







 本文深入探讨了生成对抗网络(GAN)的工作原理,通过生动的比喻解释了GAN如何通过生成模型与判别模型的博弈达到数据分布的学习。文章详细解析了GAN的数学表示,包括模型的目标函数、优化过程及全局最优解的求解。
本文深入探讨了生成对抗网络(GAN)的工作原理,通过生动的比喻解释了GAN如何通过生成模型与判别模型的博弈达到数据分布的学习。文章详细解析了GAN的数学表示,包括模型的目标函数、优化过程及全局最优解的求解。
1 什么是 Generative Adversarial Network ?
首先,我们需要充分的了解什么是生成对抗网络( tive adversarial network,GAN)?顾名思义, 首先它是一种生成模型,它的核心是对样本数据建模。下面我们将举个例子来详细的说明一下什么是GAN。
首先,我是一个收藏家,我有很多的宝贝,但是,我最终的目标不仅仅是一个收藏家。我想高仿东西,成为工艺品大师(做仿品)。我要不惜一切代价的成为这方面的大师。但是,我做出来的东西不能只是我白己分辨不出来就够了,那就只能放在家里看,它需要接受大师们的检验,各位专家都看不出来这是仿品,就比较成功了。
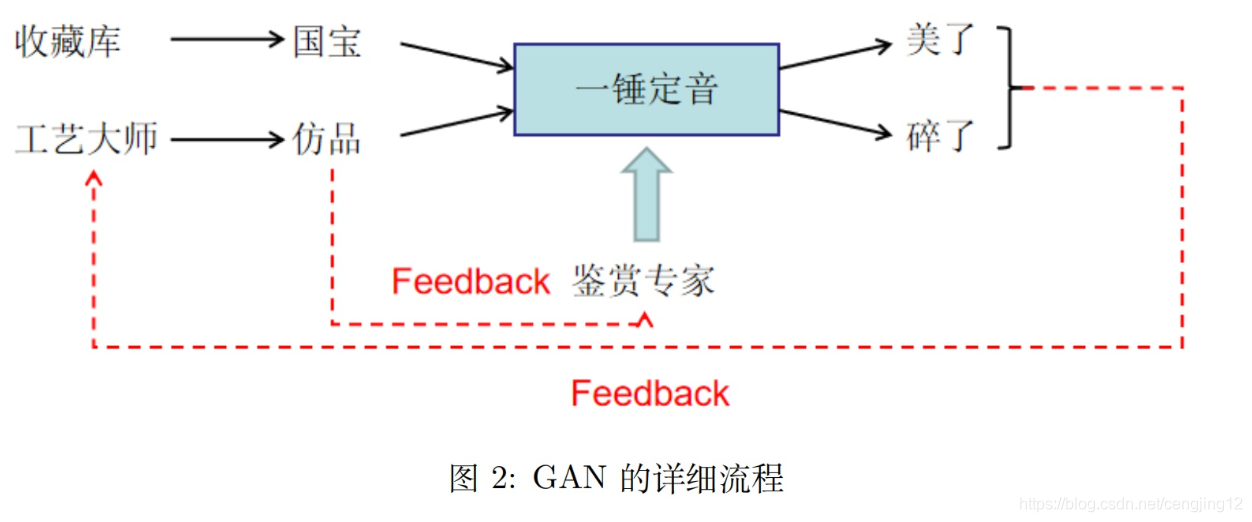
我把我做出的东西,放到一个叫“一锤定音”节口现场,这个平台将鉴别出为假的东西就砸了,鉴别出为真的东西就拿去估值,就美了。节囗流程如下所示

我们的目标是成为高水平的可以做“以假乱真”的高质量仿品的大师,有如下两个要求:
- 鉴赏专家的水平足够高
- 作假的水平足够高。
国宝是古人做的,静态的,不可能发生变化的。而工艺品和作假的水平是变化的。三者中,国宝是静态的,其他的都是可变化的。
有可能有的同学会迷惑,这和生成模型之间有什么关系呢?如果一个仿品可以和国宝做的一模样,不就相当于学到了真实数据的分布,可以完全模拟出真实数据。下一步则是,想办法将模型用数学语言描述。
2数学语言描述
2.1 模型表示
工艺大帅和鉴赏专家的水平会不断的提高,最终我们会培养一个高水平的工艺大师和一个高水平的鉴赏家。而最终的口的是培养一个高水平的工艺大师,而不是一个高水平的鉴赏家。鉴赏家只是衍生品,最终将达到两个口的,1.足够的以假乱真;2.真正的专家看不出来
所以,我们需要加一些 feedback,令工艺大师收到专家给出的反馈。并且鉴赏大师也要从工艺大师那里知道真实的情况来提升自己的水平。如下图所示:
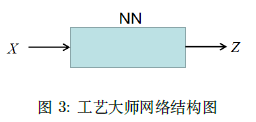
我们可以将古人,视为 Pdata ,{xi}i=1N,P_{\text {data }},\left\{x_{i}\right\}_{i=1}^{N},Pdata ,{xi}i=1N, 实际就是经验分布,通常我们将经验分布视为数据分布。 工艺品,是从一个模型分布 PgP_{g}Pg 采样出来的, Pg(x;θg)P_{g}\left(x ; \theta_{g}\right)Pg(x;θg) 。我们本身不对 PgP_{g}Pg 建模,而是用一个神经网络来逼近 Pg∘P_{g \circ}Pg∘ 假设 zzz 来自一个简单分布,并增加噪声, z∼Pz(z)z \sim P_{z}(z)z∼Pz(z) 。其中 ,x=G(z;θg), x=G\left(z ; \theta_{g}\right),x=G(z;θg)
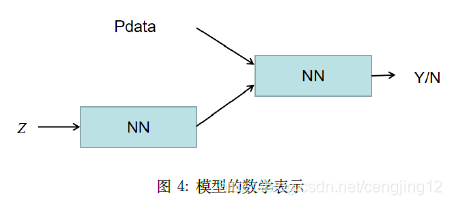
鉴赏专家输出的是一个概率分布,同样也是一个神经网络,D (x,θd),\left(x, \theta_{d}\right),(x,θd), 其代表的基输入一个物品判断其为国宝的概率。D →1\rightarrow 1→1 是国宝, D→0D \rightarrow 0D→0 是工艺品。模型如下所示:
我们的目标有两个:
- 高专家:高水平的专家可以正确的分辨国宝和尖品。
{ if x is from Pdata then D(x)↑ if x is from Pg then 1−D(x)↓ \left\{\begin{array}{l} \text { if } x \text { is from } P_{\text {data }} \text { then } D(x) \uparrow \\ \text { if } x \text { is from } P_{g} \text { then } 1-D(x) \downarrow \end{array}\right. { if x is from Pdata then D(x)↑ if x is from Pg then 1−D(x)↓
