







欢迎关注我的优快云:https://spike.blog.youkuaiyun.com/
本文地址:https://spike.blog.youkuaiyun.com/article/details/131591887
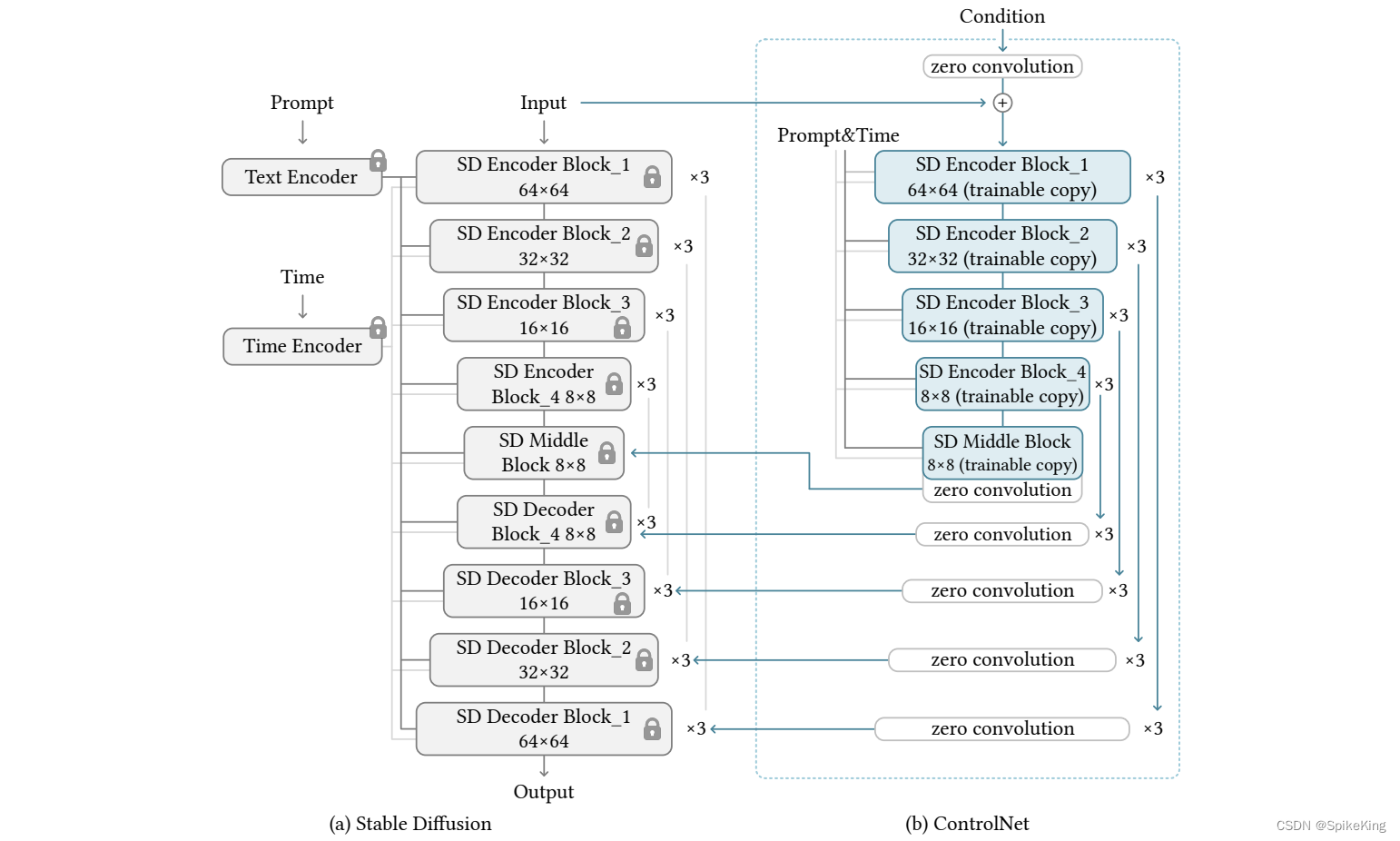
论文:Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet 是神经网络结构,用于控制预训练的大型扩散模型,以支持额外的输入条件。ControlNet 以端到端的方式学习任务特定的条件,即使训练数据集很小(< 50k),学习也是稳健的。此外,训练一个 ControlNet 和微调一个扩散模型一样快,而且,模型可以在个人设备上训练。或者,如果有强大的计算集群可用,模型可以扩展到大量(百万到十亿)的数据。Stable DIffusion 这样的大型扩散模型可以用 ControlNets 来增强,以实现条件输入,如边缘图、分割图、关键点等。这可能丰富了控制大型扩散模型的方法,并进一步促进相关应用。Stable DIffusion 迈向工业化的关键模型 ControlNet 技术,使得图像效果更加稳定。
1. 配置 ControlNet 扩展
ControlNet模型 - Huggingface: https://huggingface.co/lllyasviel/ControlNet
5 个重要的控制模型:
- OpenPose:动作姿势
- Depth:深度
- Canny:边缘检测 (线稿)
- Softedge:柔和边缘
- Scribble:涂鸦乱画
下载模型,参考,常用包括 14 个模型:
control_sd15_openpose.pth: https://huggingface.co/lllyasviel/ControlNet/blob/main/models/control_sd15_openpose.pth
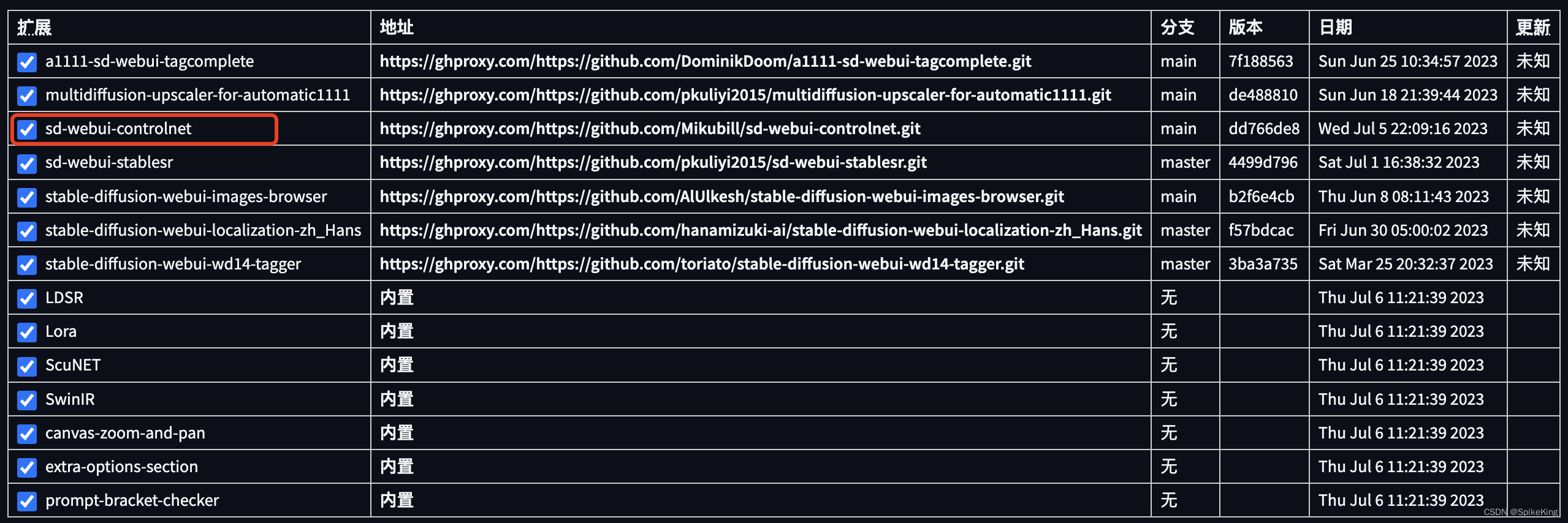
下载扩展,参考:AICG - Stable Diffusion 的扩展插件 (Extensions) 的配置与使用
- 需要配置更新源:https://gitee.com/akegarasu/sd-webui-extensions/raw/master/index.json
安装扩展选择,搜索 ControlNet,选择 sd-webui-controlnet 进行安装,重启即可。安装成功如下:
相关日志:
2023-07-06 19:37:27,089 - ControlNet - INFO - ControlNet v1.1.231
ControlNet preprocessor location: stable_diffusion/stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/downloads
2023-07-06 19:37:27,340 - ControlNet - INFO - ControlNet v1.1.231
Image Browser: ImageReward is not installed, cannot be used. # 无关紧要
注意,需要检查 ControlNet 是否安装成功,如果失败,则需要删除,并重新安装。
ControlNet 作为插件,在软件的下方插件处显示,即:
