



 在使用ab进行压力测试时,遇到并发不高但频繁出现Failedrequests的情况,深入分析发现是由于服务B所在的服务器TCP半连接队列丢包所致。本文详细介绍了问题的排查过程,包括如何定位到TCP层面的问题,以及如何通过调整服务器配置来解决这一问题。
在使用ab进行压力测试时,遇到并发不高但频繁出现Failedrequests的情况,深入分析发现是由于服务B所在的服务器TCP半连接队列丢包所致。本文详细介绍了问题的排查过程,包括如何定位到TCP层面的问题,以及如何通过调整服务器配置来解决这一问题。
阅读本文大概需要 3 分钟。
用ab压测服务A (服务A会调用服务B) 的时候,并发不大的情况下,经常出现Failed requests, 最终发现原因是服务B所在服务器tcp半连接队列丢包,导致部分tcp连接不成功,最终请求失败,这里还原下整个过程分析下 (以下将服务A所在服务器称为客户端,服务B所在服务为服务器端)
问题现象
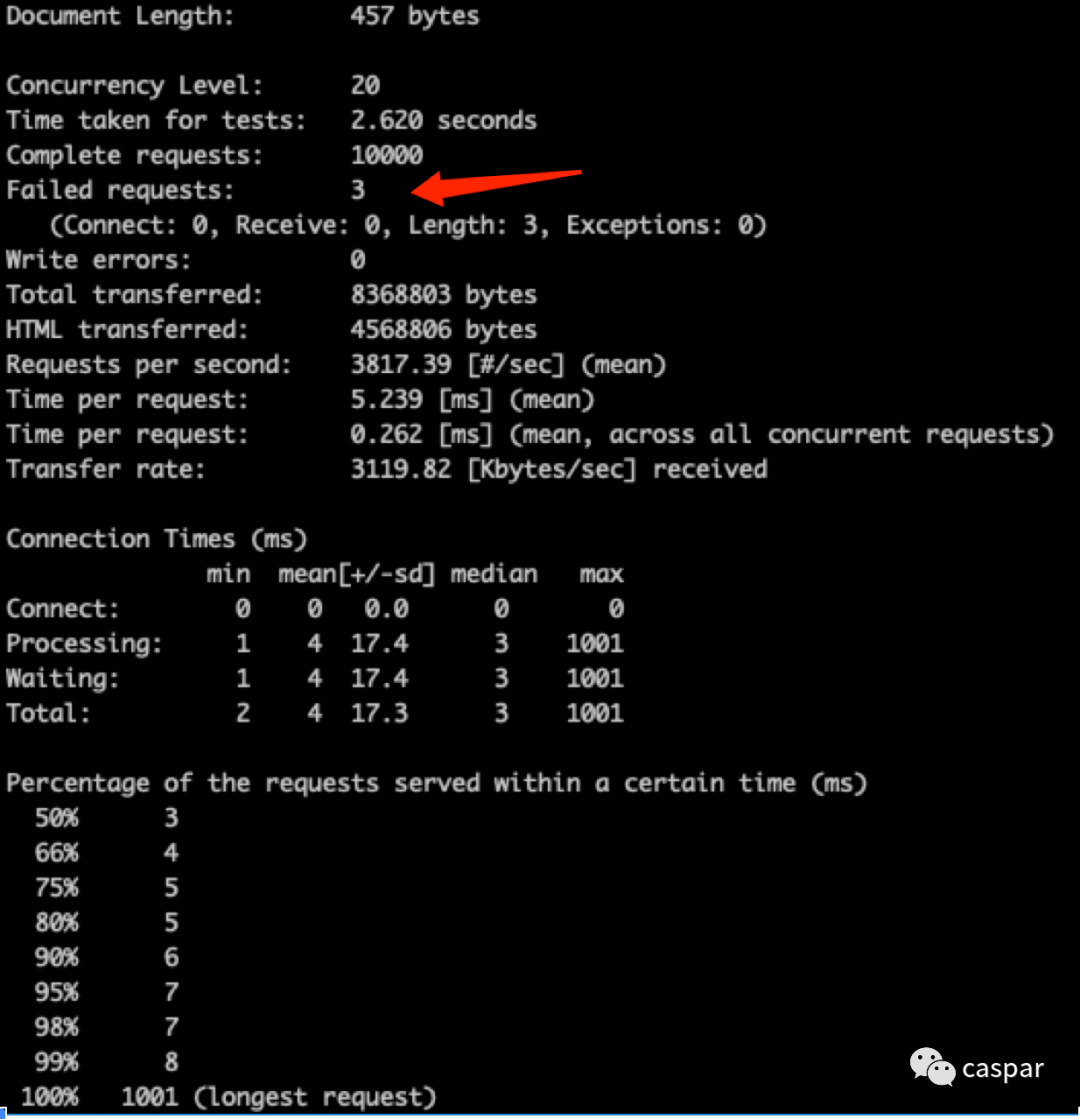
ab 压测出现Failed requests
分析过程
1.客户端查看错误日志,看到错误原因
net/http: request canceled while waiting for connection
2.服务端根据客户端trace_id查找请求,日志里面找不到,怀疑是tcp层面的问题,也就是连接不成功,还没有进入应用层
3.服务器端查看tcp丢包情况,发现前后两次tcp半连接队列丢包个数相减正好是ab Failed requests个数3
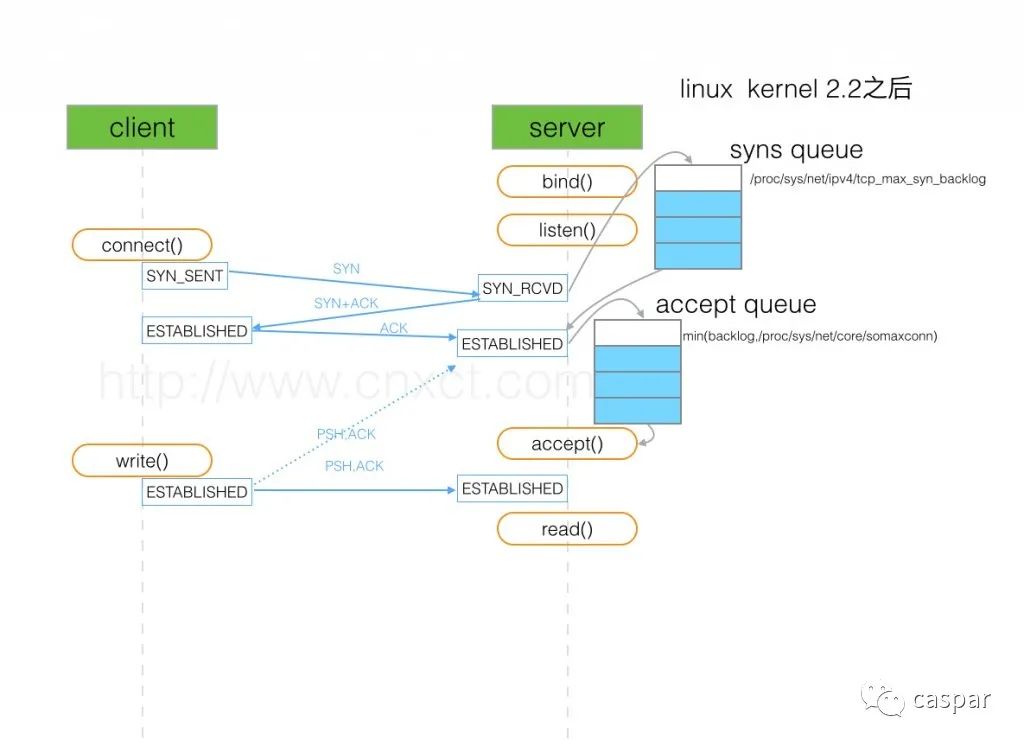
# 查看半连接队列 (syns queue) 溢出
netstat -s | grep drop
# 查看全连接队列 (accept queue) 溢出
netstat -s | grep TCPBacklogDrop

4. 查看丢包原因,服务器端查看半连接队列(syns queue)大小,排除不是设置得过小的原因
cat /etc/sysctl.conf | grep net.ipv4.tcp_max_syn_backlog
5. 查看丢包的原因,通过查阅资料,服务器同时打开了tcp_timestamps + tcp_tw_recycle时,就会检查时间戳;如果对方发来的包的时间戳是乱跳的或者说时间戳是滞后的,这样服务器肯定不会回复,所以服务器就把带了“倒退”的时间戳的包当作是“recycle的tw连接的重传数据,不是新的请求,于是丢掉客户端的syn请求不回复
解决办法
vim /etc/sysctl.conf
修改 net.ipv4.tcp_tw_recycle = 0 或者 net.ipv4.tcp_timestamps = 0
然后sysctl -p 重启
参考
https://blog.youkuaiyun.com/pyxllq/article/details/80351827
https://blog.youkuaiyun.com/GV7lZB0y87u7C/article/details/79358193
蔡蔡技术记


















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