其中,我们将用对数似然函数的形式来进行表达。而 1−D(x)1-D(x)1−D(x) 中的 xxx 是来自 G(z)G(z)G(z) 的,那么,高专家部分的目标函数为:
maxDEx∼Pdata[logD(x)]⏟1N∑i=1NlogD(xi)+Ex∼Pz[log(1−D(G(z)))] \max _{D} \underbrace{\mathbb{E}_{x \sim P_{\text {data}}}[\log D(x)]}_{\frac{1}{N} \sum_{i=1}^{N} \log D\left(x_{i}\right)}+\mathbb{E}_{x \sim P_{z}}[\log (1-D(G(z)))] DmaxN1∑i=1NlogD(xi)Ex∼Pdata[logD(x)]+Ex∼Pz[log(1−D(G(z)))] - 高大师: 高水平的大师的目的就是要造成高水平的鉴赏专家分辨不出来的工艺品,可以表示为:
if x is from Pg then log(1−D(G(z)))↑ \text { if } x \text { is from } P_{g} \text { then } \log (1-D(G(z))) \uparrow if x is from Pg then log(1−D(G(z)))↑
此目标表达为数学语言即为:
minGEz∼Pg[log(1−D(z))] \min _{G} \mathbb{E}_{z \sim P_{g}}[\log (1-D(z))] GminEz∼Pg[log(1−D(z))]
根据图 2 中的 feedback 流向,我们可以了解到,先优化鉴赏专家,再优化工艺大师。总优化目标是:
minGmaxDEx∼Pdata [logD(x)]+Ex∼Pz[log(1−D(G(z)))] \min _{G} \max _{D} \mathbb{E}_{x \sim P_{\text {data }}}[\log D(x)]+\mathbb{E}_{x \sim P_{z}}[\log (1-D(G(z)))]GminDmaxEx∼Pdata [logD(x)]+Ex∼Pz[log(1−D(G(z)))]
2.2 小结
GAN 模型本身思想很简单,难点主要在于学习 θg,θd\theta_{g}, \theta_{d}θg,θd 。GAN 中没有直接面向 PgP_{g}Pg 建模,而是从一 个可微的 NN 中采样来逼近 Dg(x;θg)D_{g}\left(x ; \theta_{g}\right)Dg(x;θg) 。不是直接面对分布,而是绕过复杂的求解过程来近似。我们之 前分析过,如果用 NN 来近似概率分布,这叫 Implicit Density Model。下一步则是考虑如何求解全局最优解。
3 全局最优解
GAN 模型表示汇总如下所示:
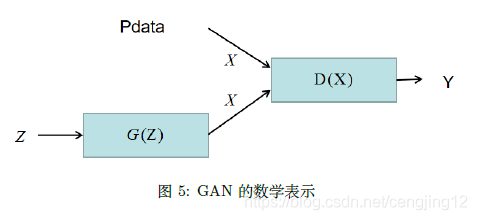
Pdata:{xi}i=1NPg(x;θg): generator ,G(z;θg)y∣x: discriminater ,P(y=1∣x)=D(x),P(y=0∣x)=1−D(x) (5)
\begin{array}{l}
P_{d a t a}:\left\{x_{i}\right\}_{i=1}^{N} \\
P_{g}\left(x ; \theta_{g}\right): \text { generator }, G\left(z ; \theta_{g}\right) \\
y | x: \text { discriminater }, P(y=1 | x)=D(x), P(y=0 | x)=1-D(x)
\end{array} \ \ \ \ \ \ (5)
Pdata:{xi}i=1NPg(x;θg): generator ,G(z;θg)y∣x: discriminater ,P(y=1∣x)=D(x),P(y=0∣x)=1−D(x) (5)
