




 本文详细介绍Hadoop和Spark集群的快速搭建过程,包括环境配置、Zookeeper集群部署、Hadoop高可用集群安装及Spark集群配置。涵盖核心配置文件修改、环境变量设置、集群初始化步骤及历史服务器启动。
本文详细介绍Hadoop和Spark集群的快速搭建过程,包括环境配置、Zookeeper集群部署、Hadoop高可用集群安装及Spark集群配置。涵盖核心配置文件修改、环境变量设置、集群初始化步骤及历史服务器启动。
Hadoop&Spark集群快速搭建
基础环境
- Java JDK 1.8
- Scala 2.11.4
- 集群 IP 映射主机名
hdp4
hdp5
hdp6 - 配置服务器之间 SSH 免密登录
生成密钥: ssh-keygen 复制其他服务器公钥: ssh-copy-id ip
集群规划
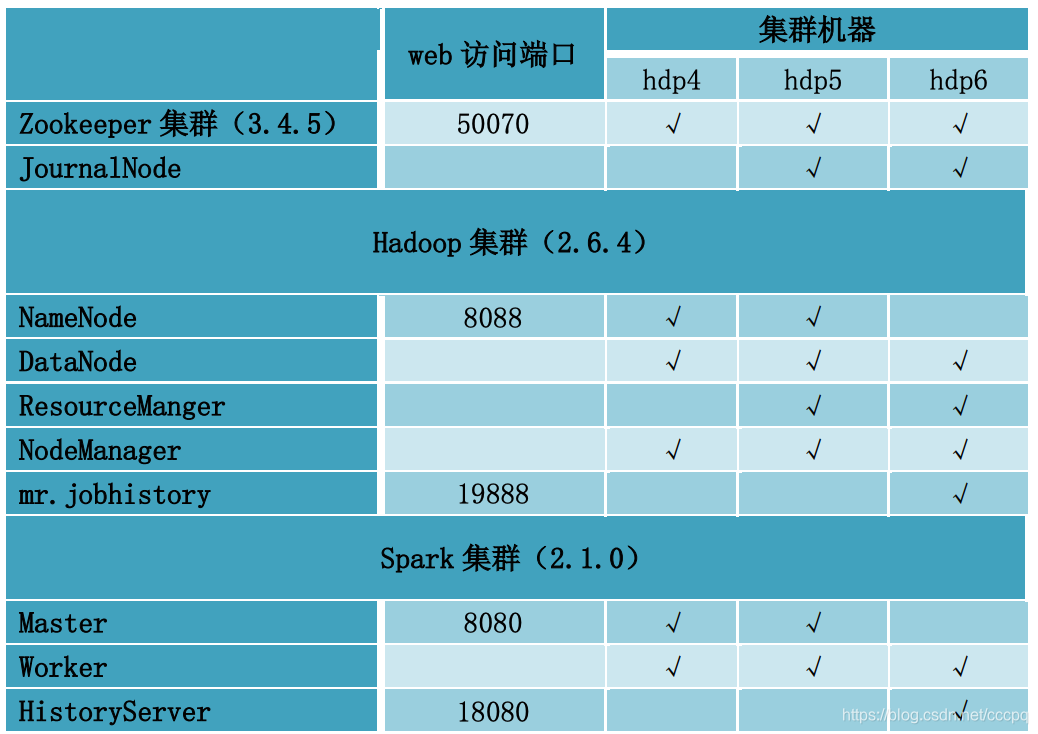
ZOOKEEPER 集群搭建
解压安装包文件到指定路径下
修改配置文件
```shell
cd conf/
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
(1) 修改 dataDir 路径
dataDir=/home/spark/data/zkdata
(2) 添加 server.id=主机名:心跳端口:
server.1=hdp4:2888:3888
server.2=hdp5:2888:3888
server.3=hdp6:2888:3888
### 文件分发个各个服务器
### 创建数据存储文件夹
```shell
mkdir /home/spark/data/zkdata
服务器 hdp4 指定 myid
echo 1 > myid
服务器 hdp5 指定 myid
echo 2 > myid
服务器 hdp6 指定 myid
echo 3 > myid
配置环境变量
vi .bashrc
export ZOOKEEPER_HOME=/home/spark/apps/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
HADOOP 高可用集群安装
解压安装包文件到 指定路径下
修改配置文件
修改 hadoo-env.sh
export JAVA_HOME= /usr/local/jdk1.7.0_67
```
修改 core-site.xml
```conf
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01/</value>
</property>
<!-- 指定 hadoop 工作目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/spark/data/hadoopdata/</value>
</property>
<!-- 指定 zookeeper 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp4:2181,hdp5:2181,hdp6:2181</value>
</property>
</configuration>
修改 mapred-site.xml
