



 本文介绍了如何将CSV格式的数据导入Neo4j图数据库。首先,讲述了因Java版本冲突导致的启动问题,强调环境变量配置的重要性。然后详细说明了如何调整CSV数据格式,导入Person、Movie和关系表数据。最后,展示了使用Cypher语句创建节点和关系的过程,以及遇到的节点颜色显示问题。
本文介绍了如何将CSV格式的数据导入Neo4j图数据库。首先,讲述了因Java版本冲突导致的启动问题,强调环境变量配置的重要性。然后详细说明了如何调整CSV数据格式,导入Person、Movie和关系表数据。最后,展示了使用Cypher语句创建节点和关系的过程,以及遇到的节点颜色显示问题。
Neo4j图数据库
Neo4j是一个世界领先的开源图形数据库。 它是由Neo技术使用Java语言完全开发的。(emmm,就这样,想知道更多,大家去百度吧)
Neo4j数据库的安装
大家可以参看这个博主的哦,我就是看的他的:Neo4j安装及简单使用
但是吧,我自己也遇到了一些问题。
1、由于以前学习的时候,安装的java版本是8,但是现在我现在下载的是java14,所以就存在两个JDK。然后呢,就报错,说我的jdk版本太低(系统找到的是java8的jdk),但是用命令(java -version)查出来的是java14。经过各种百度,各种修改,发现问题就是出在了环境变量上,所以大家一定要好好的仔仔细细的配置环境变量。