G(z;θg)G\left(z ; \theta_{g}\right)G(z;θg) 和 D(x;θd)D\left(x ; \theta_{d}\right)D(x;θd) 是两个多层感知机。GAN 就是这样采用对抗学习,其最终目的就是 Pg=P_{g}=Pg= Pdata P_{\text {data }}Pdata 。目标函数中,记:
V(D,G)=Ex∼Pdata[logD(x)]+Ex∼Pz[log(1−D(G(z)))] (6)
V(D, G)=\mathbb{E}_{x \sim P_{\text {data}}[\log D(x)]}+\mathbb{E}_{x \sim P_{z}}[\log (1-D(G(z)))] \ \ \ \ \ \ (6)
V(D,G)=Ex∼Pdata[logD(x)]+Ex∼Pz[log(1−D(G(z)))] (6)
最终的目标是令 Pg=Pdata,P_{g}=P_{\text {data}},Pg=Pdata, 而 PgP_{g}Pg 中的参数为 θg\theta_{g}θg 。在之前的极大似然估计思想中,
θg=argmaxθg∑i=1NlogPg(xi) (7)
\theta_{g}=\arg \max _{\theta_{g}} \sum_{i=1}^{N} \log P_{g}\left(x_{i}\right) \ \ \ \ \ \ (7)
θg=argθgmaxi=1∑NlogPg(xi) (7)
而对 Pg(xi)P_{g}\left(x_{i}\right)Pg(xi) 比较复杂,通常采用 EM 算法和 VI 来进行近似,通过推导可以得出,最后的目标为:
argminθgKL(Pdata ∥Pg)
\arg \min _{\theta_{g}} \mathrm{KL}\left(P_{\text {data }} \| P_{g}\right)
argθgminKL(Pdata ∥Pg)
对公式 (5) 的求解过程可以分成两步,而第一步为求解过依为 fixed G,求解 maxpV(G,D)max_p V(G, D)maxpV(G,D)
maxDV(D,G)=∫Pdata logDdx+∫Pglog(1−D)dx=∫(Pdata logDdx+Pglog(1−D))dx (8)
\begin{aligned}
\max _{D} V(D, G) &=\int P_{\text {data }} \log D d x+\int P_{g} \log (1-D) d x \\
&=\int\left(P_{\text {data }} \log D d x+P_{g} \log (1-D)\right) d x
\end{aligned} \ \ \ \ \ \ (8)
DmaxV(D,G)=∫Pdata logDdx+∫Pglog(1−D)dx=∫(Pdata logDdx+Pglog(1−D))dx (8)
通过求偏导来计算最优解:
∂(V(D,G))∂D=∂∂D∫[Pdata logDdx+Pglog(1−D)]dx=∫∂∂D[Pdata logDdx+Pglog(1−D)]dx=0
\begin{aligned}
\frac{\partial(V(D, G))}{\partial D} &=\frac{\partial}{\partial D} \int\left[P_{\text {data }} \log D d x+P_{g} \log (1-D)\right] d x \\
&=\int \frac{\partial}{\partial D}\left[P_{\text {data }} \log D d x+P_{g} \log (1-D)\right] d x \\
&=0
\end{aligned}
∂D∂(V(D,G))=∂D∂∫[Pdata logDdx+Pglog(1−D)]dx=∫∂D∂[Pdata logDdx+Pglog(1−D)]dx=0
这一步的推导利用了微积分的基本定理,得到:
∫Pdata ⋅1D+Pg−11−Ddx=0
\int P_{\text {data }} \cdot \frac{1}{D}+P_{g} \frac{-1}{1-D} d x=0
∫Pdata ⋅D1+Pg1−D−1dx=0
恒成立,所以有:
D∗=Pdata Pdata +Pg
D^{*}=\frac{P_{\text {data }}}{P_{\text {data }}+P_{g}}
