




 本文深入剖析了一个融合光流和图优化的动态SLAM系统,系统输入包括RGB图像、深度图、像素级实例分割和光流。通过对静态背景的特征追踪和相机位姿估计,结合图优化技术,实现动态物体位姿和轨迹的精确估计。文中详细阐述了位姿表示、3D点坐标转换、物体运动以及相机和物体运动的估计方法,特别强调了光流在稳定追踪和联合估计中的作用。最后,通过局部和全局批量优化,构建并更新局部和全局地图,确保长期追踪的稳定性。该系统在处理遮挡和非直接遮挡情况时表现出良好的鲁棒性,并能实现对物体运动的全局精确化。
本文深入剖析了一个融合光流和图优化的动态SLAM系统,系统输入包括RGB图像、深度图、像素级实例分割和光流。通过对静态背景的特征追踪和相机位姿估计,结合图优化技术,实现动态物体位姿和轨迹的精确估计。文中详细阐述了位姿表示、3D点坐标转换、物体运动以及相机和物体运动的估计方法,特别强调了光流在稳定追踪和联合估计中的作用。最后,通过局部和全局批量优化,构建并更新局部和全局地图,确保长期追踪的稳定性。该系统在处理遮挡和非直接遮挡情况时表现出良好的鲁棒性,并能实现对物体运动的全局精确化。
一.整体系统
先建立一个感性认识:
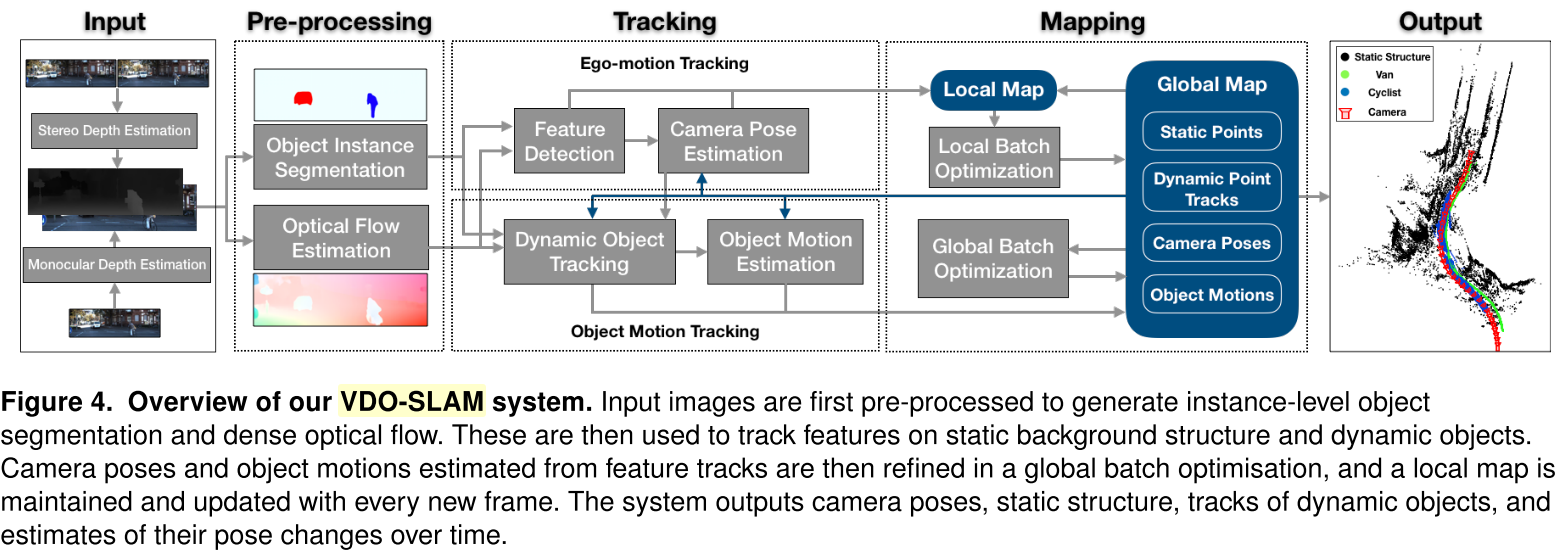 系统的输入:双目或单目的rgb图和深度图,像素级实例分割的结果,以及稠密光流。
系统的输入:双目或单目的rgb图和深度图,像素级实例分割的结果,以及稠密光流。
- 对静态背景进行特征追踪,使用求出的相机pose来求解运动物体pose并对其运动进行估计;
- 用图优化使估计结果更加准确。在这个过程中会维护局部地图,并且随着每一个新帧都会更新。
最终系统的输出是:相机位姿与轨迹,动态物体位姿与轨迹,运动物体的速度,静态地图
二. 几何基础
1. 位姿表示
0Xk∈SE(3)^{0}X_k \in SE(3)0Xk∈SE(3) : 机器人/相机的3D位姿,0为世界坐标系,k是时间戳,也可以理解为是相机坐标系到世界坐标系下的转换矩阵
0Lk∈SE(3)^{0}L_k \in SE(3)0Lk∈SE(3) : 物体的3D位姿,即物体坐标系到世界坐标系下的转换矩阵
2. 3D点的坐标系转换
一个世界坐标系中的第i个3D点(齐次坐标)转换到某一帧k的相机坐标系:
Xkmki=0Xk−1∗ 0mki (1)^{X_k}m^{i}_{k}=^{0}X_k^{-1}* \ ^{0}m_{k}^{i} \ \ \ (1)Xkmki=0Xk−1∗ 0mki (1)
再把这个点从相机坐标系乘以内参矩阵转换到像素坐标系,得到齐次坐标:
Ikpki=π(Xkmki)=K∗ Xkmki (2)^{I_k}p^{i}_k=\pi(^{X_k}m_k^{i})=K* \ ^{X_k}m_k^i \ \ \ (2)Ikpki=π(Xkmki)=K∗ Xkmki (2)