预测模型,需要存储至 stable-diffusion-webui\extensions\sd-webui-controlnet\models,其中,包含同名的 yaml 文件。常用包括 14 个模型:
control_v11e_sd15_ip2p.pth
control_v11e_sd15_shuffle.pth
control_v11f1e_sd15_tile.pth
control_v11f1p_sd15_depth.pth
control_v11p_sd15_canny.pth
control_v11p_sd15_inpaint.pth
control_v11p_sd15_lineart.pth
control_v11p_sd15_mlsd.pth
control_v11p_sd15_normalbae.pth
control_v11p_sd15_openpose.pth
control_v11p_sd15_scribble.pth
control_v11p_sd15_seg.pth
control_v11p_sd15_softedge.pth
control_v11p_sd15s2_lineart_anime.pth
在 ControlNet 插件中,除了模型,尺寸占比最重的就是 annotator/downloads 的文件夹,大约 6.1 G。如果下载失败,请手动下载,即:
hed/
leres/
lineart/
lineart_anime/
manga_line/
midas/
mlsd/
normal_bae/
oneformer/
openpose/
pidinet/
uniformer/
zoedepth/
2. ControlNet 的 OpenPose 功能
2.1 配置基础模型
基础模型 AbyssOrangeMix3A1B:
- AbyssOrangeMix2 - SFW/Soft NSFW
- 最新版本:v3,即 AOM3A1B_orangemixs.safetensors,这个版本作者推荐 (This model is my latest favorite)
下载模型:
cd stable-diffusion-webui/models/Stable-diffusion
bypy downfile /stable_diffusion/base_models/AOM3A1B_orangemixs.safetensors AOM3A1B_orangemixs.safetensors
提示词:
(sfw:1.2), absurdres, 1girl, ocean,white dress, long sleeves,light smile,
Negative prompt: nsfw, (worst quality:1.2), (low quality:1.2), (lowres:1.1),(monochrome:1.1),(greyscale),multiple views, comic,sketch,animal ears, pointy ears, blurry, transparent,see through,cleavage,bad hands,
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2586500704, Size: 512x768, Model hash: 5493a0ec49, Model: AOM3A1B_orangemixs, Version: v1.4.0
示例图像:

2.2 使用 OpenPose 功能
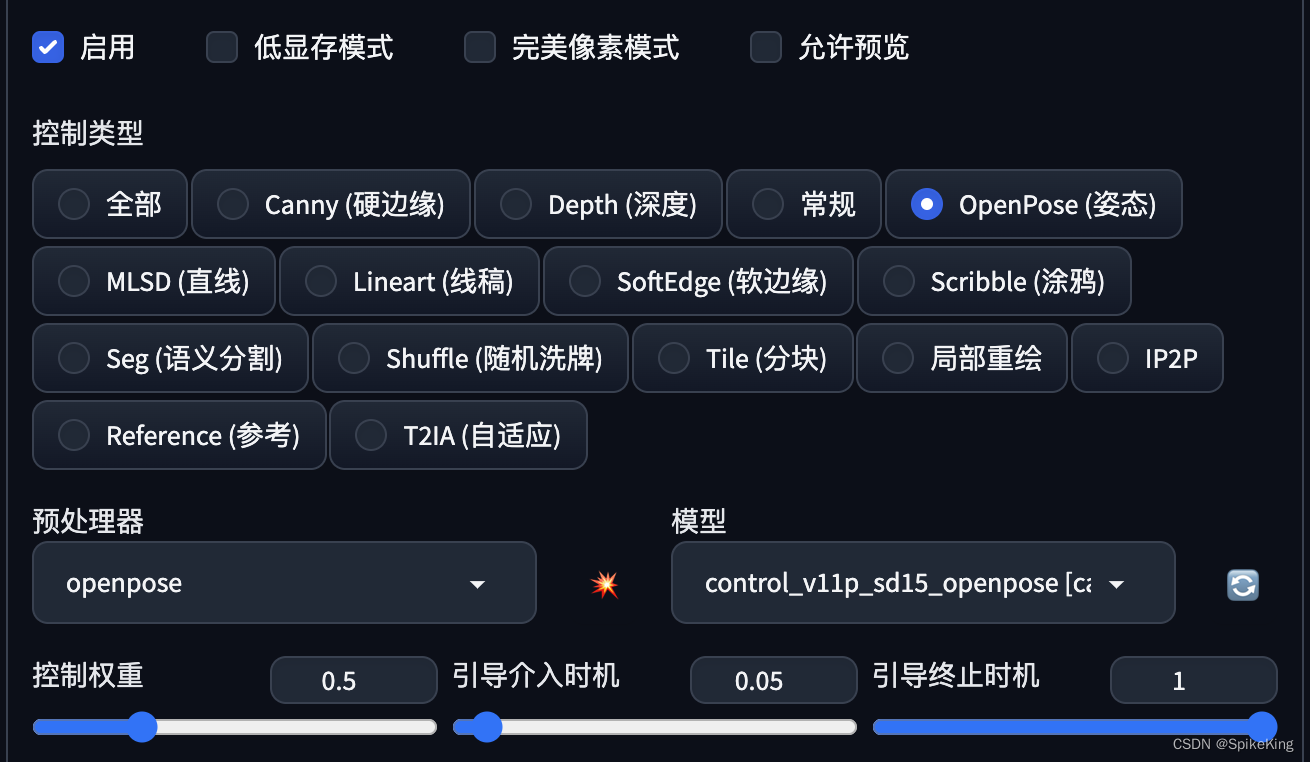
添加 ControlNet,固定姿势之后的效果:
- 选择
启用 - 选择
OpenPose - 选择预处理器
OpenPose - 选择模型:
control_v11p_sd15_openopenpose 控制权重与引导介入时机,控制 Control Net 的影响,可以适当调低,例如0.5或0.05。- 其余选择默认
即可:
添加姿势引导图,如下:

输出相同姿势的示例图像,如下:
在 AbyssOrangeMix2 模型中,在抬起手臂时,自动生成太阳帽,然而,提示词中并没有太阳帽。是 AbyssOrangeMix2 模型的问题,而不是 ControlNet OpenPose 生成图像的问题。

2.3 测试其他模型输出
测试其他模型,并未出现添加 太阳帽 的情况,例如 墨幽人造人_v1010_完整版:
Prompt:
(sfw:1.2), absurdres, 1girl, ocean,white dress, long sleeves,light smile,
Negative prompt: EasyNegative, (badhandv4:1.25),ng_deepnegative_v1_75t,
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2586500704, Face restoration: CodeFormer, Size: 512x768, Model hash: 6a226dd292, Model: 墨幽人造人_v1010_完整版, ControlNet 0: "preprocessor: openpose_full, model: control_v11p_sd15_openpose [cab727d4], weight: 0.5, starting/ending: (0.05, 1), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (512, -1, -1)", Version: v1.4.0
Used embeddings: EasyNegative [119b], badhandv4 [dba1], ng_deepnegative_v1_75t [1a3e]
示例图像:

使用 ControlNet OpenPose 增加姿势约束的示例图像,姿势一致,如下:

2.4 使用 Pose 图
同时,点击红色小点(Run Preprocessor),即可生成,姿势 (Pose) 图,保存之后,可以复用,即:

即:
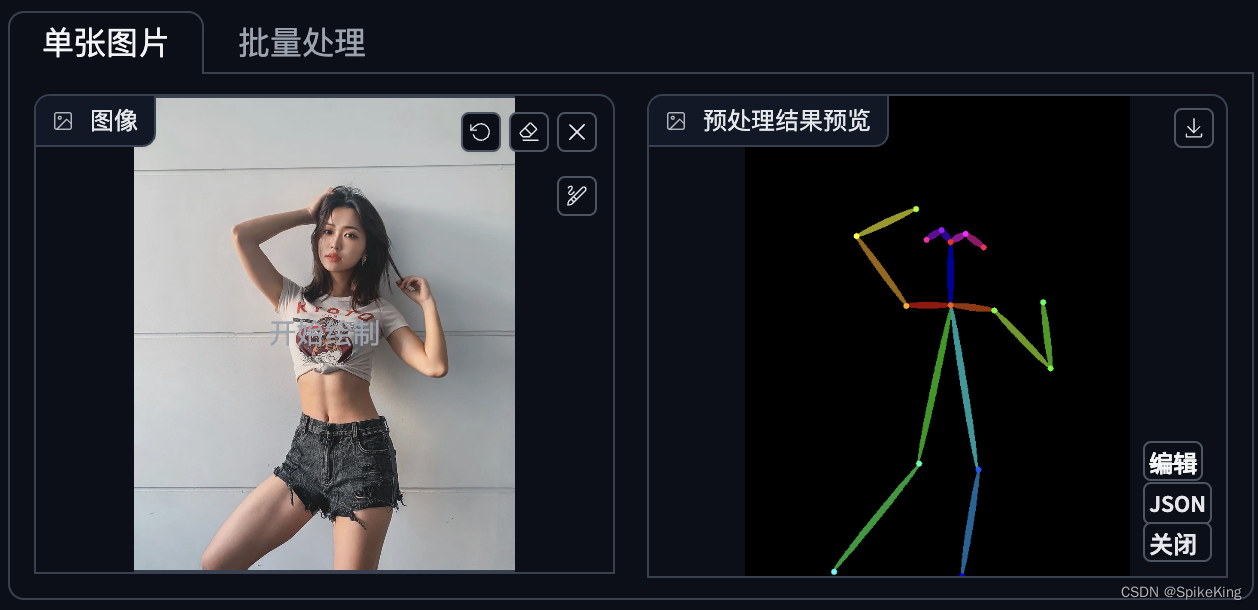
在使用姿势图时,需要关闭 预处理器,但是,要保留所使用的模型,才能运行,使用姿态图的效果,与使用原图的效果,相同,即:

3. 其他
3.1 OrangeMixs 模型
下载地址: AOM3A1B_orangemixs.safetensors,这个版本作者推荐 (This model is my latest favorite),动漫风格为主。
- Civitai: AbyssOrangeMix2 - SFW/Soft NSFW
- Liblibai: https://www.liblibai.com/modelinfo/e1a7c4c0e169321ce8441964951e56e4
absurdres, (1girl), ocean, white dress, sun hat, smile, (realistic:0.75), (waving:0.9)
Negative prompt: nsfw, (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature,badhandv4,
Steps: 40, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 2434999601, Size: 1024x512, Model hash: 5493a0ec49, Model: AOM3A1B_orangemixs, Version: v1.4.0
v2 版本,liblibai下载:
wget https://liblibai-online.liblibai.com/models/57d684f2ceff9b12f1439bffa2b13d5ece21a19a.safetensors -O NSFW_AbyssOrangeMix2_sfw.safetensors
v2 和 v3 的差别,v3更加柔和,似乎添加特殊的滤镜。
AbyssOrangeMix (AOM) 是一种能够生成高质量、高度逼真的插图的 AI 模型,可以生成手工无法绘制的精美详细的插图,还可以用于多种目的,这使得它对于设计和艺术品非常有用。此外,还提供了一种无与伦比的新表达方式,可以生成多种类型的插图,以满足广泛的需求。我鼓励您使用 “Abyss” 来使您的设计和艺术品更加丰富和更高质量。
V3 Prompt:
- Negative prompts is As simple as possible is good.
- (worst quality, low quality:1.4)
- Using “3D” as a negative will result in a rough sketch style at the “sketch” level.
- Use with caution as it is a very strong prompt.
- How to avoid Real Face: (realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (abs, muscular, rib:1.0),
- How to avoid Bokeh: (depth of field, bokeh, blurry:1.4)
- How to remove mosaic: (censored, mosaic censoring, bar censor, convenient censoring, pointless censoring:1.0),
- How to remove blush: (blush, embarrassed, nose blush, light blush, full-face blush:1.4),
- How to remove NSFW effects: (trembling, motion lines, motion blur, emphasis lines:1.2),
- 🔰Basic negative prompts sample for Anime girl ↓
- v1: nsfw, (worst quality, low quality:1.4), (realistic, lip, nose, tooth, rouge, lipstick, eyeshadow:1.0), (dusty sunbeams:1.0), (abs, muscular, rib:1.0), (depth of field, bokeh, blurry:1.4),(motion lines, motion blur:1.4), (greyscale, monochrome:1.0), text, title, logo, signature
- v2: nsfw, (worst quality, low quality:1.4), (lip, nose, tooth, rouge, lipstick, eyeshadow:1.4), (blush:1.2), (jpeg artifacts:1.4), (depth of field, bokeh, blurry, film grain, chromatic aberration, lens flare:1.0), (1boy, abs, muscular, rib:1.0), greyscale, monochrome, dusty sunbeams, trembling, motion lines, motion blur, emphasis lines, text, title, logo, signature,
- Sampler: “DPM++ SDE Karras” is good Take your pick
- Steps:
- DPM++ SDE Karras: Test: 12~ ,illustration: 20~
- DPM++ 2M Karras: Test: 20~ ,illustration: 28~
- Clipskip: 1 or 2
- CFG: 8 (6~12)
- Upscaler :
- Detailed illust → Latenet (nearest-exact)
- Denoise strength: 0.5 (0.5~0.6)
- Simple upscale: Swin IR, ESRGAN, Remacri etc…
- Denoise strength: Can be set low. (0.35~0.6)
卡通图像,不要选择面部重绘,否则脸部模糊
3.2 BugFix & 参考
Bug1: 遇到 WARNING: Building wheel for fvcore failed: [Errno 28] No space left on device: '.cache/pip/wheels/f9'
即,表示安装pip文件.cache已满,可以重新指定目录。
参考:



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