(PS:问题其实没有解决,发现是环境变量问题,但是不管怎么改,就是错误。然而命运弄人,我去吃个饭,再次尝试启动,neo4j就可以跑起来了,感谢师兄,感谢上天)
说了这么多,重点就是:neo4j跑不起来的问题大概率是环境变量出错
开始下载服务器上面的表格(csv格式)
1、先导Person,Movie,这些节点数据表(因为导出的数据是类似Json格式的,所以需要大家手动调整数据格式。可以百度搜索EXCEL的分列功能,是个辛苦活,好好干,导出的数据会有一些数据少点东西,记得先挑出来哦)
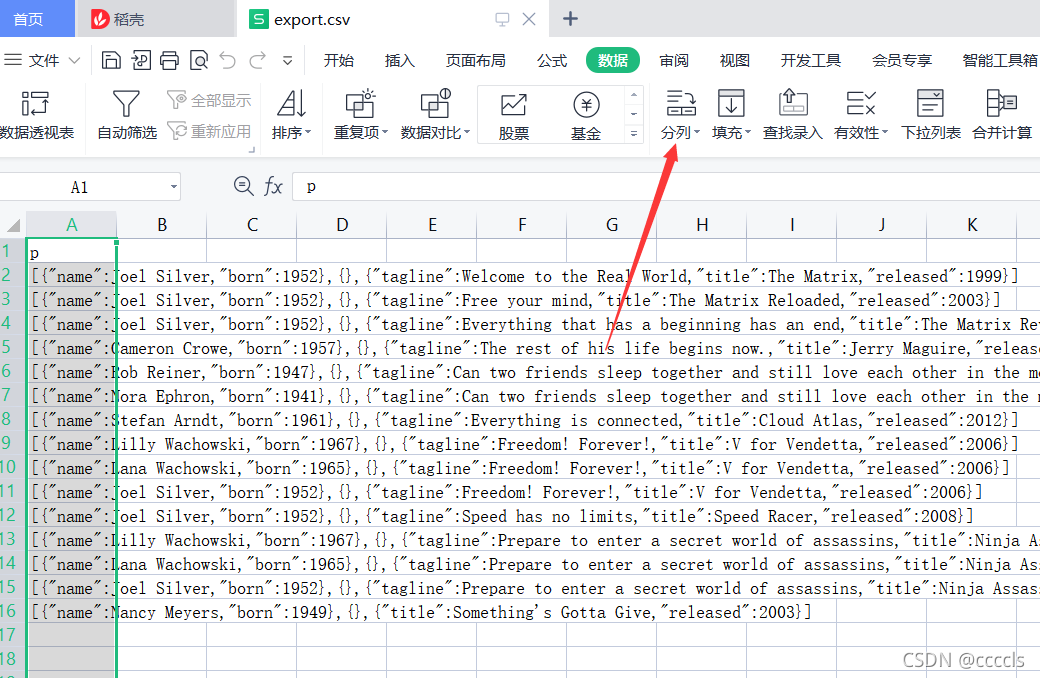
2、然后是Acted_in表这种关系表,参照上面的调整数据格式
csv格式的数据准备好了,接下来就是开始利用neo4j导入数据啦
重申:这只是我的一次尝试,不代表大家一定要这么做。(求生欲满满)
1、先用load语句导入关系表,举个栗子:
load csv from “file:///ACTOR_IN00.csv” as line
create (n:ACTOR {name:line[0],born:line[1],role:line[2],ACTOR_IN00:“ACTOR_IN00”,tagline:line[3],title:line[4] ,released:line[5]})
看清哦我是创建的实体节点,我把它视为一种演员,表述为某某演员在某某电影里面扮演了某某角色
导入之后,你会看到很多单独的节点