相机和环境中物体的运动都会产生2D光流,可以把从第k-1帧图像到第k帧图像的像素运动写成一个位移向量,这就是光流:
Ikϕi=Ikp~ki−Ik−1pk−1i (3)^{I_k}\phi^i = ^{I_k}\widetilde{p}_k^i - ^{I_{k-1}}p_{k-1}^i\ \ \ (3)Ikϕi=Ikp
ki−Ik−1pk−1i (3)
相当于说,我们可以得到第k-1帧第i点的像素坐标,然后可以通过光流法找到第k帧中对应的像素点(带波浪线的项)。这篇论文就是使用光流法对相邻帧进行追踪。
3. 物体和3D点的运动
物体在相邻帧之间的位姿变换,可以用下式表示:
k−1Lk−1Hk=0Lk−1−1∗ 0Lk (4)^{L_{k-1}}_{k-1}H_k= ^{0}L_{k-1}^{-1} * \ ^{0}L_k \ \ \ (4)k−1Lk−1Hk=0Lk−1−1∗ 0Lk (4)
个人理解:0Lk^{0}L_k0Lk是第k帧时物体坐标系到世界坐标系下的转换矩阵;而0Lk−1−1^{0}L_{k-1}^{-1}0Lk−1−1是第k-1帧时世界坐标系到物体坐标系的变换矩阵。所以求出的就是从第k帧到第k-1帧物体位姿的变换矩阵
在这个物体(刚体)上的点坐标系变换就如下,表示第k帧时这个点从世界坐标系转到这个物体坐标系的位置:
Lkmki=0Lk−1∗ 0mki (5)^{L_k}m_k^i = ^0L_k^{-1} * \ ^0m_k^i \ \ \ (5)Lkmki=0Lk−1∗ 0mki (5)
那么,此时我们就可以得到物体上某一点在世界坐标系的位置和该点在这个物体坐标系位置的坐标转换关系(把式4代入式5):
0mki=0Lk∗Lkmki=0Lk−1∗k−1Lk−1Hk∗Lkmki (6)^0m^i_k = ^0L_k * ^{L_k}m_k^i = ^0L_{k-1} * ^{L_{k-1}}_{k-1}H_k* ^{L_k} m_k^i \ \ \ (6)0mki=0Lk∗Lkmki=0Lk−1∗k−1Lk−1Hk∗Lkmki (6)
注意:对于刚体来说,刚体上的某一点相对这个刚体坐标系(以刚体上某一点作为坐标系原点)是固定的,也就是说Lkmki^{L_k}m_k^iLkmki在物体坐标系的坐标为定值Lmi^Lm^iLmi,不管时间戳是多少,都不会变。所以说式6的最后一项为:(这里的n可以是任何整数)
Lkmki=Lmi=0Lk−1∗0mki=0Lk+n−1∗0mk+ni (7)^{L_k}m_k^i =^Lm^i=^0L_k^{-1}*^0m_k^i=^{0}L_{k+n}^{-1} *^0m_{k+n}^i \ \ (7) Lkmki=Lmi=0Lk−1∗0mki</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









