







 本文通过在单机版Hive上建立测试表,探讨了`count distinct`与`group by`在执行效率上的差异。在优化前,`count distinct`仅使用一个MR任务,通过map端去重减少IO;而`group by`则需两个MR任务,第一个MR的reduce输出不明,第二个MR进行求和操作。大数据量下,`count distinct`的性能瓶颈在于单个reduce计算,而转换后的SQL通过增加MR任务提高并行度。文章还附上了两种语句的执行计划以供分析。
本文通过在单机版Hive上建立测试表,探讨了`count distinct`与`group by`在执行效率上的差异。在优化前,`count distinct`仅使用一个MR任务,通过map端去重减少IO;而`group by`则需两个MR任务,第一个MR的reduce输出不明,第二个MR进行求和操作。大数据量下,`count distinct`的性能瓶颈在于单个reduce计算,而转换后的SQL通过增加MR任务提高并行度。文章还附上了两种语句的执行计划以供分析。
首先,用我本地的单机版hive建一张测试表,虽然不能模拟大数据量,但是足够说明问题了,准备数据如下:
-- count distinct测试
create table count_distinct_test(id int,name string);
insert into count_distinct_test values(1,'a'),(2,'a'),(3,'a'),(4,'b'),(5,'b'),(6,'c'),(7,'d'),(8,'e'),(9,'f'),(10,'g');
explain
select count(distinct(name)) from count_distinct_test;
explain
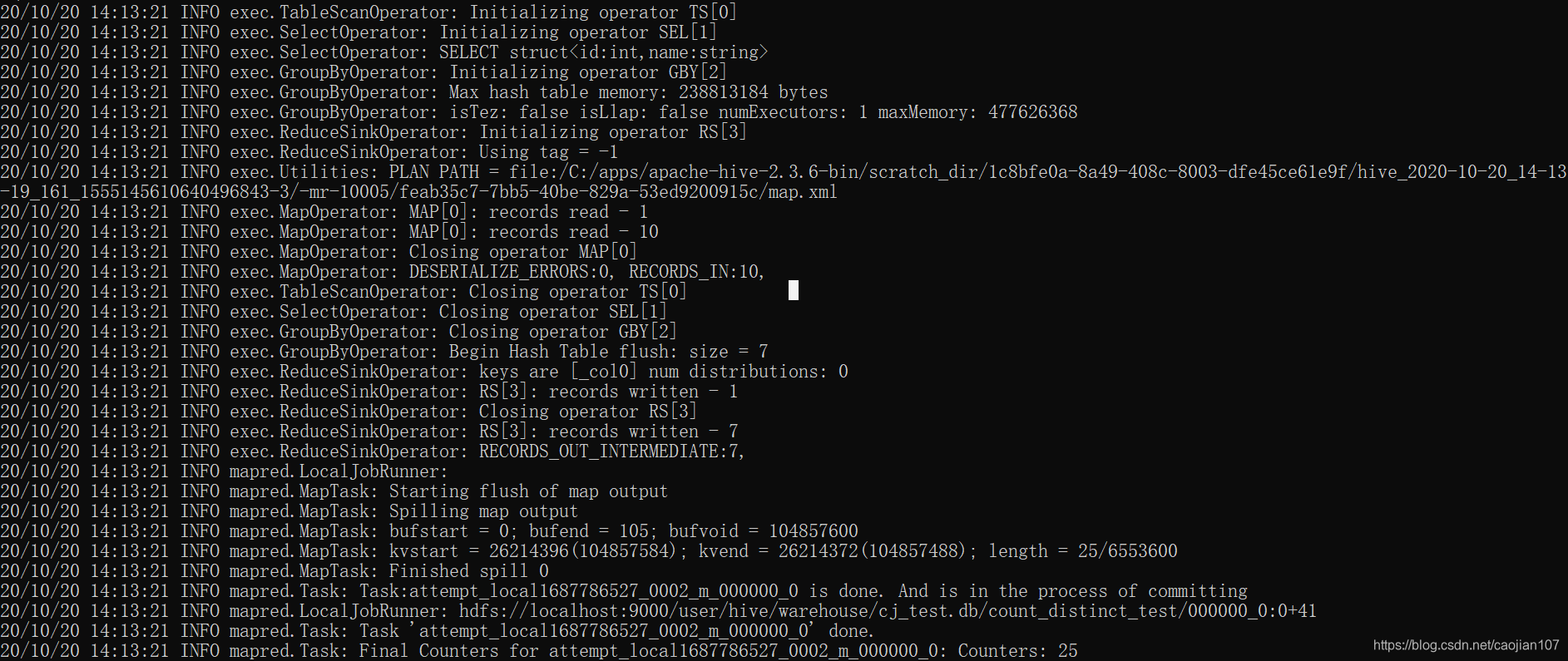
select count(1) from (select name from count_distinct_test group by name) x;首先,分别执行优化之前的count distinct和group by的语句,观察控制台打印的日志:
count distinct:

可以看到job数为1,整个任务只有1个mr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









