 Monkey使用方法及常见问题
Monkey使用方法及常见问题





 本文介绍了Monkey的使用方法,包括执行命令前需安装adb及配置path,给出了具体执行命令及参数含义。还说明了下载crashmonkey4androd包、解压文件、执行命令的步骤,以及结果保存目录。此外,提及了启动文件和执行命令时出现的问题。
本文介绍了Monkey的使用方法,包括执行命令前需安装adb及配置path,给出了具体执行命令及参数含义。还说明了下载crashmonkey4androd包、解压文件、执行命令的步骤,以及结果保存目录。此外,提及了启动文件和执行命令时出现的问题。
Monkey使用
参考学习地址:http://blog.youkuaiyun.com/itfootball/article/details/46361455
(执行之前,先安装adb及配置adb的path)
-
执行命令
run cts --plan Monkey --p com.activity --a com.eg.android.packagename --v 6000
p :测试app的包名.
a :测试app的主activity,
如果正确设置上面两项,Monkey会针对上面-p指定的应用测试,一直保持在该应用界面.
-
下载crashmonkey4androd包
地址:https://github.com/DoctorQ/CrashMonkey4Androd_bin#crashmonkey4androd_bin
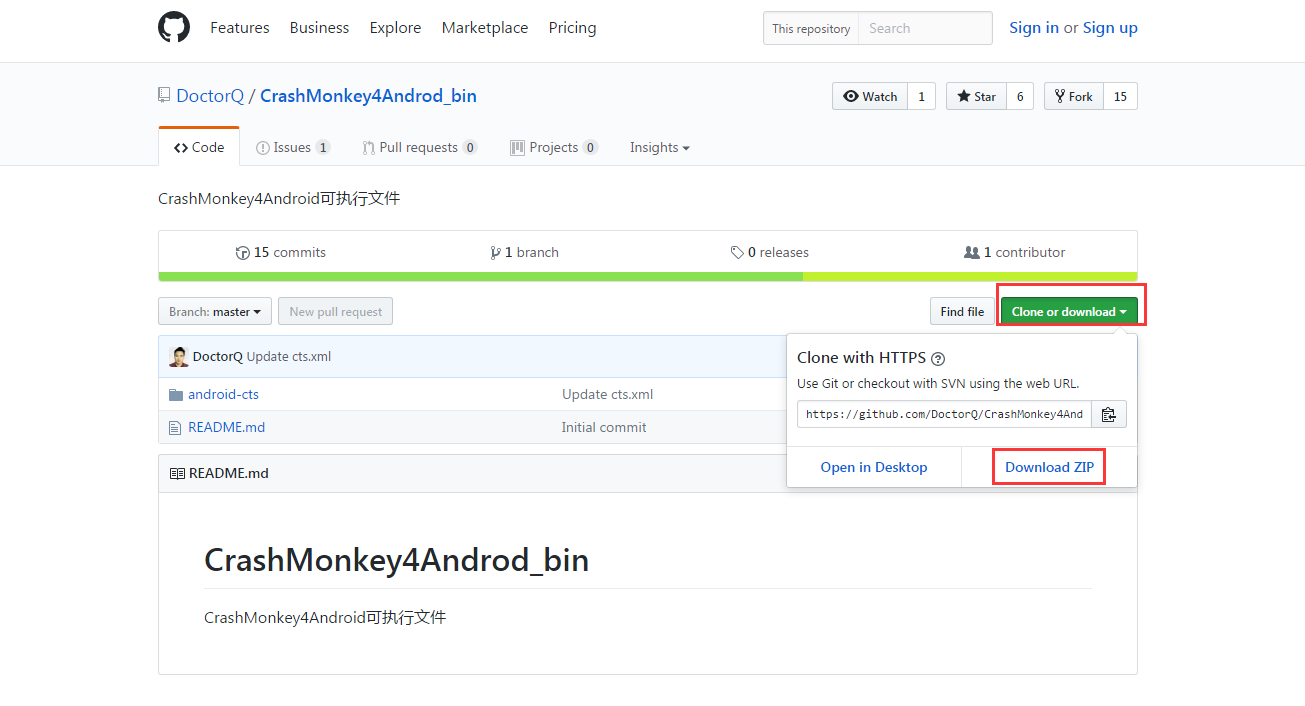
2.解压文件,找到tools目录下的cts-tradefed.bat文件,双击会出现终端窗口
3.执行命令
run cts --plan Monkey --p xxx --a com.xxx.xxx --v 50
结果\repository目录下 logs和results目录
1. logs:保存测试过程中的截图和log信息
2. results: 保存测试报告
问题:
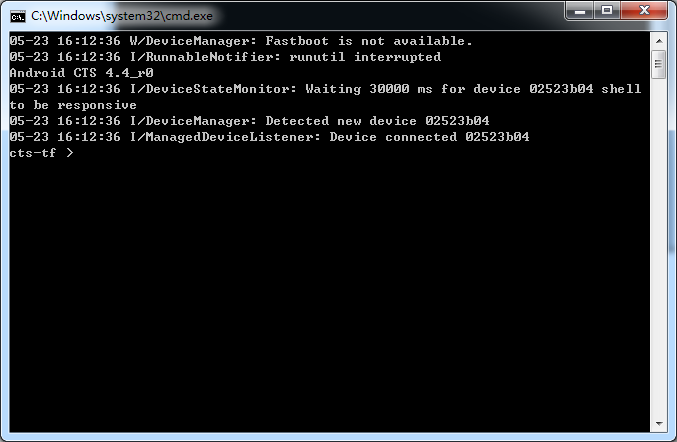
- 启动cts-tradefed.bat文件,显示找不到fastboot,但是可以执行命令
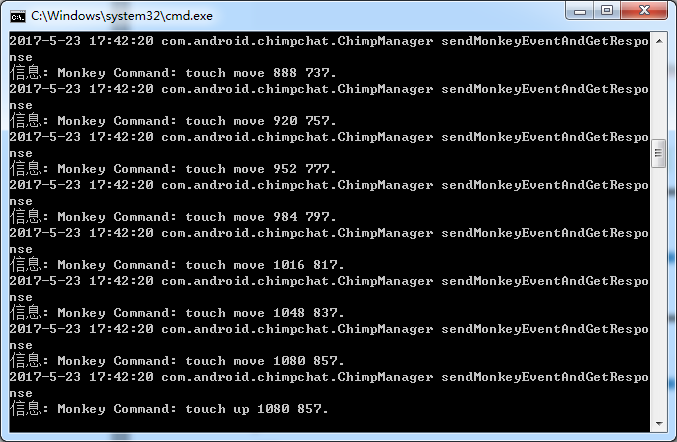
2.执行命令后会出现这个问题,然后会继续跑

















 6534
6534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