<configuration>
<!-- 指定 mr 框架为 yarn 方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 设置 mapreduce 的历史服务器地址和端口号 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp6:10020</value>
</property>
<!-- mapreduce 历史服务器的 web 访问地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp6:19888</value>
</property>
</configuration>
修改 yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定 RM 的 cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定 RM 的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定 RM 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp6</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp5</value>
</property>
<!-- 指定 zk 集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp4:2181,hdp5:2181,hdp6:2181</value>
</property>
<!-- 要运行 MapReduce 程序必须配置的附属服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启 YARN 集群的日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- YARN 集群的聚合日志最长保留时长 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定 resourcemanager 的状态信息存储在 zookeeper 集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
修改 slaves
hdp4
hdp5
hdp6
分发安装包到其他机器
配置环境变量
vi ~/.bashrc
export HADOOP_HOME= /home/spark/apps/hadoop-2.6.4 export
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
初始化集群
初始化 Zookeeper
启动:zkServer.sh start
检查启动是否正常:zkServer.sh status
在 zookeeper 节点上启动 journalnode 进程
分别在每个 zookeeper(也就是规划的三个 journalnode 节点,不一定跟zookeeper 节点一样)
节点上启动 journalnode 进程
hadoop-daemon.sh start journalnode
初始化 hadoop 集群
hadoop namenode –format
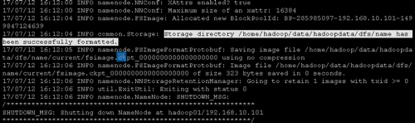
显示格式化成功
把生成的 hadoopdata 文件发送给第二个 namenode 的相同目录下
格式化 ZKFC
hdfs zkfc –formatZK

SPARK 集群安装
解压安装包文件到指定路径下
修改配置文件
修改 spark-env.sh 文件
export JAVA_HOME=/usr/java/jdk1.7.0_67
export SCALA_HOME=/usr/lib/scala-2.11.4
export HADOOP_HOME=/home/spark/apps/hadoop-2.6.4
export HADOOP_CONF_DIR=/home/spark/apps/hadoop-2.6.4/etc/hadoop
//配置 Spark 的高可用
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hdp4:2181,hdp5:2181,hdp6:2181
-Dspark.deploy.zookeeper.dir=/spark"
//配置 Spark 的日志功能
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=25
-Dspark.history.fs.logDirectory=hdfs://hadoop01/sparklog"
注意:启动 HistoryServer 时需要保证 hdfs://hadoop01/sparklog 这个 HDFS 的目录
创建好
修改 slaves 文件
mv slaves.template slaves
vi slaves
hdp4
hdp5
hdp6
配置环境变量
export SPARK_HOME=/home/spark/apps/spark-2.1.0
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
将配置文件分发个各个服务器
集群安装验证
启动HDFS
start-dfs.sh
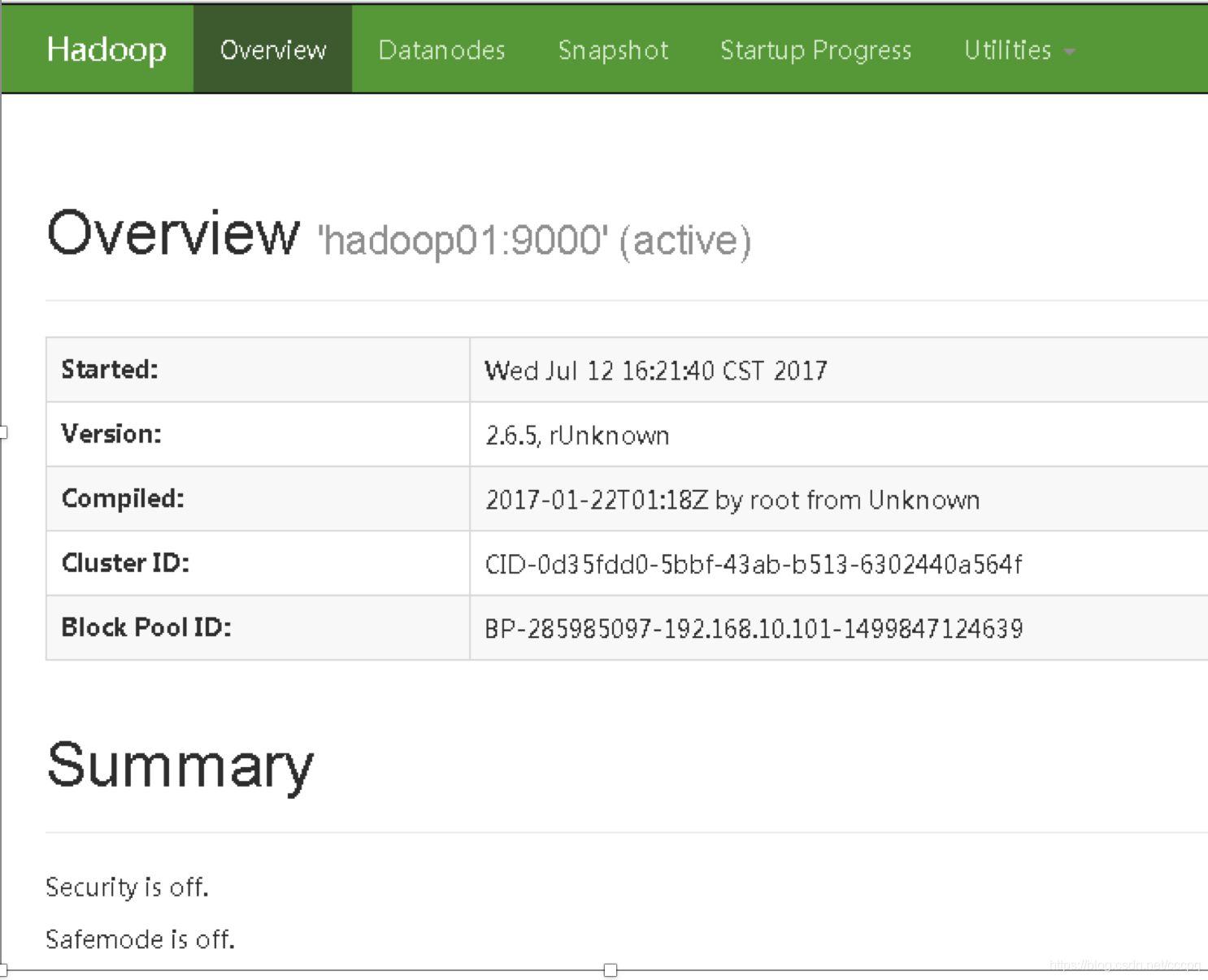
启动yarn集群
start-yarn.sh
启动rescourcemanger yarn-daemon.sh start resourcemanager
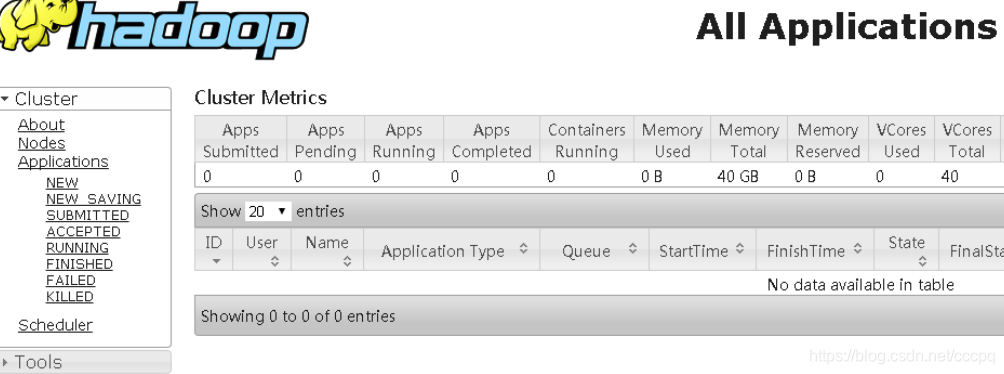
查看各节点状态
hdfs haadmin -getServiceState ip
yarn rmadmin -getServiceState ip
启动mapreduce 任务历史服务器
mr-jobhistory-daemon.sh start historyserver
启动后进程:4126 JobHistoryServer
web访问:http://ip:19888/

















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









