




 本文介绍了暗通道先验在去雾算法中的应用,通过归纳无雾图像的特性,提出利用暗通道图像的低强度值求取透射率和大气光值,进而实现自然的图像去雾。作者详细解释了暗通道概念、参数估计方法和图像重建过程,并提供了Python代码实现。
本文介绍了暗通道先验在去雾算法中的应用,通过归纳无雾图像的特性,提出利用暗通道图像的低强度值求取透射率和大气光值,进而实现自然的图像去雾。作者详细解释了暗通道概念、参数估计方法和图像重建过程,并提供了Python代码实现。
去雾算法都会依赖于很强的先验以及假设,并结合相应的物理模型,完成去雾过程。本文作者何凯明及其团队通过大量的无雾图像和有雾图像,归纳总结出无雾图像在其对应的暗通道图像上具有极低的强度值(趋近于0),并结合如下公式:
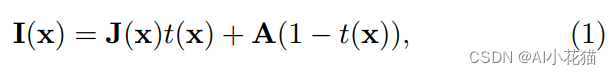
求出透射率参数以及全球大气光值,进而轻松的求取无雾图像J。
1、暗通道先验是什么?
暗通道先验是基于户外的的无雾图像总结归纳的,发现的一个普遍存在的现象就是:在大多数的非天空的图像块中,至少有一个图像通道的一些像素值是非常低且接近于0的。作者使用J_dark来表示暗通道图像,具体的计算公式如下所示:
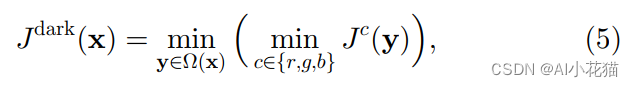
上述公式可以知道,对于无雾图像y,求取其三通道对应像素为的最小值,并使用一个固定大小(15*15)的块去取其中最小的值即为当前像素的暗通道值。
下图很明显的展示了有雾与无雾图像的暗通道图像的差异:对于有雾图像(不考虑天空),暗通道图像偏白,也就是其强度值比较高,而对于无雾图像,暗通道图像整体偏黑,也就是其强度值比较低。

按照暗通道的定义就可以很清楚的知道:

