







 本文介绍了一种利用Python爬取拉勾网职位信息的方法,包括单页与多页信息抓取,并通过MongoDB存储数据。同时介绍了如何使用Fake UserAgent模块随机设置User-Agent来优化爬虫。
本文介绍了一种利用Python爬取拉勾网职位信息的方法,包括单页与多页信息抓取,并通过MongoDB存储数据。同时介绍了如何使用Fake UserAgent模块随机设置User-Agent来优化爬虫。
博客已经搬家到“捕获完成”:
https://www.v2python.com
伪装浏览器请求头
https://pypi.python.org/pypi/fake-useragent
安装
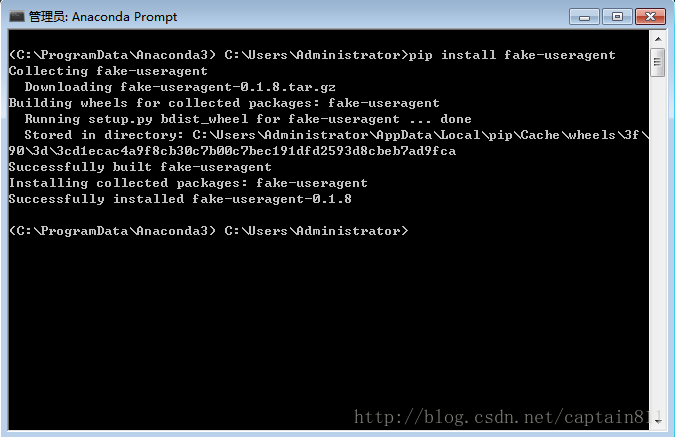
pip install fake-useragent
导入
from fake_useragent import UserAgent
ua = UserAgent()
具体使用
# and the best one, random via real world browser usage statistic
ua.random
第一种方法,只保存单页:
# post_lagou_danye.py
import requests
from pymongo import MongoClient
client = MongoClient()
db =client.lagou
my_set = db.set
url ='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0'
payload = {
'first':'true',
'pn':'1',
'kd':'爬虫',
}
headers = {
'Cookie':'JSESSIONID=ABAAABAACDBABJB4AA31E6DE1A80C130853EDC931C19F75; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516969150; _ga=GA1.2.520286489.1516969151; _gid=GA1.2.995066888.1516969151; Hm_lvt_9d483e9e48ba1faa0dfceaf6333de846=1516969151; user_trace_token=20180128201234-85d19dc4-0424-11e8-9e08-525400f775ce; LGSID=20180128201234-85d19f33-0424-11e8-9e08-525400f775ce; LGUID=20180128201234-85d1a0ab-0424-11e8-9e08-525400f775ce; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=search_code; Hm_lpvt_9d483e9e48ba1faa0dfceaf6333de846=1516970898; X_HTTP_TOKEN=b7fef26cf8b80466ae215e9c4ccd1c26; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516970944; LGRID=20180128204227-b24113de-0428-11e8-abb7-5254005c3644; SEARCH_ID=9737e302a19b44dfb05d6cdf4aaab184',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'Referer':'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput=',
}
response = requests.post(url,data=payload,headers=headers)
#注意必须顶格写
my_set.insert(response.json()['content']['positionResult']['result'])
#存入mongo数据库
第二种方法,保存多页:
# post_lagou_duoye.py
import requests
from pymongo import MongoClient
import time
from fake_useragent import UserAgent
client = MongoClient()
db =client.lagou_job_info2 #建立一个数据库
my_set = db.lagou_job_info2 #建立数据库表
headers = {
'Cookie': 'JSESSIONID=ABAAABAACDBABJB4AA31E6DE1A80C130853EDC931C19F75; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516969150; _ga=GA1.2.520286489.1516969151; _gid=GA1.2.995066888.1516969151; Hm_lvt_9d483e9e48ba1faa0dfceaf6333de846=1516969151; user_trace_token=20180128201234-85d19dc4-0424-11e8-9e08-525400f775ce; LGSID=20180128201234-85d19f33-0424-11e8-9e08-525400f775ce; LGUID=20180128201234-85d1a0ab-0424-11e8-9e08-525400f775ce; index_location_city=%E5%85%A8%E5%9B%BD; TG-TRACK-CODE=search_code; Hm_lpvt_9d483e9e48ba1faa0dfceaf6333de846=1516970898; X_HTTP_TOKEN=b7fef26cf8b80466ae215e9c4ccd1c26; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1516970944; LGRID=20180128204227-b24113de-0428-11e8-abb7-5254005c3644; SEARCH_ID=9737e302a19b44dfb05d6cdf4aaab184',
# 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
# 后面使用了浏览器伪装,爬虫优化
'Referer': 'https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput=',
}
def get_job_info(page,kd):
for i in range(page):
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0'
payload = {
'first': 'true',
'pn': i+1,
# 这个pn就是pagenumber的页码的意思,这里不能从第0页开始,必须从第1页开始
'kd': kd,
# 传递第二个参数,可以爬取任意名称的
}
ua = UserAgent()
headers['User-Agent'] =ua.random
response = requests.post(url,data=payload,headers=headers)
#注意必须顶格写
if response.status_code == 200:
my_set.insert(response.json()['content']['positionResult']['result'])
#存入mongo数据库
else:
print('something wrong')
print('正在打印%s页' % str(i + 1))
time.sleep(3)
if __name__ == '__main__':
get_job_info(3,'爬虫')
#传递了两个参数,一个是页码,一个是搜索的关键字
print('ok')
#总共25页


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









