




 本文深入探讨决策树模型,一种能够有效描述非线性关系的机器学习算法。通过案例分析,展示了决策树如何处理复杂的数据特征,如年龄与死亡率之间的非线性关系,并通过编程实践,使用泰坦尼克号乘客数据进行模型训练与评估。
本文深入探讨决策树模型,一种能够有效描述非线性关系的机器学习算法。通过案例分析,展示了决策树如何处理复杂的数据特征,如年龄与死亡率之间的非线性关系,并通过编程实践,使用泰坦尼克号乘客数据进行模型训练与评估。
模型介绍
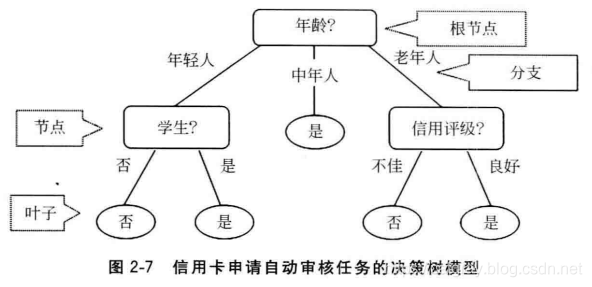
逻辑斯蒂回归和支持向量机模型,都在某种程度上要求被学习的数据特征和目标之间遵照线性假设。然而,许多现实场景下,这种假设是不存在的。比如,如果要借由一个人的年龄来预测患流感的死亡率。如果采用线性模型假设,那么只有两种情况:年龄越大死亡率越高或年龄越小死亡率越高。而实际上,年龄与因流感而死亡之间不存在线性关系。在机器学习模型中,决策树就是描述这种非线性关系的不二之选。图2-7是一个信用卡申请自动审核任务的决策树模型:
- 决策树节点(node)代表数据特征:如年龄(age)、身份是否是学生(student)、信用评级(credict_rating)等;
- 每个节点下的分支代表对应特征值得分类,如年龄包括年轻人、中年人、以及老年人,身份区分是否是学生等;
- 决策树得所有叶子节点(leaf)则显示模型得决策结果。
编程实践
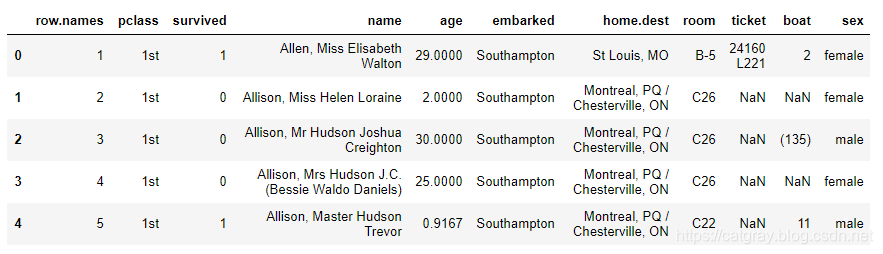
本次实践使用泰坦尼克号的乘客数据
import pandas as pd
titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#查看数据的前几行
titanic.head()
#查看数据的各项统计信息
titanic.info()

X=titanic[['pclass','age','sex']]
y=titanic['survived']
X.fillna(X['age'].mean(),inplace=True)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)
from sklearn.feature_extraction import DictVectorizer
vec= DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='record'))
print(vec.feature_names_)
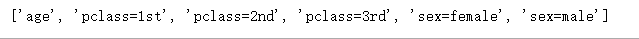
X_test=vec.transform(X_test.to_dict(orient='record'))
from sklearn.tree import DecisionTreeClassifier
dtc= DecisionTreeClassifier()
dtc.fit(X_train,y_train)
y_predict=dtc.predict(X_test)
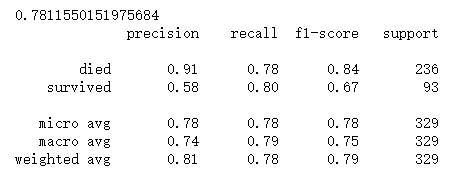
from sklearn.metrics import classification_report
print(dtc.score(X_test,y_test))
print(classification_report(y_predict,y_test,target_names=['died','survived']))
特点分析
决策树的推断逻辑非常直观,具有清晰的可解释性,也方便了模型的可视化。这些特性同时也保证在使用决策树模型时,无需考虑对数据的量化甚至标准化。与K近邻模型不同,决策树属于有参数模型,需要花费更多实践在训练集上。

















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