D∗=Pdata +PgPdata
第二步,将求解的是:
minGmaxDV(D,G)=minGV(D∗,G)=minDEx∼Pdata [logPdata Pdata +Pg]+Ex∼Pg[logPgPdata +Pg]
\begin{aligned}
\min _{G} \max _{D} V(D, G) &=\min _{G} V\left(D^{*}, G\right) \\
&=\min _{D} \mathbb{E}_{x \sim P_{\text {data }}}\left[\log \frac{P_{\text {data }}}{P_{\text {data }}+P_{g}}\right]+\mathbb{E}_{x \sim P_{g}}\left[\log \frac{P_{g}}{P_{\text {data }}+P_{g}}\right]
\end{aligned}
GminDmaxV(D,G)=GminV(D∗,G)=DminEx∼Pdata [logPdata +PgPdata ]+Ex∼Pg[logPdata +PgPg]
观赛 Ex∼Pdata [logPates Pdath +Pg]\mathbb{E}_{x \sim P_{\text {data }}}\left[\log \frac{P_{\text {ates }}}{P_{\text {dath }}+P_{g}}\right]Ex∼Pdata [logPdath +PgPates ] 会发现这很像一个 KL\mathrm{KL}KL 散度,但是 Pdata+PgP_{\mathrm{data}}+P_{g}Pdata+Pg 不是一个板率分布。所以,
minGmaxDV(D,G)=minGEx∼Pdate [logPdata Ptata +Pg2⋅12]+Ex∼Pg[logPgPdate +Pθ2⋅12]=minGKL[Pdata ∥Pdata +Pg2]+KL[Pg∥Pdata +Pg2]−log4≥−log4
\begin{aligned}
\min _{G} \max _{D} V(D, G) &=\min _{G} \mathbb{E}_{x \sim P_{\text {date }}}\left[\log \frac{P_{\text {data }}}{\frac{P_{\text {tata }}+P_{g}}{2}} \cdot \frac{1}{2}\right]+\mathbb{E}_{x \sim P_{g}}\left[\log \frac{P_{g}}{\frac{P_{\text {date }}+P_{\theta}}{2}} \cdot \frac{1}{2}\right] \\
&=\min _{G} \mathrm{KL}\left[P_{\text {data }} \| \frac{P_{\text {data }}+P_{g}}{2}\right]+\mathrm{KL}\left[P_{g} \| \frac{P_{\text {data }}+P_{g}}{2}\right]-\log 4 \\
& \geq-\log 4
\end{aligned}
GminDmaxV(D,G)=GminEx∼Pdate [log2Ptata +PgPdata ⋅21]+Ex∼Pg[log2Pdate +PθPg⋅21]=GminKL[Pdata ∥2Pdata +Pg]+KL[Pg∥2Pdata +Pg]−log4≥−log4
当且仪当 Pdata =Pg=Pata +P92P_{\text {data }}=P_{g}=\frac{P_{\text {ata }}+P_{9}}{2}Pdata =Pg=2Pata +P9 寺,等号成立。此时 ,Pg∗=Pd,Pd∗=12, P_{g}^{*}=P_{d}, P_{d}^{*}=\frac{1}{2},Pg∗=Pd,Pd∗=21。 很显然,大家想一想就知道,生成器模型分布最好当然是和数据分布是一样的,而此时判别器模型真的和假的都分不出,输出都是 12\frac{1}{2}21。

















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