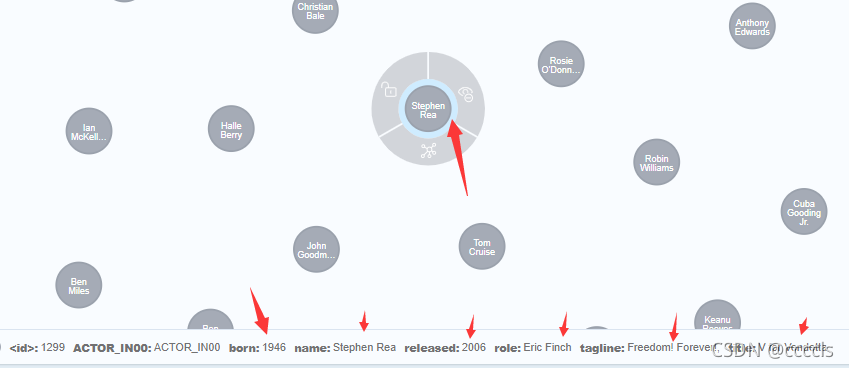
2、同样利用load导入Person,Movie数据
load csv from “file:///Persone00.csv” as line
create (:Person00 {name:line[0],born:line[1]})

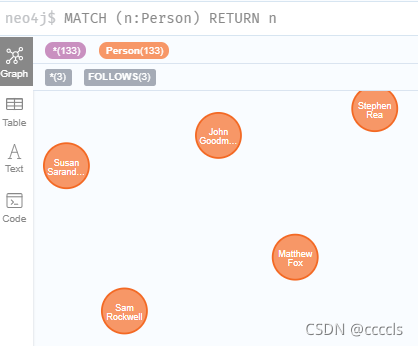
Movie类似,自己动手吧,嘿嘿(我懒)
3、接下来就是利用Create创建练习,使得Person节点和Movie串联起来。是时候用到第一步创建的ACTOR节点了
match(n:Person00),(m:Movie00),(r:ACTOR)
where n.name = r.name AND n.born = r.born AND m.title = r.title
create (n)-[:ACEDR_IN00]->(m)
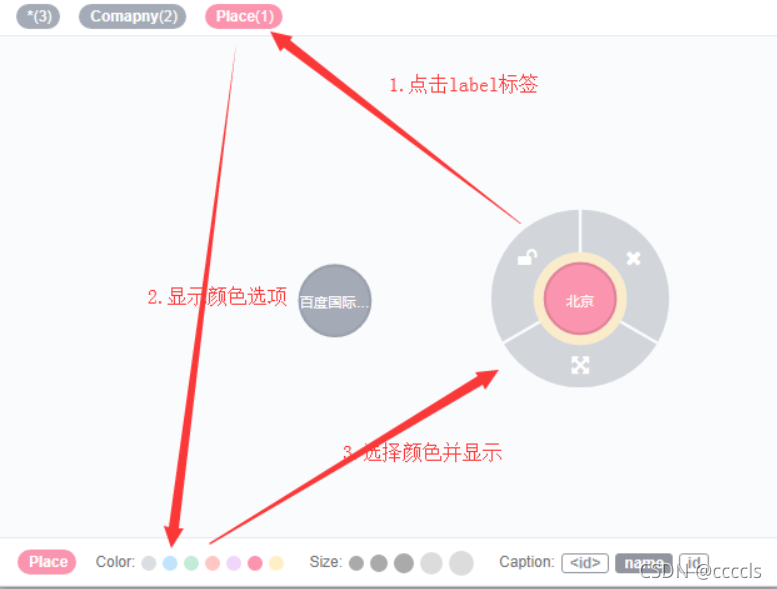
看效果(我也不知道为什么我的都是灰色的,先留着这个问题,待会儿去解决,先记录下)

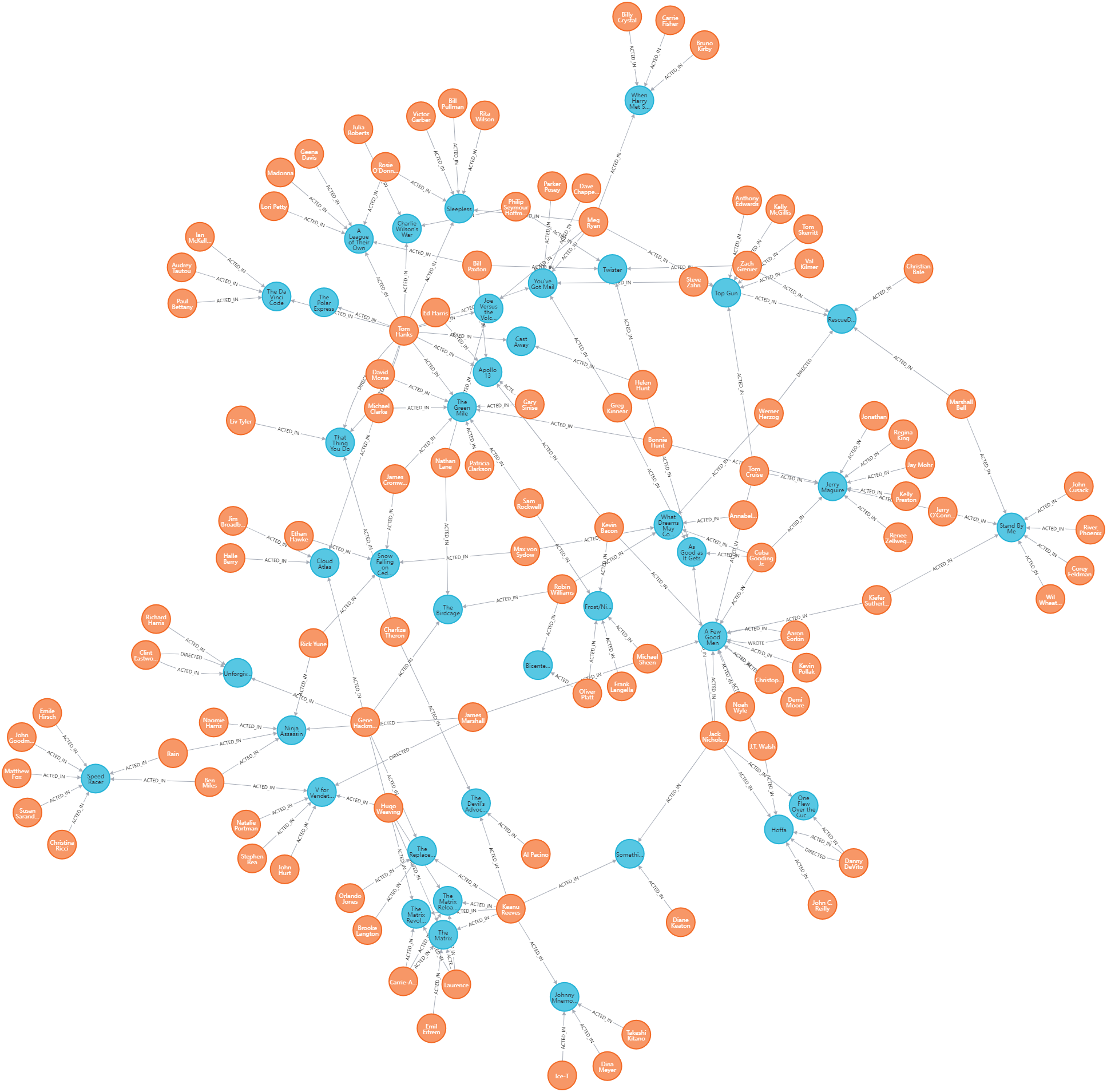
还有其他的关系,一样的道理,快去尝试吧。
都是灰色:可以自己去设置一下啊

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









