用 find_element 或者 find_elements 方法的时候,会自动触发隐式等待。
隐式等待比强制等待更加智能,后者只能选择一个固定的时间等待,前者可以在一个时间范围内智能的等待。代码示范:
- Python 版本
...
self.driver = webdriver.Remote(server, desired_caps)
self.driver.implicitly_wait(15)
...
- Java 版本
...
driver = new AndroidDriver(remoteUrl, desiredCapabilities);
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
...
Appium 的 log 中能发现以下的情况,注意下面的 xx 和 xxy 是对 ID 的简写:
[W3C] Matched W3C error code 'no such element' to NoSuchElementError
[BaseDriver] Waited for 1495 ms so far
[WD Proxy] Matched '/element' to command name 'findElement'
……
[W3C] Matched W3C error code 'no such element' to NoSuchElementError
[BaseDriver] Waited for 2707 ms so far
[WD Proxy] Matched '/element' to command name 'findElement'
……
[HTTP] <-- POST /wd/hub/session/xx/element 200 6653 ms - 137
[HTTP]
[HTTP] --> POST /wd/hub/session/xx/element/xxy/click
[HTTP] {"id":"xxy"}
从日志上可以看出来,Appium 在进行元素查找的时候,失败后不会直接抛出异常停止脚本执行,而是每过一段时间去找一次元素。上面的例子所示,在 6.7 秒左右等到了元素的返回,此时结束等待,去执行点击操作。

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}