上述公式就是本文的精髓暗通道先验,就是这么一个普普通通的经验总结,但是没有人想到。
作者在发现这个先验以后,还去做了很多的验证工作,其中就包括:
(1)随机选取5000张landscape+cityscape场景的数据,在剪裁掉天空部分后,resize到最长边为500的图像,使用15*15的核区域去计算暗通道图像,统计其强度概率分布图、累积概率强度分布图、图像的强度分布图
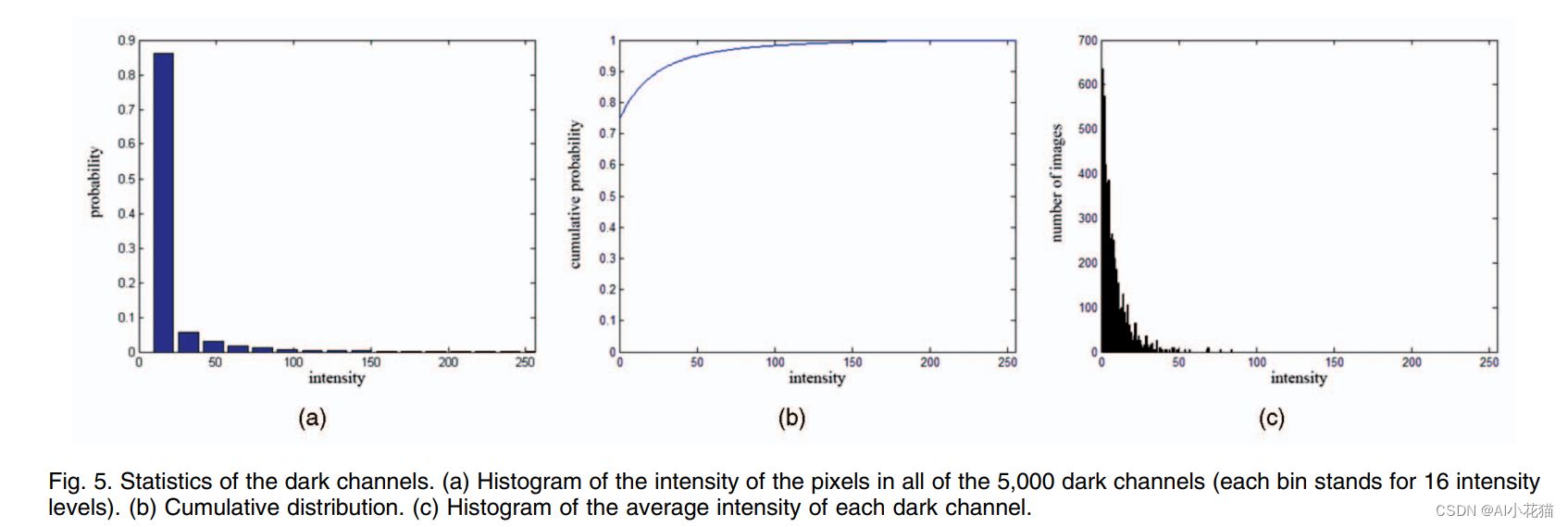
得出的结论是:
1、We can see that about 75 percent of the pixels in the dark channels have zero values, and the intensity of 90 percent of the pixels is below 25
2、most dark channels have very low average intensity, showing that only a small portion of outdoor haze-free images deviate from our prior
2、使用暗通道先验进行去雾
2.1 估计透射参数t
假设全球大气光值A是一个常量,利用公式(1)进行归一化操作可得:
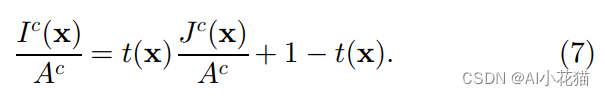
接着假设t在一个固定大小的块中是恒定值,并且在公式(7)的两边同时求取暗通道值:
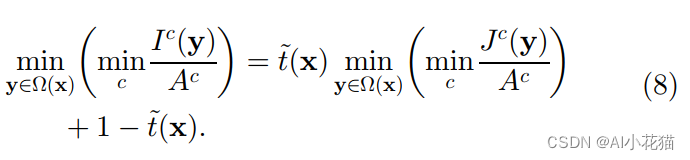
对于无雾图像来说J趋近于0的:
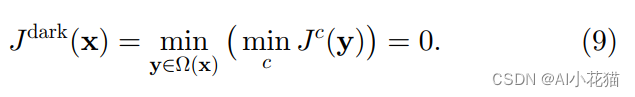
因此可以得出:
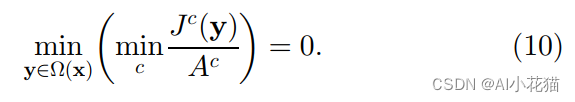
通过上述几个公式联合求解可得:
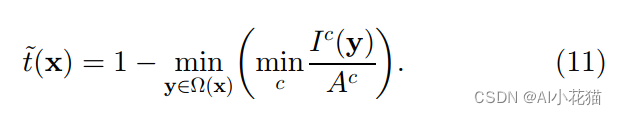
这里有一个特殊的点是:作者之前在讲解暗通道先验的时候排除了天空的干扰问题,但是通过公式(11)可以知道,对于有雾的天空而言,I和大气光参数A基本一致,因此:
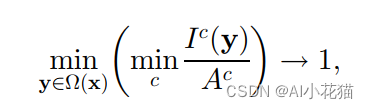
对于天空来说t->0,说明对于天空来说,因为距离无限远,反射率基本等于0是完全合理的。因此作者很优雅的处理了暗通道中的非天空数据,不用特意将天空数据裁剪完成后方才进行暗通道计算。
实际环境下,无论天气如何晴朗,都会存在一些颗粒和雾气,这种现象称为aerial perspective,如果我们直接移除雾气,会让去雾后的图像看起来非常不自然,因此需要保留一定的雾气,而这就导致反射率需要加一些补偿值:
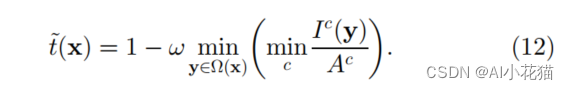
2.2 估计大气光值A
作者依托于Tan的理论:有雾图像中最亮的像素点是最不透明的,这主要针对是阴霾而没有阳光的天气,在这种情况下,大气光是照明的唯一来源,因此每个通道的颜色场景亮度为:

同时公式(1)可以改写为:
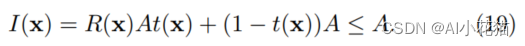 当图像中的像素处于无线远的位置时,最亮点的像素时最haze-opaque的,可近似为A。但是实际经验告诉我们不能忽略阳光,因此在考虑阳光照射的情况下,公式(18),(19)就需要改写为:
当图像中的像素处于无线远的位置时,最亮点的像素时最haze-opaque的,可近似为A。但是实际经验告诉我们不能忽略阳光,因此在考虑阳光照射的情况下,公式(18),(19)就需要改写为:

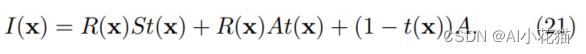
因此,图像中最亮的像素点可以比大气光值A大,可能会出现在白色的小汽车或者白色建筑物上
 依据暗通道先验,有雾图像的暗通道图表征其雾浓度,因此可以通过有雾图像的暗通道图来检测物浓度最大的区域,进而去提升大气光值的估计。
依据暗通道先验,有雾图像的暗通道图表征其雾浓度,因此可以通过有雾图像的暗通道图来检测物浓度最大的区域,进而去提升大气光值的估计。
最终的方法是:首先获取图像的暗通道图,接着获取暗通道图中top 0.1%的的最亮像素点,然后选取暗通道图最亮像素点所对应的原始图像强度值最大的值作为大气光值。
2.3 图像重建
在得到大气光值A以及相应的透射率参数t以后,可以利用22式进行求解并获取相应的无雾图像。
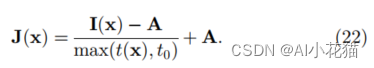
2.4 番外篇
由于透射参数t的求解比较粗暴,导致得到的t图比较粗糙,为了进行细腻处理,作者使用soft matting进行图像的refine,下图是对比:

Soft matting的效果明显比直接求出的t值好很多,但是有一个致命的缺点是速度比较慢,因此在2010年何凯明使用引导滤波(guided filter)进行加速。
3 代码实现
3.1暗通道图求解
暗通道图就是对图像的RGB三通道求取最小值,然后在用一个核去取最小值,当然简便的方法是构造一个核,直接使用腐蚀操作进行实现。
def cal_Dark_Channel(im, width = 15):
im_dark = np.min(im, axis = 2)
border = int((width - 1) / 2)
im_dark_1 = cv2.copyMakeBorder(im_dark, border, border, border, border, cv2.BORDER_DEFAULT)
res = np.zeros(np.shape(im_dark))
for i in range(res.shape[0]):
for j in range(res.shape[1]):
res[i][j] = np.min(im_dark_1[i: i + width, j: j + width])
return res
3.2 求解大气光值A
#计算A参数, im为暗通道图像, img为原图
def cal_Light_A(im, img):
s_dict = {}
for i in range(im.shape[0]):
for j in range(im.shape[1]):
s_dict[(i, j)] = im[i][j]
s_dict = sorted(s_dict.items(), key = lambda x: x[1])
A = np.zeros((3, ))
num = int(im.shape[0] * im.shape[1] * 0.001)
for i in range(len(s_dict) - 1, len(s_dict) - num - 1, -1):
X_Y = s_dict[i][0]
A = np.maximum(A, img[X_Y[0], X_Y[1], :])
return A
3.3 反射率参数t
def cal_trans(A, img, w = 0.95):
dark = cal_Dark_Channel(img / A)
t = np.maximum(1 - w * dark, 0)
return t
3.4 使用引导滤波进行优化t
def Guided_filtering(t, img_gray, width, sigma = 0.0001):
mean_I = np.zeros(np.shape(img_gray))
cv2.boxFilter(img_gray, -1, (width, width), mean_I, (-1, -1), True, cv2.BORDER_DEFAULT)
mean_t = np.zeros(np.shape(t))
cv2.boxFilter(t, -1, (width, width), mean_t, (-1, -1), True, cv2.BORDER_DEFAULT)
corr_I = np.zeros(np.shape(img_gray))
cv2.boxFilter(img_gray * img_gray, -1, (width, width), corr_I, (-1, -1), True, cv2.BORDER_DEFAULT)
corr_IT = np.zeros(np.shape(t))
cv2.boxFilter(img_gray * t, -1, (width, width), corr_IT, (-1, -1), True, cv2.BORDER_DEFAULT)
var_I = corr_I - mean_I * mean_I
cov_IT = corr_IT - mean_I * mean_t
a = cov_IT / (var_I + sigma)
b = mean_t - a * mean_I
mean_a = np.zeros(np.shape(a))
mean_b = np.zeros(np.shape(b))
cv2.boxFilter(a, -1, (width, width), mean_a, (-1, -1), True, cv2.BORDER_DEFAULT)
cv2.boxFilter(b, -1, (width, width), mean_b, (-1, -1), True, cv2.BORDER_DEFAULT)
return mean_a * img_gray + mean_b
3.5 图像恢复
def harz_Rec(A, img, t, t0 = 0.1):
img_o = np.zeros(np.shape(img))
img_o[:, :, 0] = (img[:, :, 0] - A[0]) / (np.maximum(t, t0)) + A[0]
img_o[:, :, 1] = (img[:, :, 1] - A[1]) / (np.maximum(t, t0)) + A[1]
img_o[:, :, 2] = (img[:, :, 2] - A[2]) / (np.maximum(t, t0)) + A[2]
return img_o
参考文献
走出寂静岭!暗通道先验的python实现
https://github.com/vaeahc/Dark_Channel_Prior/blob/master/Dark_Channel_Prior.py



















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言









